LaTeX・表・署名・チェックボックス等を含む文書からMarkdownを生成するモデル「nanonets/Nanonets-OCR-s」 を試す
ここで見かけた
モデル
nanonets/Nanonets-OCR-s
Nanonets-OCR-s は、従来のテキスト抽出をはるかに超える、強力で最先端のイメージからマークダウンへの OCR モデルです。インテリジェントなコンテンツ認識とセマンティックタグ付けにより、ドキュメントを構造化されたマークダウンに変換し、大規模言語モデル(LLM)による下流処理に最適です。
Nanonets-OCR-s は、複雑なドキュメントを簡単に処理するための機能が満載です:
- LaTeX方程式認識: 数学式や数式を適切にフォーマットされたLaTeX構文に自動的に変換します。インライン(
$...$)とディスプレイ($$...$$)の方程式を区別します。- インテリジェントな画像説明: 文書内の画像を構造化された
<img>タグで説明し、LLM処理に適した形式に変換します。ロゴ、チャート、グラフなど、さまざまな画像タイプを、内容、スタイル、文脈の詳細まで説明できます。- 署名検出と分離: テキスト内の署名を識別し、他のテキストから分離して
<signature>タグ内に出力します。これは、法的文書やビジネス文書の処理において重要です。- ウォーターマーク抽出: 文書内のウォーターマークテキストを検出し、
<watermark>タグ内に抽出します。- スマートチェックボックス処理: フォームのチェックボックスとラジオボタンを標準化された Unicode シンボル(
☐、☑、☒)に変換し、一貫性と信頼性の高い処理を実現します。- 複雑なテーブル抽出: 文書から複雑なテーブルを正確に抽出し、マークダウンと HTML テーブルの両形式に変換します。
詳細については、リリースブログをご確認ください。
Qwen2.5-VL-3B-Instructがベースになっているみたい。
公式ブログ。表などを含むいろいろな文書がどのように解析されたか?について書いてある。
Colaboratory L4で。
Flash Attentionをインストール
!pip install flash-attn --no-build-isolation
モデルカードに従ってモデルをロード。簡単に使えるヘルパー関数が定義されていて親切。
from PIL import Image
from transformers import AutoTokenizer, AutoProcessor, AutoModelForImageTextToText
model_path = "nanonets/Nanonets-OCR-s"
model = AutoModelForImageTextToText.from_pretrained(
model_path,
torch_dtype="auto",
device_map="auto",
attn_implementation="flash_attention_2"
)
model.eval()
tokenizer = AutoTokenizer.from_pretrained(model_path)
processor = AutoProcessor.from_pretrained(model_path)
def ocr_page_with_nanonets_s(image_path, model, processor, max_new_tokens=4096):
prompt = """Extract the text from the above document as if you were reading it naturally. Return the tables in html format. Return the equations in LaTeX representation. If there is an image in the document and image caption is not present, add a small description of the image inside the <img></img> tag; otherwise, add the image caption inside <img></img>. Watermarks should be wrapped in brackets. Ex: <watermark>OFFICIAL COPY</watermark>. Page numbers should be wrapped in brackets. Ex: <page_number>14</page_number> or <page_number>9/22</page_number>. Prefer using ☐ and ☑ for check boxes."""
image = Image.open(image_path)
messages = [
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": [
{"type": "image", "image": f"file://{image_path}"},
{"type": "text", "text": prompt},
]},
]
text = processor.apply_chat_template(messages, tokenize=False, add_generation_prompt=True)
inputs = processor(text=[text], images=[image], padding=True, return_tensors="pt")
inputs = inputs.to(model.device)
output_ids = model.generate(**inputs, max_new_tokens=max_new_tokens, do_sample=False)
generated_ids = [output_ids[len(input_ids):] for input_ids, output_ids in zip(inputs.input_ids, output_ids)]
output_text = processor.batch_decode(generated_ids, skip_special_tokens=True, clean_up_tokenization_spaces=True)
return output_text[0]
モデルロード時点でのVRAMは8GB程度
Fri Jun 13 10:22:31 2025
+-----------------------------------------------------------------------------------------+
| NVIDIA-SMI 550.54.15 Driver Version: 550.54.15 CUDA Version: 12.4 |
|-----------------------------------------+------------------------+----------------------+
| GPU Name Persistence-M | Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap | Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|=========================================+========================+======================|
| 0 NVIDIA L4 Off | 00000000:00:03.0 Off | 0 |
| N/A 50C P0 28W / 72W | 8017MiB / 23034MiB | 0% Default |
| | | N/A |
+-----------------------------------------+------------------------+----------------------+
では早速試してみる。
まず架空の請求書。

!wget https://storage.googleapis.com/zenn-user-upload/4697c3aef653-20250226.png -O invoice.png
result = ocr_page_with_nanonets_s("invoice.png", model, processor, max_new_tokens=15000)
print(result)
御請求書
請求書番号: INV-2024-0820
模範商事株式会社
之印
〒100-0001 東京都千代田区見本町1-1
電話: 03-1234-5678 FAX: 03-1234-5679
範例工業株式会社 御中
下記の通りご請求申し上げます。
<table>
<tr>
<td>項目</td>
<td>数量</td>
<td>単価</td>
<td>金額</td>
</tr>
<tr>
<td>特選和紙 (A4サイズ)</td>
<td>1000</td>
<td>¥50</td>
<td>¥50,000</td>
</tr>
<tr>
<td>高級墨 (松煙)</td>
<td>20</td>
<td>¥2,000</td>
<td>¥40,000</td>
</tr>
<tr>
<td>筆セット (各種)</td>
<td>50</td>
<td>¥1,000</td>
<td>¥50,000</td>
</tr>
</table>
小計: ¥140,000
消費税 (10%): ¥14,000
合計金額: ¥154,000
備考:
1. お支払いは請求書発行日より30日以内にお願いいたします。
2. 振込手数料は貴社負担でお願いいたします。
3. 本書に関するお問い合わせは下記担当者までご連絡ください。
担当: 営業部 見本 太郎
Qwen2.5-VLがベースみたいなので、日本語は普通に使えるみたい。
神戸市が公開している観光に関する統計・調査資料のうち、「令和5年度 神戸市観光動向調査結果について」のPDFを画像に変換して使用する。
PDFをダウンロード
!wget https://www.city.kobe.lg.jp/documents/15123/r5_doukou.pdf
PDFから画像の変換にはpdf2imageを使用する。まずpoppler-utilsをインストール
!apt update && apt install -y poppler-utils
pdf2imageをインストール
!pip install pdf2image
ではPDFを画像に変換。
import os
from pdf2image import convert_from_path
kobe_pdf = "r5_doukou.pdf"
kobe_output_dir = "kobe"
def convert_pdf_to_image(pdf_path, output_dir_path):
os.makedirs(output_dir_path, exist_ok=True)
images = convert_from_path(pdf_path)
for i, image in enumerate(images):
output_path = f"{output_dir_path}/page_{i + 1}.png"
image.save(output_path, "PNG")
print(f"Saved: {output_path}")
convert_pdf_to_image(kobe_pdf, kobe_output_dir)
こんな感じで保存される。
Saved: kobe/page_1.png
Saved: kobe/page_2.png
Saved: kobe/page_3.png
Saved: kobe/page_4.png
Saved: kobe/page_5.png
Saved: kobe/page_6.png
Saved: kobe/page_7.png
Saved: kobe/page_8.png
Saved: kobe/page_9.png
Saved: kobe/page_10.png
Saved: kobe/page_11.png
Saved: kobe/page_12.png
Saved: kobe/page_13.png
Saved: kobe/page_14.png
Saved: kobe/page_15.png
Saved: kobe/page_16.png
Saved: kobe/page_17.png
Saved: kobe/page_18.png
Saved: kobe/page_19.png
Saved: kobe/page_20.png
Saved: kobe/page_21.png
1ページ目と4ページ目をピックアップして試してみる。
1ページ目

result = ocr_page_with_nanonets_s("kobe/page_1.png", model, processor, max_new_tokens=15000)
print(result)
The following generation flags are not valid and may be ignored: ['temperature']. Set `TRANSFORMERS_VERBOSITY=info` for more details.
# 令和5年度 神戸市観光動向調査結果について
## 調査目的
本調査は、来神観光客の特質と神戸市内の観光動向を把握し、今後の観光行政の参考とすることを目的に実施。
## 調査方法
調査員が対面にてアンケート項目を聞き取りする形で実施。
## 調査日
① 令和5年 5月13日(土)・20日(土)※
② 令和5年 9月 9日(土)
③ 令和5年11月25日(土)/12月2日(土)※
④ 令和6年 2月10日(土)・17日(土)・24日/3月30日(土)※
※雨天等により、一部の調査地点については延期して実施。
## 調査地点
<table>
<thead>
<tr>
<th>地区</th>
<th>NO</th>
<th>調査地点</th>
<th>サンプル数</th>
</tr>
</thead>
<tbody>
<tr>
<td rowspan="2">北野</td>
<td>1</td>
<td>北野町広場</td>
<td>246</td>
</tr>
<tr>
<td>2</td>
<td>北野工房のまち</td>
<td>154</td>
</tr>
<tr>
<td rowspan="12">市街地</td>
<td>3</td>
<td>南京町広場</td>
<td>218</td>
</tr>
<tr>
<td>4</td>
<td>総合インフォメーションセンター</td>
<td>198</td>
</tr>
<tr>
<td>5</td>
<td>旧居留地</td>
<td>201</td>
</tr>
<tr>
<td>6</td>
<td>神戸布引ロープウェイハーブ園山麓駅</td>
<td>203</td>
</tr>
<tr>
<td>7</td>
<td>白鶴酒造資料館内</td>
<td>205</td>
</tr>
<tr>
<td>8</td>
<td>王子動物園内</td>
<td>235</td>
</tr>
<tr>
<td>9</td>
<td>県立美術館前</td>
<td>217</td>
</tr>
<tr>
<td>10</td>
<td>さんちか夢広場</td>
<td>208</td>
</tr>
<tr>
<td>11</td>
<td>神戸空港屋上階展望ロビー</td>
<td>212</td>
</tr>
<tr>
<td>12</td>
<td>I K E A神戸</td>
<td>192</td>
</tr>
<tr>
<td>13</td>
<td>能福寺(兵庫大仏)</td>
<td>147</td>
</tr>
<tr>
<td>14</td>
<td>兵庫津ミュージアム</td>
<td>204</td>
</tr>
<tr>
<td rowspan="4">神戸港</td>
<td>15</td>
<td>神戸海洋博物館前及び周辺</td>
<td>200</td>
</tr>
<tr>
<td>16</td>
<td>中突堤中央ターミナル周辺</td>
<td>208</td>
</tr>
<tr>
<td>17</td>
<td>u m i e モザイク</td>
<td>201</td>
</tr>
<tr>
<td>18</td>
<td>ハーバーランド総合インフォメーション前</td>
<td>213</td>
</tr>
<tr>
<td rowspan="4">六甲・摩耶</td>
<td>19</td>
<td>六甲天覧台</td>
<td>209</td>
</tr>
<tr>
<td>20</td>
<td>摩耶山掬星台広場</td>
<td>200</td>
</tr>
<tr>
<td>21</td>
<td>六甲山牧場内</td>
<td>215</td>
</tr>
<tr>
<td>22</td>
<td>六甲ガーデンテラス内</td>
<td>211</td>
</tr>
<tr>
<td rowspan="3">有馬</td>
<td>23</td>
<td>有馬温泉観光総合案内所前</td>
<td>214</td>
</tr>
<tr>
<td>24</td>
<td>金の湯前</td>
<td>216</td>
</tr>
<tr>
<td>25</td>
<td>六甲有馬ロープウェイ有馬温泉駅</td>
<td>232</td>
</tr>
<tr>
<td rowspan="2">須磨・舞子</td>
<td>26</td>
<td>須磨離宮公園</td>
<td>202</td>
</tr>
<tr>
<td>27</td>
<td>舞子公園(舞子海上プロムナード)</td>
<td>230</td>
</tr>
<tr>
<td rowspan="3">西北神</td>
<td>28</td>
<td>神戸ワイナリー(農業公園)</td>
<td>235</td>
</tr>
<tr>
<td>29</td>
<td>神戸フルーツ・フラワーパーク大沢園内</td>
<td>209</td>
</tr>
<tr>
<td>30</td>
<td>神戸三田プレミアム・アウトレット</td>
<td>215</td>
</tr>
<tr>
<td colspan="4">合計 6,250</td>
</tr>
</tbody>
</table>
表の読み取りとHTMLタグへの変換精度は非常に良いのでは?
4ページ目
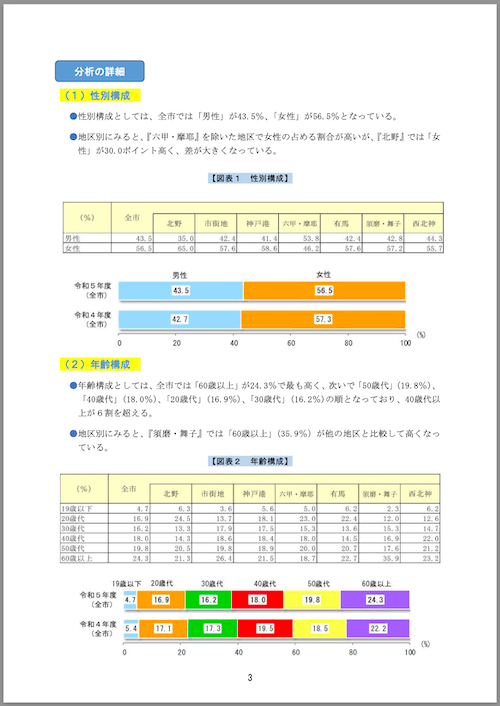
result = ocr_page_with_nanonets_s("kobe/page_4.png", model, processor, max_new_tokens=15000)
print(result)
分析の詳細
(1) 性別構成
●性別構成としては、全市では「男性」が43.5%、「女性」が56.5%となっている。
●地区別にみると、『六甲・摩耶』を除いた地区で女性の占める割合が高いが、『北野』では「女性」が30.0ポイント高く、差が大きくなっている。
【図表 1 性別構成】
<table>
<tr>
<td>(%)</td>
<td>全市</td>
<td>北野</td>
<td>市街地</td>
<td>神戸港</td>
<td>六甲・摩耶</td>
<td>有馬</td>
<td>須磨・舞子</td>
<td>西北神</td>
</tr>
<tr>
<td>男性</td>
<td>43.5</td>
<td>35.0</td>
<td>42.4</td>
<td>41.4</td>
<td>53.8</td>
<td>42.4</td>
<td>42.8</td>
<td>44.3</td>
</tr>
<tr>
<td>女性</td>
<td>56.5</td>
<td>65.0</td>
<td>57.6</td>
<td>58.6</td>
<td>46.2</td>
<td>57.6</td>
<td>57.2</td>
<td>55.7</td>
</tr>
</table>
令和5年度(全市)
男性:43.5
女性:56.5
令和4年度(全市)
男性:42.7
女性:57.3
(2) 年齢構成
●年齢構成としては、全市では「60歳以上」が24.3%で最も高く、次いで「50歳代」(19.8%)、「40歳代」(18.0%)、「20歳代」(16.9%)、「30歳代」(16.2%)の順となっており、40歳代以上が6割を超える。
●地区別にみると、『須磨・舞子』では「60歳以上」(35.9%)が他の地区と比較して高くなっている。
【図表 2 年齢構成】
<table>
<tr>
<td>(%)</td>
<td>全市</td>
<td>北野</td>
<td>市街地</td>
<td>神戸港</td>
<td>六甲・摩耶</td>
<td>有馬</td>
<td>須磨・舞子</td>
<td>西北神</td>
</tr>
<tr>
<td>19歳以下</td>
<td>4.7</td>
<td>6.3</td>
<td>3.6</td>
<td>5.6</td>
<td>5.0</td>
<td>6.2</td>
<td>2.3</td>
<td>6.2</td>
</tr>
<tr>
<td>20歳代</td>
<td>16.9</td>
<td>24.5</td>
<td>13.7</td>
<td>18.1</td>
<td>23.0</td>
<td>22.4</td>
<td>12.0</td>
<td>12.6</td>
</tr>
<tr>
<td>30歳代</td>
<td>16.2</td>
<td>13.3</td>
<td>17.9</td>
<td>17.5</td>
<td>15.3</td>
<td>13.6</td>
<td>15.3</td>
<td>14.7</td>
</tr>
<tr>
<td>40歳代</td>
<td>18.0</td>
<td>14.3</td>
<td>18.6</td>
<td>18.4</td>
<td>18.0</td>
<td>14.5</td>
<td>16.9</td>
<td>22.0</td>
</tr>
<tr>
<td>50歳代</td>
<td>19.8</td>
<td>20.5</td>
<td>19.8</td>
<td>18.9</td>
<td>20.0</td>
<td>20.7</td>
<td>17.6</td>
<td>21.2</td>
</tr>
<tr>
<td>60歳以上</td>
<td>24.3</td>
<td>21.3</td>
<td>26.4</td>
<td>21.5</td>
<td>18.7</td>
<td>22.7</td>
<td>35.9</td>
<td>23.2</td>
</tr>
</table>
19歳以下 20歳代 30歳代 40歳代 50歳代 60歳以上
令和5年度(全市) 4.7 16.9 16.2 18.0 19.8 24.3
令和4年度(全市) 5.4 17.1 17.3 19.5 18.5 22.2
<page_number>3</page_number>
グラフまでは流石にMarkdownなりHTMLなりにはできなかったみたいだけど、それでも文字は読み取ってる。
十分使えるレベルでは?公式のブログにできることが書いてあるのでこれを確認して、複雑な文書画像を食わせてみてどうなるか?を試してみるのをおすすめ。
ところでライセンスがApache-2.0なのだけども、Qwen2.5−VLベースなのでQwenのライセンスも継承するデュアルライセンスになるのではなかろうか?
Nanonets-OCR2が出た。