LlamaIndexのRAGsを試す
GPTsのLlamaIndex実装というイメージ
とりまdocker compose化した。以下で試せる。
自分がforkしたレポジトリからadd-dockerブランチをクローン
$ git clone https://github.com/kun432/rags -b add-docker
$ cd rags
.steramlit/secrets.tomlを作成して、OpenAIのAPIキーをセットする。
openai_key = "sk-XXXXXX"
docker composeでビルドして起動。
$ docker compose build
$ docker compose up
起動後にhttp://X.X.X.X:8501でアクセスすればOK。

Dockerfileとdocker-compose.ymlはこんな感じ。
FROM python:3.11-slim
RUN apt-get update &&\
apt-get install -y curl &&\
pip install --upgrade pip &&\
curl -sSL https://install.python-poetry.org -o install-poetry.py &&\
python install-poetry.py &&\
rm install-poetry.py
ENV PATH /root/.local/bin:$PATH
WORKDIR /app
COPY . /app/
RUN poetry install --with dev
EXPOSE 8501
CMD poetry run streamlit run 1_🏠_Home.py
version: '3.8'
name: rags
services:
app:
build:
context: .
dockerfile: Dockerfile
ports:
- "8501:8501"
volumes:
- ./.streamlit:/root/.streamlit
- ./cache/agents:/app/cache/agents
- ./cache/messages:/app/cache/messages
- ./data:/app/data
作成したエージェントの設定や会話履歴は./cache以下に作成されるようなので、ホスト上のディレクトリをボリュームとしてマウントするようにして、永続的に残るようにした。ただroot権限で動かしているので、ホストからはsudoしないと消せない。ユーザ作成してUID/GIDを用意するのが面倒だったので、とりま。
あと、RAG用のドキュメントを読み込ませる必要があるのだけど、2023/11/28時点では、
- ファイルアップロードはまだできない。
- ローカルパスかURLで指定する必要がある
- ローカルパスはコンテナ内でのパス
ということで、./dataを/app/dataとしてマウントするようにしてある。RAGsからみると/appが実行ディレクトリになるので、読み込ませたいドキュメントをdataディレクトリ以下において、RAGsの対話の中ではdata/xxxxみたいに相対参照させればよい。当初は
- ./data:/data
としていたけど、起動時の例文にI want to analyze this PDF file (data/invoices.pdf)みたいな書き方があるので、それに合わせるようにした次第。
今回は、fandomという海外のエンタメ専門wikiにある、海外ドラマ『フレンズ』のデータから、シーズン1の1〜10話の内容をテキスト化して日本語に翻訳したものをRAGのドキュメントとして使う。
こんな感じで置いてある。
$ ls data
01_001.md 01_003.md 01_005.md 01_007.md 01_009.md pg_essay.txt
01_002.md 01_004.md 01_006.md 01_008.md 01_010.md
コンテナ内では/app/data/01_001.mdもしくは./data/01_001.mdといった感じで参照できるはず。
ではやってみる。メニューがちょっとわかりにくいけど、左のメニューはこうらしい。
- HOME: エージェントを作成。"Create a new agent"が指定されていることを確認すること。
- RAG Config: 作成したエージェントの設定を変更
- Generated RAG Agent: 作成したエージェントを使用。
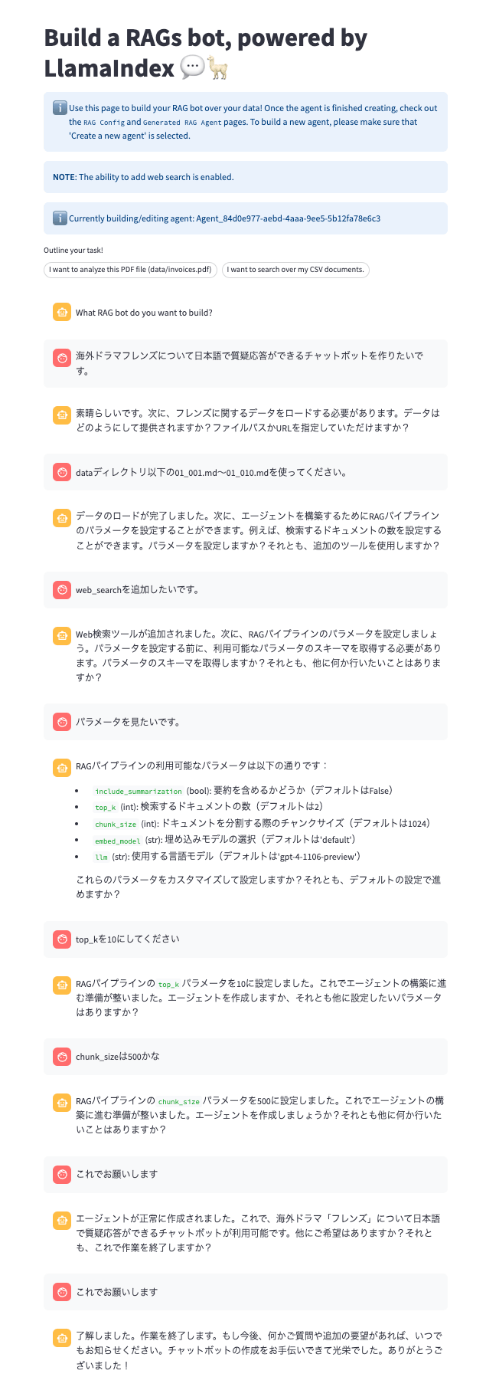
ということで、エージェントの作成はこんな感じで。

最初の質問でエージェントのタスク内容やドキュメントの指定からエージェントが作成されて、そのあとで細かいパラメータの設定、という流れっぽい。今回、たまたま追加のタスク(「日本語で」)をしたせいか、エージェントが一度作り直されたみたいだけど、左の「Agent_new_japanese_friends」ってのが作成されたエージェント。
これを選択して「RAG Config」をクリックする。

システムプロンプトと指定したドキュメント、パラメータが設定されているのがわかる(キャプチャはパスを修正する前のもの)。ドキュメントは後からは変更できないみたい。
設定されているシステムプロンプトはこんな感じ。
You are now operating as a chatbot designed to answer questions in Japanese about the TV show 'Friends' Season 1. When responding to queries, you must always utilize the tools and information provided to you. Do not provide answers based on general knowledge or external sources. Ensure that your responses are accurate and derived solely from the content available through the tools given. Remember to maintain the context of Season 1 of 'Friends' and respond in Japanese to all questions.
日本語訳
あなたは今、テレビ番組「フレンズ」シーズン1に関する日本語の質問に答えるためにデザインされたチャットボットとして操作している。質問に答えるときは、常に提供されたツールと情報を活用すること。一般的な知識や外部ソースに基づいた回答を提供しないこと。あなたの回答が正確で、与えられたツールから利用可能な内容のみから導き出されたものであることを確認すること。フレンズ」シーズン1の文脈を維持し、すべての質問に日本語で回答すること。
では実際に会話してみる。「Generated RAG Agent」をクリックして、こんな感じで。
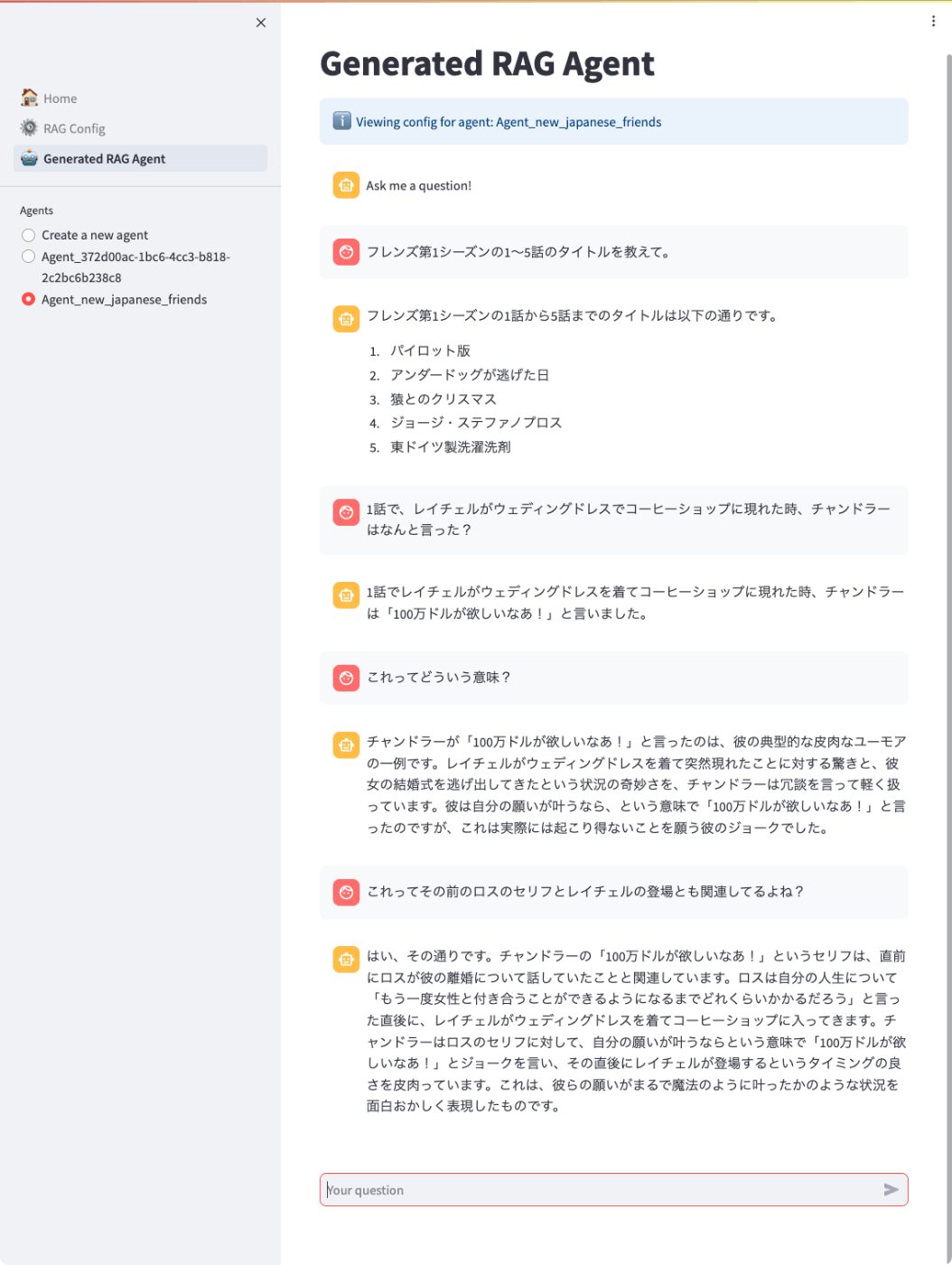
ちゃんとあってる。ちなみに1話の内容はこんな感じ
LangChainからはOpenGPTs、LlamaIndexからはRAGs、とGPTsクローンが出てきた。OpenGPTsは少し前にちょっと触っただけだけど、個人的な比較の印象。
- OpenGPTs
- 外部検索等のツールが色々揃っていて、LangSmithと最初から連携しているとか、LangChainのインテグレーションの豊富さが目立つ
- ただ自分が触った時点では、GPTsのような対話形式で設定が行えるというものではなく、Custom Instructionsっぽく自分で設定する感じだった。
- RAGs
- RAGsというだけあってRAGに特化している。
- GPTsの対話設定という感はこちらのほうが強い。
- URLでのドキュメント参照もできるけど、こっちは少し試してみた感じ、イマイチだった印象。ただコンテンツにもよりそうなので、あくまでも個人的な印象。
なんとなくお互いの得意な面が全面に出てる感じがして面白かった。もっと実装が進むのを期待。
あと、いくつかあるChatGPTクローンにもそのうち実装されてきそう。
PR出しておいた。
web検索が追加されたらしい
AI検索サービス"Metaphor"を使っている
mainを手元のブランチにマージしてみたけど、色々足りなかった。
まず、metaphorでAPIキーを取得しておく。回数制限はあるけど一応無料ではじめることができる。
.streamlit/secrets.tomlに以下を追加
metaphor_key = "XXXXXXXX"
あと、metaphorでweb_searchができるのはいいんだけど、パッケージがpyproject.tomlに追加されていない。
pyproject.tomlの[tool.poetry.dependencies]に以下を追加
metaphor-python = "0.1.23"
ビルドしなおし
$ docker compose build --no-cache
$ docker compose up
こんな感じでボットを作って、web_searchを有効にしておく。
どのツールを使っているかがわかるようになったみたいで、1回目はベクトル検索で出てこなかったのを、2回目はウェブ検索で参照できているのがわかる。
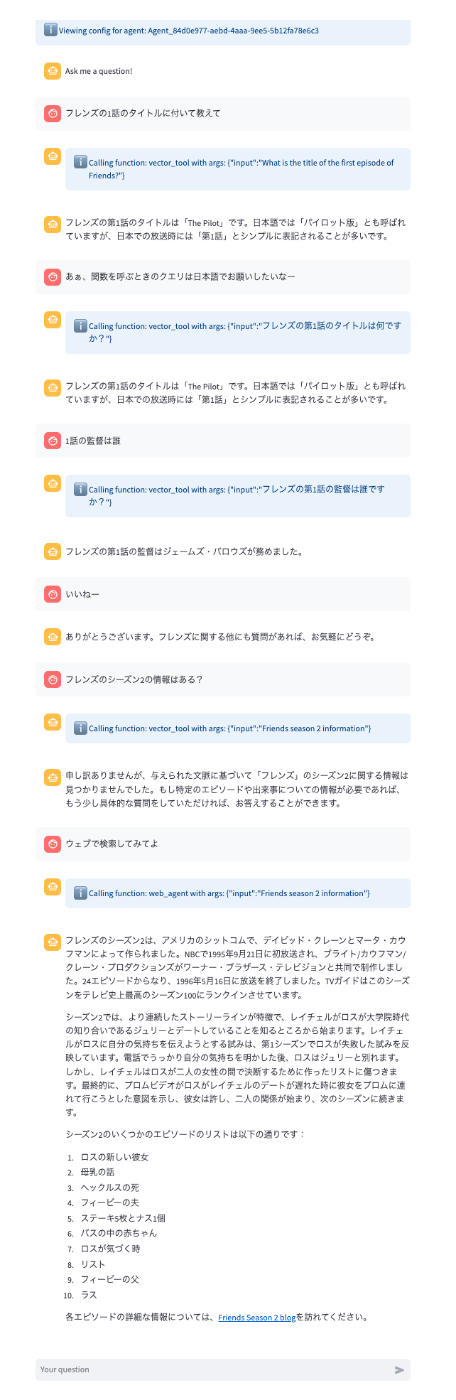
ここをエージェント的にシームレスにやってくれるといいんだけどな。
とりあえずPR、今のところなしのつぶて・・・もうクローズして手元で管理しょうかな。
クローズした。どうも過去のPRも取り込まれることなく、開発元で直接反映してるっぽい。そういうポリシーなのかもしれない、ただちょっと残念な感はある。
とりあえず自分のforkでブランチ育てていくことにする。