OpenAIのRealtime APIを試す
公式の記事
ドキュメント
公式のサンプル
参考)
参考記事を上に挙げているけど、当時からはすっかり時間が経ってしまっているので、あらためて公式のドキュメントを追いかけようと思う。
公式ドキュメント
Realtime API(ベータ版)
Realtime API を使用して、低遅延のマルチモーダル体験を構築しましょう。
OpenAI Realtime API は、音声から音声への会話体験やリアルタイム文字起こしなど、低遅延のマルチモーダル対話を実現します。
この API は GPT-4o や GPT-4o mini などのネイティブマルチモーダルモデルに対応しており、リアルタイムでのテキストおよび音声処理、関数呼び出し、音声生成などの機能を提供します。また、最新の文字起こしモデルである GPT-4o Transcribe および GPT-4o mini Transcribe にも対応しています。
Realtime API のはじめ方
Realtime API への接続方法は2つあります:
- WebRTC を使用する方法:クライアントサイドアプリケーション(例:Web アプリ)に最適です。
- WebSocket を使用する方法:サーバー間通信(例:バックエンドから、または電話を通じた音声エージェントの構築時など)に最適です。
以下の例やパートナー統合を通じて使い方を探るか、ご利用ケースに最も適した方法で Realtime API に接続する方法をご確認ください。
サンプルアプリケーション
以下のいずれかのサンプルアプリケーションをご覧いただくと、Realtime API の実際の動作を確認できます。
- Realtime コンソール
すぐに始めたい方は、Realtime コンソールのデモをダウンロードして設定してください。イベントの双方向の流れを確認し、その内容を検査できます。また、関数呼び出しを使ってカスタムロジックを実行する方法も学べます。- Realtime Solar System デモ
WebRTC 統合による Realtime API のデモで、関数呼び出しを通じて音声で太陽系をナビゲートします。- Twilio 統合デモ
Realtime API と Twilio を組み合わせて、AI 通話アシスタントを構築するデモです。- Realtime API Agents デモ
Realtime API 音声エージェント間の引き継ぎを、推論モデルの検証付きで示すデモです。パートナーインテグレーション
以下のパートナーインテグレーション例では、Realtime API をフロントエンドアプリケーションや電話関連の用途で使用しています。
- LiveKit 統合ガイド
LiveKit の WebRTC インフラストラクチャと Realtime API を組み合わせて使用する方法。- Twilio 統合ガイド
Twilio の強力な音声 API を活用して Realtime アプリケーションを構築する方法。- Agora 統合クイックスタート
Agora のリアルタイム音声通信機能と Realtime API を統合する方法。- Pipecat 統合ガイド
OpenAI の音声モデルと Pipecat オーケストレーションフレームワークを用いて音声エージェントを作成する方法。- クライアントサイドツール呼び出し
Cloudflare Workers を使って構築された、クライアントサイドでのツール呼び出しを実演するサンプルアプリケーション。YouTube のチュートリアルも併せてご覧ください。ユースケース
Realtime API の最も一般的なユースケースは、リアルタイムの音声から音声への会話体験を構築することです。これは音声エージェントや音声対応アプリケーションの構築に最適です。
Realtime API はまた、文字起こしやターン検出といった用途にも独立して使用可能です。クライアントは音声をストリーミングで送信し、音声が検出されたときに Realtime API はリアルタイムで文字起こしを生成します。
いずれのユースケースでも、組み込みの音声アクティビティ検出(VAD)によってユーザーの発話終了を自動検出できます。これにより、会話のターンをスムーズに処理したり、文字起こしをフレーズ単位で解析したりすることが可能になります。
これらのユースケースの詳細については、専用ガイドをご覧ください。
- Realtime Speech-to-Speech
Realtime API を使用して、ストリーミング音声から音声への会話を構築する方法を学びましょう。- Realtime Transcription
Realtime API を文字起こし専用の用途で使用する方法を学びましょう。
WebRTC
公式ドキュメント日本語訳
WebRTC での接続
WebRTC は、リアルタイムアプリケーションを構築するための強力な標準インターフェース群です。OpenAI Realtime API は、WebRTC ピア接続を通じてリアルタイムモデルへの接続をサポートしています。本ガイドに従って、Realtime API に WebRTC 接続を設定する方法を学んでください。
概要
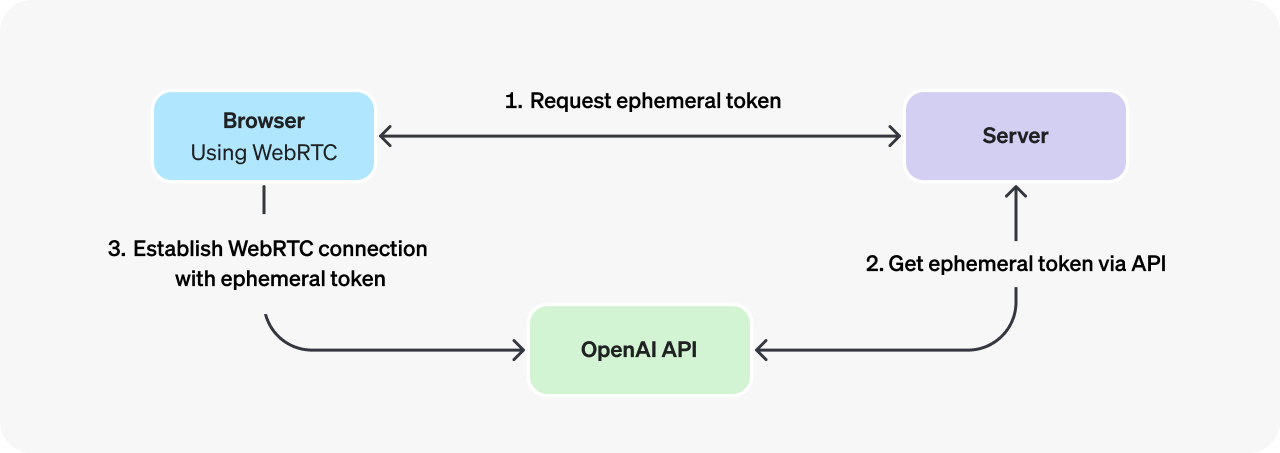
安全でないクライアント(たとえば Web ブラウザ)からネットワーク越しに Realtime モデルへ接続したい場合は、WebRTC 接続方式の使用を推奨します。WebRTC は接続状態の変動に対応しやすく、ユーザーの音声入力の取得や、モデルからのリモート音声ストリームの再生に便利な多数の API を提供します。
ブラウザから Realtime API に接続する際は、OpenAI REST API を通じて生成された一時的な API キー(エフェメラルキー)を使用する必要があります。Web ブラウザクライアントを前提とした WebRTC 接続の初期化手順は以下の通りです:
- ブラウザが開発者管理のサーバーにリクエストを送信し、一時的な API キーの発行を依頼する。
- 開発者のサーバーは標準の API キーを使用して、OpenAI REST API から一時的なキーを取得し、その新しいキーをブラウザに返す。なお、一時的なキーは発行から1分で失効します。
- ブラウザはこの一時的なキーを使用して、OpenAI Realtime API に対して WebRTC ピア接続としてセッションを認証する。
referred from https://platform.openai.com/docs/guides/realtime#connect-with-webrtc接続の詳細
WebRTC を使用した接続には、以下の情報が必要です:
項目 値 URL https://api.openai.com/v1/realtimeクエリパラメータ model
- 接続対象の Realtime モデル ID(例:gpt-4o-realtime-preview-2024-12-17)ヘッダー Authorization: Bearer EPHEMERAL_KEY
-EPHEMERAL_KEYは一時的な API トークンに置き換えてください(生成方法は後述)。以下は、WebRTC セッションを初期化する方法の例です(Realtime API イベントの送受信用データチャネルを含みます)。この例では、すでに一時的な API トークンを取得済みであることを前提としています(次節にサーバーコードの例があります)。
async function init() { // サーバーから一時キーを取得 - 下記のサーバーコード参照 const tokenResponse = await fetch("/session"); const data = await tokenResponse.json(); const EPHEMERAL_KEY = data.client_secret.value; // ピア接続を作成 const pc = new RTCPeerConnection(); // モデルからのリモート音声を再生するための設定 const audioEl = document.createElement("audio"); audioEl.autoplay = true; pc.ontrack = e => audioEl.srcObject = e.streams[0]; // ブラウザでマイク入力のローカル音声トラックを追加 const ms = await navigator.mediaDevices.getUserMedia({ audio: true }); pc.addTrack(ms.getTracks()[0]); // イベント送受信用データチャネルの設定 const dc = pc.createDataChannel("oai-events"); dc.addEventListener("message", (e) => { // Realtime サーバーイベントがここに届きます! console.log(e); }); // SDP を使用してセッション開始 const offer = await pc.createOffer(); await pc.setLocalDescription(offer); const baseUrl = "https://api.openai.com/v1/realtime"; const model = "gpt-4o-realtime-preview-2024-12-17"; const sdpResponse = await fetch(`${baseUrl}?model=${model}`, { method: "POST", body: offer.sdp, headers: { Authorization: `Bearer ${EPHEMERAL_KEY}`, "Content-Type": "application/sdp" }, }); const answer = { type: "answer", sdp: await sdpResponse.text(), }; await pc.setRemoteDescription(answer); } init();WebRTC API は、メディアストリームや入力デバイスを制御する豊富な機能を提供します。WebRTC 上にユーザーインターフェースを構築するためのより詳細なガイドは、MDN のドキュメントを参照してください。
一時トークンの生成
クライアント側で使用する一時トークンを生成するには、小さなサーバーサイドアプリケーションを構築する必要があります(もしくは既存のものに統合)。これにより OpenAI REST API へ一時キーをリクエストできます。このリクエストには、標準の API キーを使用してサーバー側で認証を行います。
以下は、REST API を使って一時的な API キーを発行する、シンプルな Node.js の express サーバーの例です:
import express from "express"; const app = express(); // 上記クライアントコードと連携するエンドポイント - 保護されたエンドポイントへの REST API リクエスト結果を返す app.get("/session", async (req, res) => { const r = await fetch("https://api.openai.com/v1/realtime/sessions", { method: "POST", headers: { "Authorization": `Bearer ${process.env.OPENAI_API_KEY}`, "Content-Type": "application/json", }, body: JSON.stringify({ model: "gpt-4o-realtime-preview-2024-12-17", voice: "verse", }), }); const data = await r.json(); // OpenAI REST API から取得した JSON を返す res.send(data); }); app.listen(3000);このようなサーバーエンドポイントは、HTTP リクエストを送受信できる任意のプラットフォーム上で構築できます。ただし、標準の OpenAI API キーはサーバー上のみで使用し、ブラウザでは使用しないよう注意してください。
イベントの送受信
WebRTC のデータチャネルを使用してイベントを送受信する方法については、Realtime Conversations ガイドをご覧ください。
WebSocket
公式ドキュメント日本語訳
WebSockets での接続
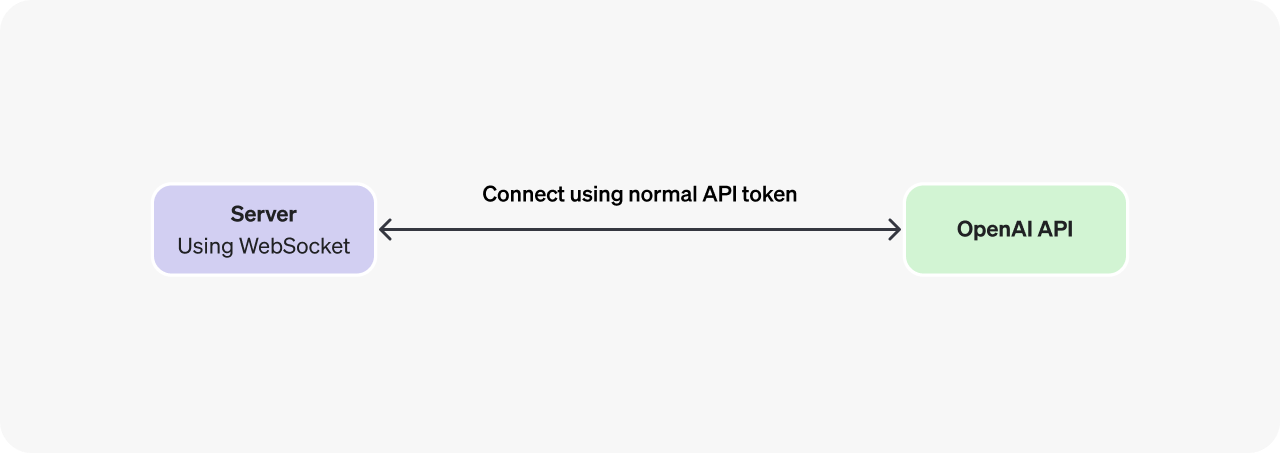
WebSocket はリアルタイムデータ転送のために広くサポートされている API であり、OpenAI Realtime API にサーバー間アプリケーションから接続する場合に最適な選択肢です。ブラウザやモバイルクライアントからの接続には、WebRTC の使用を推奨します。
概要
Realtime API とのサーバー間統合においては、バックエンドシステムが WebSocket を使用して Realtime API に直接接続します。この接続は、標準の API キーを用いて認証できます。標準トークンはセキュアなバックエンドサーバー上でのみ使用されるため、この方法は安全です。
referred from https://platform.openai.com/docs/guides/realtime#connect-with-websockets
接続の詳細:Speech-to-Speech
WebSocket を使用して接続するには、以下の接続情報が必要です:
項目 値 URL https://api.openai.com/v1/realtimeクエリパラメータ model
- 接続対象の Realtime モデル ID(例:gpt-4o-realtime-preview-2024-12-17)ヘッダー Authorization: Bearer YOUR_API_KEY
-YOUR_API_KEYには、サーバー上では標準の API キーを、不安定なクライアント環境では一時的なトークンを指定します(このようなクライアント用途には WebRTC の使用を推奨します)。OpenAI-Beta: realtime=v1
- このヘッダーはベータ期間中は必須です。以下はいくつかの例で、上記の接続情報を使用して Realtime API に対する WebSocket 接続を初期化する方法を示しています。
※訳注: Pythonのみ抜粋。Node.js・ブラウザについては公式ドキュメントを参照
websocket-client# この例では websocket-client ライブラリが必要です: # pip install websocket-client import os import json import websocket OPENAI_API_KEY = os.environ.get("OPENAI_API_KEY") url = "wss://api.openai.com/v1/realtime?model=gpt-4o-realtime-preview-2024-12-17" headers = [ "Authorization: Bearer " + OPENAI_API_KEY, "OpenAI-Beta: realtime=v1" ] def on_open(ws): print("サーバーに接続しました。") def on_message(ws, message): data = json.loads(message) print("イベントを受信しました:", json.dumps(data, indent=2)) ws = websocket.WebSocketApp( url, header=headers, on_open=on_open, on_message=on_message, ) ws.run_forever()イベントの送受信
WebSocket を通じてイベントを送受信する方法については、Realtime Conversations ガイドをご参照ください。
接続の詳細:Transcription
WebSocket を使用して接続するには、以下の接続情報が必要です:
項目 値 URL https://api.openai.com/v1/realtimeクエリパラメータ intent
接続の目的を指定します:transcriptionヘッダー Authorization: Bearer YOUR_API_KEY
-YOUR_API_KEYには、サーバー上では標準の API キーを、不安定なクライアント環境では一時的なトークンを指定します(このようなクライアント用途には WebRTC の使用を推奨します)。OpenAI-Beta: realtime=v1
- このヘッダーはベータ期間中は必須です。以下はいくつかの例で、上記の接続情報を使用して Realtime API に対する WebSocket 接続を初期化する方法を示しています。
※訳注: Pythonのみ抜粋。Node.js・ブラウザについては公式ドキュメントを参照
websocket-clientimport os import json import websocket OPENAI_API_KEY = os.environ.get("OPENAI_API_KEY") url = "wss://api.openai.com/v1/realtime?intent=transcription" headers = [ "Authorization: Bearer " + OPENAI_API_KEY, "OpenAI-Beta: realtime=v1" ] def on_open(ws): print("サーバーに接続しました。") def on_message(ws, message): data = json.loads(message) print("イベントを受信しました:", json.dumps(data, indent=2)) ws = websocket.WebSocketApp( url, header=headers, on_open=on_open, on_message=on_message, ) ws.run_forever()イベントの送受信
WebSocket を通じてイベントを送受信する方法については、Realtime transcription ガイドをご参照ください。
大まかに概要を確認したところで、どこから始めようかというところなのだけども、できればPythonで完結したい、と思うと、いい感じのサンプルがない
とりあえず「Realtime Conversation」を読む。
Realtime conversations (Beta)
公式ドキュメント日本語訳
Realtime conversations
Realtime speech-to-speech conversations の管理方法を学びます。
WebRTC または WebSocket のいずれかを通じて Realtime API に接続した後、gpt-4o-realtime-preview などの Realtime モデルを呼び出して音声対音声の会話を行うことができます。これを行うには、クライアントイベントを送信してアクションを開始し、サーバーイベントをリッスンして Realtime API によって実行されたアクションに応答する必要があります。
このガイドでは、オーディオおよびテキスト生成、ファンクション呼び出しなどのモデル機能を使用するために必要なイベントフローと、Realtime セッションの状態について考える方法を説明します。
Realtime speech-to-speechセッション
Realtime セッションは、モデルと接続されたクライアントとの状態を持つステートフルなインタラクションです。セッションの主要なコンポーネントは次のとおりです:
- Session オブジェクト: 使用するモデル、出力生成に用いる音声、その他の設定など、インタラクションのパラメータを制御します。
- Conversation: 現在のセッション中にユーザー入力項目と生成されたモデル出力項目を表します。
- Responses: 会話に追加される、モデルが生成した音声またはテキストの項目です。
これらすべてのコンポーネントが組み合わさって、Realtime セッションが構成されます。クライアントイベントを使用してセッションの状態を更新し、サーバーイベントをリッスンしてセッション内の状態変化に対応します。
referred from https://platform.openai.com/docs/guides/realtime-conversations#realtime-speech-to-speech-sessionsセッションのライフサイクルイベント
WebRTC または WebSockets のいずれかを介してセッションを開始すると、サーバーはセッションが準備完了であることを示す
session.createdイベントを送信します。クライアント側では、session.updateイベントを使用して現在のセッション構成を更新できます。ほとんどのセッションプロパティはいつでも更新可能ですが、セッション中にモデルが一度でも音声で応答した後は、オーディオ出力に使用されるvoiceは更新できません。Realtime セッションの最大持続時間は 30 分 です。次の例は、
session.updateクライアントイベントでセッションを更新する方法を示しています。クライアントイベントをこれらのチャネル経由で送信する方法の詳細については、WebRTC または WebSocket ガイドを参照してください。セッションで使用するシステム指示を更新する(Python)event = { "type": "session.update", "session": { "instructions": "回答に「湿気」という言葉は決して使用しないでください!" } } ws.send(json.dumps(event))セッションが更新されると、サーバーは新しいセッション状態を含む
session.updatedイベントを発行します。
関連するクライアントイベント 関連するサーバイベント session.updatesession.createdsession.updatedテキストの入力と出力
Realtime モデルでテキストを生成するには、現在の会話にテキスト入力を追加し、モデルに応答を生成させ、モデルの応答進捗を示すサーバー送信イベントをリッスンします。テキスト生成のためには、
textモダリティを使うようにセッションを設定する必要があります (これはデフォルトで有効です)。
conversation.item.createクライアントイベントを使用して、新しいテキスト会話項目を作成します。これは、REST API の Chat Completions におけるユーザーメッセージ(プロンプト)の送信 と似ています。ユーザー入力で会話項目を作成する(Python)event = { "type": "conversation.item.create", "item": { "type": "message", "role": "user", "content": [ { "type": "input_text", "text": "プリンスがリリースしたアルバムで一番売れたのはどれ?", } ] } } ws.send(json.dumps(event))ユーザーメッセージを会話に追加した後、
response.createイベントを送信して、モデルからの応答を開始します。現在のセッションでオーディオとテキストの両方が有効になっている場合、モデルはオーディオとテキストの両方のコンテンツで応答します。テキストのみを生成したい場合は、以下のようにresponse.createクライアントイベント送信時に指定できます。テキストのみの応答を生成する(python)event = { "type": "response.create", "response": { "modalities": [ "text" ] } } ws.send(json.dumps(event))応答が完全に完了すると、サーバーはモデルによって生成された完全なテキストを含む
response.doneイベントを発行します。以下に示すように。最終結果を見るために response.done をリッスンする(Python)def on_message(ws, message): server_event = json.loads(message) if server_event.type == "response.done": print(server_event.response.output[0])モデルの応答が生成される間、サーバーはプロセス中にいくつかのライフサイクルイベントを発行します。例えば
response.text.deltaなどのイベントをリッスンすることで、応答生成中にリアルタイムのフィードバックをユーザーに提供できます。サーバーが発行するイベントの完全なリストは、関連サーバーイベントの項目に、概ね発行される順序とともに記載されています。これには、テキスト生成のためのクライアント側イベントも含まれています。オーディオの入力と出力
Realtime API の最も強力な機能の 1 つは、中間のテキスト読み上げや文字起こしのステップを介さずに、モデルとの音声対音声のインタラクションを可能にすることです。これにより、音声インターフェースの待ち時間が短縮され、音声入力のトーンや抑揚に関するデータをモデルに多く提供することができます。
音声オプション
Realtime セッションは、オーディオ出力を生成する際にいくつかの組み込み音声のうちの 1 つを使用するように構成できます。セッションの作成時(または
response.create時)にvoiceを設定して、モデルの音声の出力方法を制御できます。現在の音声オプションは、alloy、ash、ballad、coral、echo、sage、shimmer、およびverseです。セッション中にモデルが音声を発した後は、voiceは変更できません。WebRTC を使用したオーディオ処理
Realtime API に WebRTC を使用して接続している場合、Realtime API はクライアントへの ピア接続 として機能します。モデルからのオーディオ出力は、クライアントに リモートメディアストリーム として届けられます。モデルへのオーディオ入力は、オーディオデバイス(
getUserMedia)を使用して収集され、メディアストリームはピア接続にトラックとして追加されます。WebRTC 接続ガイド のサンプルコードは、ブラウザ API を使用してローカルおよびリモートオーディオの両方を構成する基本的な例を示しています:
// ピア接続を作成 const pc = new RTCPeerConnection(); // モデルからのリモートオーディオを再生するための設定 const audioEl = document.createElement("audio"); audioEl.autoplay = true; pc.ontrack = e => audioEl.srcObject = e.streams[0]; // ブラウザ内のマイク入力用のローカルオーディオトラックを追加 const ms = await navigator.mediaDevices.getUserMedia({ audio: true }); pc.addTrack(ms.getTracks()[0]);上記のスニペットは、Realtime API との簡単なインタラクションを可能にしますが、他にも多くのことが可能です。さまざまな種類のユーザーインターフェースの例については、WebRTC サンプル リポジトリを参照してください。これらのサンプルのライブデモは こちら でも確認できます。
ブラウザで メディアキャプチャとストリーム を使用すると、マイクのミュートやミュート解除、入力デバイスの選択などが可能になります。
WebRTC におけるクライアントおよびサーバーイベント
デフォルトでは、WebRTC クライアントはオーディオ入力を送信する前に Realtime API に対してクライアントイベントを送信する必要はありません。ローカルオーディオトラックがピア接続に追加されると、ユーザーはすぐに話し始めることができます!
しかし、WebRTC クライアントは、ピア接続を介してクライアントとサーバー間でオーディオが行き来する際に、サーバー送信のライフサイクルイベントをいくつか受信します。例としては:
- ローカルメディアトラックで入力が送信されると、サーバーから
input_audio_buffer.speech_startedイベントが送信されます。- ローカルオーディオ入力が停止すると、
input_audio_buffer.speech_stoppedイベントが送信されます。- 進行中の音声文字起こしに対するデルタイベントが送信されます。
- モデルが文字起こしを完了して応答の送信が終了すると、
response.doneイベントが送信されます。WebRTC API を操作してメディアストリームを制御することで、必要なすべてのコントロールを得ることができます。ただし、場合によっては、より細かいオーディオ入力の処理のために、より低レベルのインターフェースを使用する必要があるかもしれません。詳細と、細かいオーディオ入力処理に必要なイベント一覧については、以下の WebSockets セクションを参照してください。
WebSockets を使用したオーディオ処理
WebSocket を介してオーディオを送受信する場合、クライアントからメディアを送信し、サーバーからメディアを受信するために、やや多くの作業が必要になります。以下の表は、WebSocket セッション中にオーディオを送受信するために必要なイベントのフローを、ライフサイクル順に示しています(一部のイベント(例えば
deltaイベント)は同時に発生する可能性があります)。
ライクサイクルのステージ クライアントイベント サーバイベント セッションの初期化 session.updatesession.createdsession.updatedユーザのオーディオ入力 conversation.item.create
(音声メッセージ全体を送信)input_audio_buffer.append
(音声をチャンク単位でストリーミング)input_audio_buffer.commit
(VAD が無効の場合に使用)response.create
(VAD が無効の場合に使用)input_audio_buffer.speech_startedinput_audio_buffer.speech_stoppedinput_audio_buffer.committedサーバのオーディオ出力 input_audio_buffer.clear
(VAD が無効の場合に使用)conversation.item.createdresponse.createdresponse.output_item.createdresponse.content_part.addedresponse.audio.deltaresponse.audio_transcript.deltaresponse.text.deltaresponse.audio.doneresponse.audio_transcript.doneresponse.text.doneresponse.content_part.doneresponse.output_item.doneresponse.donerate_limits.updatedサーバーへのオーディオ入力のストリーミング
サーバーへオーディオ入力をストリーミングするには、
input_audio_buffer.appendクライアントイベントを使用します。このイベントでは、ソケットを介して Realtime API に Base64 エンコードされた音声バイトのチャンク を送信する必要があります。各チャンクのサイズは 15 MB を超えてはいけません。入力チャンクのフォーマットは、セッション全体または各応答ごとに設定できます。
- セッション:
session.updateのsession.input_audio_format- 応答:
response.createのresponse.input_audio_format会話に音声入力バイトを追加する
会話に音声入力バイトを追加する(Python)import base64 import json import struct import soundfile as sf from websocket import create_connection # ... websocket-client を ws という名前で作成 ... def float_to_16bit_pcm(float32_array): clipped = [max(-1.0, min(1.0, x)) for x in float32_array] pcm16 = b''.join(struct.pack('<h', int(x * 32767)) for x in clipped) return pcm16 def base64_encode_audio(float32_array): pcm_bytes = float_to_16bit_pcm(float32_array) encoded = base64.b64encode(pcm_bytes).decode('ascii') return encoded files = [ './path/to/sample1.wav', './path/to/sample2.wav', './path/to/sample3.wav' ] for filename in files: data, samplerate = sf.read(filename, dtype='float32') channel_data = data[:, 0] if data.ndim > 1 else data base64_chunk = base64_encode_audio(channel_data) # クライアントイベントを送信 event = { "type": "input_audio_buffer.append", "audio": base64_chunk } ws.send(json.dumps(event))フルオーディオメッセージの送信
フルオーディオ録音の会話メッセージを作成することも可能です。
conversation.item.createクライアントイベントを使用して、input_audioコンテンツを持つメッセージを作成してください。フルオーディオ入力の会話項目を作成する(Python)fullAudio = "<音声バイトをbase64エンコードした文字列>" event = { "type": "conversation.item.create", "item": { "type": "message", "role": "user", "content": [ { "type": "input_audio", "audio": fullAudio, } ], }, } ws.send(json.dumps(event))WebSocket からのオーディオ出力の取り扱い
クライアントデバイス(例えばウェブブラウザ)で出力音声を再生するには、WebSockets よりも WebRTC の使用を推奨します。 WebRTC は、ネットワーク状況が不安定な中でもクライアントデバイスへのメディア送信がより堅牢です。
しかし、サーバー間のアプリケーションで WebSocket を使用してオーディオ出力を取り扱う場合、モデルから送信される Base64 エンコードされたオーディオデータのチャンクを含む
response.audio.deltaイベントをリッスンする必要があります。これらのチャンクをバッファに蓄積してファイルに書き出すか、または Twilio を用いた電話通話 のように即時に別のソースへストリーミングする必要があります。
response.audio.doneおよびresponse.doneイベント自体にはオーディオデータは含まれておらず、オーディオコンテンツの文字起こしのみが含まれることに注意してください。実際のバイトデータを取得するには、response.audio.deltaイベントをリッスンする必要があります。出力チャンクのフォーマットは、セッション全体または各応答ごとに設定できます。
- セッション:
session.updateのsession.output_audio_format- 応答:
response.createのresponse.output_audio_formatresponse.audio.delta イベントをリッスンする(Python)def on_message(ws, message): server_event = json.loads(message) if server_event.type == "response.audio.delta": # Base64 エンコードされたオーディオチャンクにアクセス: # print(server_event.delta)音声アクティビティ検出
デフォルトでは、Realtime セッションでは 音声アクティビティ検出 (VAD) が有効になっており、API はユーザーがいつ話し始め、いつ話し終えたかを判断して自動的に応答します。
VAD の設定方法の詳細については、音声アクティビティ検出 ガイドを参照してください。
VAD の無効化
session.updateクライアントイベントを使用してturn_detectionをnullに設定することで、VAD を無効化することができます。これは、プッシュ・トゥ・トーク インターフェースのように、オーディオ入力を細かく制御したい場合に有用です。VAD が無効の場合、クライアントは音声応答をトリガーするために、追加のクライアントイベントを手動で発行する必要があります:
- 新しいユーザー入力項目を会話に作成するために、
input_audio_buffer.commitを手動で送信する。- モデルからの音声応答をトリガーするために、
response.createを手動で送信する。- 新たなユーザー入力を開始する前に、
input_audio_buffer.clearを送信する。VAD は維持しつつ自動応答を無効にする
VAD モードを有効のまま、応答生成のタイミングを手動で制御したい場合は、
session.updateクライアントイベントでturn_detection.interrupt_responseおよびturn_detection.create_responseをfalseに設定できます。これにより、VAD のすべての動作は維持しつつも、新しい応答の自動生成が行われなくなります。クライアントはresponse.createイベントでこれらを手動でトリガーすることが可能になります。これは、モデレーション、入力検証、または RAG パターンなど、多少の待ち時間を犠牲にしてでも入力を制御したい場合に有用です。

上の続き
デフォルトの会話外で応答を生成する
デフォルトでは、セッション中に生成されたすべての応答はセッションの会話状態(「デフォルト会話」)に追加されます。しかし、セッションのデフォルト会話の文脈外でモデル応答を生成したい、または複数の応答を同時に生成したい場合もあります。また、モデルが応答生成時に考慮する会話項目をより細かく制御したい場合(例:直近の N ターンのみなど)もあるでしょう。
デフォルトの会話状態に追加されない「バンド外」応答を生成するには、
response.createクライアントイベントでresponse.conversationフィールドに文字列noneを設定します。バンド外の応答を作成する際は、どのサーバー送信イベントがこの応答に関連するかを識別する手段も必要になるでしょう。クライアント送信イベントに対して、応答を識別するための
metadataを提供できます。バンド外のモデル応答を作成する(Python)prompt = """ これまでの会話を分析します。 サポートに関連する内容であれば「support」と出力します。 営業に関連する内容であれば「sales」と出力します。 """ event = { "type": "response.create", "response": { # "none" を設定すると、応答がバンド外であることを示し、 # デフォルトの会話に追加されなくなります。 "conversation": "none", # モデルから返される応答を識別するための metadata を設定 "metadata": { "topic": "classification" }, # その他の利用可能な応答フィールドを設定 "modalities": [ "text" ], "instructions": prompt, }, } ws.send(json.dumps(event))これで、
response.doneサーバーイベントをリッスンする際に、バンド外応答の結果を識別することができます。カスタムコンテキストでの応答生成
モデルが応答生成に使用するコンテキストを、デフォルト/現在の会話の外でカスタムコンテキストとして構築することもできます。これは、
response.createクライアントイベントのinput配列を使用して行います。新しい入力を使用するか、既存の会話内の入力項目を ID で参照することができます。カスタムコンテキストでのバンド外モデル応答をリッスンする(Python)event = { "type": "response.create", "response": { "conversation": "none", "metadata": { "topic": "pizza" }, "modalities": [ "text" ], # このリクエストに適したコンテキストを持つカスタム入力配列を作成 "input": [ # 既存の会話項目を含める可能性も: { "type": "item_reference", "id": "some_conversation_item_id" }, # 新しい内容も含める { "type": "message", "role": "user", "content": [ { "type": "input_text", "text": "パイナップルをピザにのせても大丈夫ですか?", } ], } ], }, } ws.send(json.dumps(event))コンテキストなしでの応答生成
既存のすべての指示およびコンテキストを無視して、デフォルトの会話に応答を挿入することもできます。その場合は、
inputを空の配列に設定します。デフォルトの会話にコンテキストなしのモデル応答を挿入する(Python)prompt = """ 次の言葉を正確に言ってください。 私は小さなティーポット、背が低くてずんぐりしています! これが私の持ち手、これが注ぎ口です! """ event = { "type": "response.create", "response": { # 空の入力配列により、これまでのすべてのコンテキストが削除される "input": [], "instructions": prompt, }, } ws.send(json.dumps(event))Function calling
Realtime モデルは Function calling もサポートしており、これによりモデルの機能を拡張するためにカスタムコードを実行することが可能になります。大まかな流れは次の通りです:
- セッションの更新 または 応答の作成 の際に、モデルが呼び出すことのできる利用可能な関数のリストを指定できます。
- モデルが入力を処理する際、関数呼び出しを行うべきだと判断すると、関数呼び出しの引数を表す項目を会話に追加します。
- クライアントが関数呼び出しの引数を含む会話項目を検出すると、その引数を使用してカスタムコードを実行します。
- カスタムコードが実行されると、クライアントは関数呼び出しの出力を含む新しい会話項目を作成し、モデルに応答を依頼します。
以下は、ユーザーに今日の星占いを提供する呼び出し可能な関数を追加することで、この仕組みがどのように機能するかを実例で示します。送信する必要があるクライアントイベントオブジェクトの形状と、サーバーが順次発行するイベントの例を示します。
呼び出し可能な関数の構成
まず、ユーザー入力に基づいてモデルが呼び出すことのできる関数の選択肢をモデルに提供する必要があります。利用可能な関数は、セッションレベルまたは個々の応答レベルで構成できます。
- セッション:
session.updateにおけるsession.toolsプロパティ- 応答:
response.createにおけるresponse.toolsプロパティ次に、単一の引数(星座)を受け取り、その星座の今日の星占いを生成する horoscope 関数を構成するための、
session.updateのクライアントイベントペイロードの例を示します:{ "type": "session.update", "session": { "tools": [ { "type": "function", "name": "generate_horoscope", "description": "与えられた星座から今日の星占いを返す", "parameters": { "type": "object", "properties": { "sign": { "type": "string", "description": "占いたい星座", "enum": [ "Aries", "Taurus", "Gemini", "Cancer", "Leo", "Virgo", "Libra", "Scorpio", "Sagittarius", "Capricorn", "Aquarius", "Pisces" ] } }, "required": ["sign"] } } ], "tool_choice": "auto", } }関数とパラメーターの
descriptionフィールドは、モデルが関数呼び出しを行うかどうか、またどのデータを各パラメーターに含めるかを判断するのに役立ちます。モデルがユーザーの星占い要求を受け取ると、この関数をsignパラメーター付きで呼び出します。モデルが関数呼び出しを行いたいタイミングの検出
モデルへの入力に基づいて、モデルは最適な応答を生成するために関数呼び出しを行うことを決定する場合があります。たとえば、アプリケーションが以下の会話項目を追加し、応答生成を試みたとします:
{ "type": "conversation.item.create", "item": { "type": "message", "role": "user", "content": [ { "type": "input_text", "text": "私の今日の運勢はどう?水瓶座です。" } ] } }それに続いて、応答を生成するためのクライアントイベントを送信します:
{ "type": "response.create" }モデルは、テキストまたはオーディオの応答を直ちに返すのではなく、関数呼び出しに必要な引数を含む応答を生成します。開発者は
response.function_call_arguments.deltaサーバーイベントをリッスンすることで、関数呼び出し引数のリアルタイム更新を確認できますが、response.doneでも必要な完全なデータが得られます。{ "type": "response.done", "event_id": "event_AeqLA8iR6FK20L4XZs2P6", "response": { "object": "realtime.response", "id": "resp_AeqL8XwMUOri9OhcQJIu9", "status": "completed", "status_details": null, "output": [ { "object": "realtime.item", "id": "item_AeqL8gmRWDn9bIsUM2T35", "type": "function_call", "status": "completed", "name": "generate_horoscope", "call_id": "call_sHlR7iaFwQ2YQOqm", "arguments": "{\"sign\":\"Aquarius\"}" } ], "usage": { "total_tokens": 541, "input_tokens": 521, "output_tokens": 20, "input_token_details": { "text_tokens": 292, "audio_tokens": 229, "cached_tokens": 0, "cached_tokens_details": { "text_tokens": 0, "audio_tokens": 0 } }, "output_token_details": { "text_tokens": 20, "audio_tokens": 0 } }, "metadata": null } }上記のサーバーが発行する JSON から、モデルがカスタム関数呼び出しを行いたいと判断したことが検出できます:
プロパティ Function Callingの目的 response.output[0].typefunction_callに設定されている場合、この応答には指定された関数呼び出しの引数が含まれることを示します。response.output[0].name呼び出すように構成された関数の名前。ここでは generate_horoscopeです。response.output[0].arguments関数に渡す引数を含む JSON 文字列。ここでは "{\"sign\":\"Aquarius\"}"です。response.output[0].call_idこの関数呼び出しに対してシステムが生成した ID。モデルに関数呼び出し結果を返す際に必要です。 これらの情報に基づいて、アプリケーション内でコードを実行して星占いを生成し、その情報をモデルに返すことで、応答生成を続けることができます。
モデルに関数呼び出しの結果を提供する
モデルから関数呼び出しの引数を含む応答を受け取ったら、アプリケーション側でその引数に基づいた処理を実行し、関数呼び出しの結果を生成するコードを実行します。これには、外部 API との連携やデータベースへのアクセスなど、何でも実行可能です。
カスタムコードの実行が完了したら、
conversation.item.createクライアントイベントを使用して、関数呼び出しの結果を含む新しい会話項目を作成し、モデルに応答を依頼します。{ "type": "conversation.item.create", "item": { "type": "function_call_output", "call_id": "call_sHlR7iaFwQ2YQOqm", "output": "{\"horoscope\": \"もうすぐ新しい友達に会えるでしょう。\"}" } }
- 会話項目の type は
function_call_outputです。item.call_idは、上記のresponse.doneイベントで取得した ID と同じです。item.outputは、関数呼び出しの結果を含む JSON 文字列です。会話項目に関数呼び出しの結果が追加された後、クライアントから再度
response.createイベントを発行します。これにより、関数呼び出しのデータを用いてモデルが応答を生成します。{ "type": "response.create" }エラー処理
サーバーがセッション中にエラー状態に遭遇した場合、
errorイベントが発行されます。これらのエラーは、場合によってはアプリケーションが送信したクライアントイベントに起因することがあります。HTTP リクエストおよびレスポンスとは異なり、クライアントから送信されたリクエストに対してレスポンスが暗黙的に紐付いているわけではないため、どのクライアントイベントがサーバーでエラー状態を引き起こしたかを知るために
event_idプロパティを使用します。以下のコードは、サポートされていないイベントタイプを発行しようとした場合の例です:const event = { event_id: "my_awesome_event", type: "scooby.dooby.doo", }; dataChannel.send(JSON.stringify(event));このクライアントから送信された不正なイベントは、以下のようなエラーイベントを発行します:
{ "type": "invalid_request_error", "code": "invalid_value", "message": "Invalid value: 'scooby.dooby.doo' ...", "param": "type", "event_id": "my_awesome_event" }
Realtime transcription (Beta)
公式ドキュメント日本語訳
Realtime transcription
Realtime API を使用してリアルタイムにオーディオを文字起こしする方法を学びます。
マイク入力またはファイルからの入力を使用した、文字起こし専用のユースケース向けに Realtime API を利用することができます。たとえば、リアルタイムで字幕や文字起こしを生成するために使用できます。文字起こし専用モードでは、モデルは応答を生成しません。
Realtime transcription のセッション
文字起こしのために Realtime API を使用するには、WebSockets または WebRTC を介して接続し、transcriptionセッションを作成する必要があります。
通常の会話用 Realtime API セッションとは異なり、transcriptionセッションには通常、モデルからの応答は含まれません。
transcriptionセッションオブジェクトは、通常の Realtime API セッションとも異なります:
{ object: "realtime.transcription_session", id: string, input_audio_format: string, input_audio_transcription: [{ model: string, prompt: string, language: string }], turn_detection: { type: "server_vad", threshold: float, prefix_padding_ms: integer, silence_duration_ms: integer, } | null, input_audio_noise_reduction: { type: "near_field" | "far_field" }, include: list[string] | null }transcriptionセッションがサポートする追加プロパティのいくつかは以下の通りです:
input_audio_transcription.model: 使用する文字起こしモデル。現在はgpt-4o-transcribe、gpt-4o-mini-transcribe、およびwhisper-1がサポートされています。input_audio_transcription.prompt: 文字起こしの際にモデルを誘導するためのプロンプト(例:「技術に関連する単語を予期する」)。input_audio_transcription.language: 文字起こしに使用する言語。精度とレイテンシを向上させるために、理想的には ISO-639-1 形式(例:"en", "fr" など)で指定します。input_audio_noise_reduction: 文字起こしに使用するノイズリダクションの設定。include: 文字起こしイベントに含めるプロパティのリスト。入力オーディオフォーマットの可能な値は、
pcm16(デフォルト)、g711_ulawおよびg711_alawです。文字起こしセッションオブジェクトの詳細については、API リファレンス をご覧ください。
文字起こしの取り扱い
Realtime API を文字起こしのために使用する場合、
conversation.item.input_audio_transcription.deltaイベントとconversation.item.input_audio_transcription.completedイベントをリッスンすることができます。
whisper-1の場合、deltaイベントにはcompletedイベントと同様にターン全体の文字起こしが含まれます。gpt-4o-transcribeおよびgpt-4o-mini-transcribeの場合、deltaイベントにはモデルからストリーミングされるインクリメンタルな文字起こしが含まれます。以下は、文字起こしの delta イベントの例です:
{ "event_id": "event_2122", "type": "conversation.item.input_audio_transcription.delta", "item_id": "item_003", "content_index": 0, "delta": "こんにちは、" }以下は、文字起こしの完了イベントの例です:
{ "event_id": "event_2122", "type": "conversation.item.input_audio_transcription.completed", "item_id": "item_003", "content_index": 0, "transcript": "こんにちは、お元気ですか?" }異なる音声ターンからの完了イベント間の順序は保証されません。これらのイベントを
input_audio_buffer.committedイベントと一致させるためにitem_idを使用し、順序を処理するためにinput_audio_buffer.committed.previous_item_idを使用してください。transcriptionセッションにオーディオデータを送信するには、
input_audio_buffer.appendイベントを使用します。以下の 2 つのオプションがあります:
- ストリーミングのマイク入力を使用する
- wav ファイルからデータをストリーミングする
音声アクティビティ検出
Realtime API は自動音声アクティビティ検出(VAD)をサポートしています。デフォルトで有効になっており、VAD は入力オーディオバッファがコミットされるタイミング、すなわち文字起こしが開始されるタイミングを制御します。
VAD の設定方法の詳細については、Voice Activity Detection ガイドをお読みください。
また、
turn_detectionプロパティをnullに設定することで VAD を無効にし、オーディオのコミットタイミングを自分で制御することも可能です。追加設定
ノイズリダクション
input_audio_noise_reductionプロパティを使用して、オーディオストリームのノイズリダクションの取り扱いを設定できます。可能な値は以下の通りです:
near_field: 近接音場用ノイズリダクションを使用します。far_field: 遠隔音場用ノイズリダクションを使用します。null: ノイズリダクションを無効にします。デフォルト値は
near_fieldであり、プロパティをnullに設定することでノイズリダクションを無効にすることができます。logprobs の使用
includeプロパティを使用して、文字起こしイベントにitem.input_audio_transcription.logprobsを含め、logprobs を含めることができます。これらの logprobs は、文字起こしの信頼度スコアを計算するために使用できます。
{ "type": "transcription_session.update", "input_audio_format": "pcm16", "input_audio_transcription": { "model": "gpt-4o-transcribe", "prompt": "", "language": "" }, "turn_detection": { "type": "server_vad", "threshold": 0.5, "prefix_padding_ms": 300, "silence_duration_ms": 500, }, "input_audio_noise_reduction": { "type": "near_field" }, "include": [ "item.input_audio_transcription.logprobs" ] }
音声アクティビティ検出(Voice activity detection: VAD)
公式ドキュメント日本語訳
音声アクティビティ検出 (VAD)
Realtime API における自動音声アクティビティ検出について学びます。
音声アクティビティ検出 (VAD) は、ユーザーがいつ話し始め、いつ話し終えたかを自動的に検出するために Realtime API で利用可能な機能です。これは 音声対音声 や 文字起こし の Realtime セッションでデフォルトで有効になっていますが、任意でオフにすることもできます。
概要
VAD が有効な場合、オーディオは自動的にチャンク分割され、ユーザーが話し始めた時や話し終えた時にイベントが送信されます:
input_audio_buffer.speech_started: 話し始めたタイミングinput_audio_buffer.speech_stopped: 話し終えたタイミングこれらのイベントを使用して、アプリケーション内で音声ターンを処理することができます。例えば、会話状態の管理や文字起こしをチャンクごとに処理するのに利用できます。
session.updateイベントのturn_detectionプロパティを使用して、各音声認識サンプル内でオーディオがどのようにチャンク分割されるかを設定できます。VAD には以下の 2 つのモードがあります:
server_vad: 無音期間に基づいてオーディオを自動的にチャンク分割します。semantic_vad: ユーザーが発話を完了したとモデルが判断したタイミングでオーディオをチャンク分割します。デフォルト値は
server_vadです。以下で、各モードの詳細について説明します。
Server VAD
Server VAD は Realtime セッションのデフォルトモードで、無音期間を利用して自動的にオーディオをチャンク分割します。
VAD 設定を微調整するために、以下のプロパティを調整できます:
threshold: 活性化の閾値 (0 から 1 の範囲)。閾値が高いほど、モデルを活性化するために大きな音量が必要になり、騒がしい環境での性能が向上する可能性があります。prefix_padding_ms: VAD が検出する前に含めるオーディオの量(ミリ秒単位)。silence_duration_ms: 話し終えを検出するための無音期間の長さ(ミリ秒単位)。値が短いほど、ターンの終了が早く検出されます。以下は VAD の設定例です:
{ "type": "session.update", "session": { "turn_detection": { "type": "server_vad", "threshold": 0.5, "prefix_padding_ms": 300, "silence_duration_ms": 500, "create_response": true, // 会話モードのみ "interrupt_response": true // 会話モードのみ } } }Semantic VAD
Semantic VAD は、新しいモードであり、ユーザーが発話を完了したかどうかを、実際に発せられた言葉に基づいて検出するセマンティック分類器を使用します。この分類器は、ユーザーが話し終えた可能性の確率に基づいて入力オーディオをスコアリングします。確率が低い場合、モデルはタイムアウトを待ち、高い場合は待つ必要がありません。例えば、「うーん…」と trailing off する場合は、明確な発言に比べてタイムアウトが長くなります。
このモードでは、会話モードにおいてユーザーの発話を中断したり、文字起こしを早すぎるタイミングでチャンク分割する可能性が低くなります。
Semantic VAD は、
session.updateイベントでturn_detection.typeをsemantic_vadに設定することで有効化できます。以下のように設定できます:
{ "type": "session.update", "session": { "turn_detection": { "type": "semantic_vad", "eagerness": "low" | "medium" | "high" | "auto", // オプション "create_response": true, // 会話モードのみ "interrupt_response": true // 会話モードのみ } } }オプションの
eagernessプロパティは、モデルがユーザーの発話を中断する際の待機時間の最大値を調整するためのものです。文字起こしモードでは、モデルが応答しなくてもオーディオのチャンク分割に影響します。* `auto` はデフォルト値で、`medium` と同等です。 * `low` に設定すると、ユーザーがゆっくり話すことができます。 * `high` に設定すると、できるだけ早くオーディオがチャンク分割されます。会話モードでモデルにより頻繁に応答させたい場合、または文字起こしモードでより速く文字起こしイベントを返したい場合は、
eagernessをhighに設定できます。逆に、会話モードでユーザーに中断されずに発話させたい場合、または文字起こしモードでより大きなチャンクを得たい場合は、
eagernessをlowに設定してください。