Molmoを試す
この辺で知った。
MolmoとPixMo: 最先端のマルチモーダルモデルのためのオープンウェイトとオープンデータ
要約
今日最も進化したマルチモーダルモデルは依然としてプロプライエタリである。最も強力なオープンウェイトモデルは、優れたパフォーマンスを達成するためにプロプライエタリなVLMからの合成データに大きく依存しており、事実上、これらのクローズドモデルをオープンなものに変えている。その結果、コミュニティは、ゼロから高性能なVLMを構築する方法についての基礎的な知識を依然として欠いている。我々は、オープン性という点で最先端の新しいVLMファミリーであるMolmoを提示する。私たちの主な革新は、音声による説明を使用して、人間のアノテーターから完全に収集した、新規で非常に詳細な画像キャプションのデータセットである。また、幅広いユーザーとのやりとりを可能にするため、実環境のQ&Aや革新的な2Dポインティングデータを含む、多様なデータセットの混合物を微調整用に導入している。我々のアプローチの成功は、モデルアーキテクチャの詳細の慎重な選択、よく調整されたトレーニングパイプライン、そして最も重要なのは、新たに収集したデータセットの品質に依存しており、これらはすべて公開される予定である。Molmoファミリーにおける最高クラスの72Bモデルは、オープンな重みおよびデータモデルのクラスにおいて他を凌駕するだけでなく、GPT-4o、Claude 3.5、Gemini 1.5などのプロプライエタリなシステムと比較しても、学術的なベンチマークと人間による評価の両方で良好な結果を示している。近い将来、当社のモデルの重み、キャプションおよび微調整データ、ソースコードをすべて公開する予定である。モデルの重み、推論コード、デモの選択は、https://molmo.allenai.orgで利用可能である。
モデルは以下の4つ
MolmoE-1Bは、OLMoE-1B-7B-0924をベースとした、15億のアクティブパラメータと72億の総パラメータを持つマルチモーダルなMixture-of-Experts LLMである。学術的なベンチマークと人間による評価の両方において、GPT-4Vの性能にほぼ匹敵し、同規模のオープンマルチモーダルモデルの中で最先端の性能を達成している。
Molmo 7B-Oは、OLMo-7B-1124(リリース予定)をベースに、OpenAI CLIPをビジョンバックボーンとして使用している。学術的なベンチマークと人間による評価の両方において、GPT-4VとGPT-4oの間で快適に動作する。
Molmo 7B-DはQwen2-7Bをベースに、OpenAI CLIPをビジョンバックボーンとして使用している。学術的なベンチマークと人間による評価の両方において、GPT-4VとGPT-4oの間で快適に動作する。molmo.allenai.orgのMolmoデモを動かしている。
Molmo 72BはQwen2-72Bをベースに、OpenAI CLIPをビジョンバックボーンとして使用している。Molmo-72Bは学術的なベンチマークスコアで最高点を獲得し、GPT-4oにわずかに及ばず、人間による評価では2位となった。
パラメータ数が単純に違うだけじゃなくて、微妙にベースモデルが違ったりしてる感じ。
デモはこちら
72B以外のモデルをColaboratoryで試してみる。
共通
とりあえずランタイムはL4(VRAM22GB)で。
MolmoE 1B
パッケージインストール
!pip install einops torchvision
モデルをロード
from transformers import AutoModelForCausalLM, AutoProcessor, GenerationConfig
from PIL import Image
import requests
# load the processor
processor = AutoProcessor.from_pretrained(
'allenai/MolmoE-1B-0924',
trust_remote_code=True,
torch_dtype='auto',
device_map='auto'
)
# load the model
model = AutoModelForCausalLM.from_pretrained(
'allenai/MolmoE-1B-0924',
trust_remote_code=True,
torch_dtype='auto',
device_map='auto'
)
この時点でこうなる。
1BだけどMoEなので、そのまま鵜呑みにはできないってことなのかな?ただこれだと推論でコケるのは間違いなさそう。
HuggingFaceのCommunity見てると、どうやら環境変数を指定したらいける様子
あと4ビット量子化してる例もある。
まずは環境変数を設定してみる。一旦ランタイムは削除してやり直し。
import os
os.environ["PYTORCH_CUDA_ALLOC_CONF"]="expandable_segments:True"
モデルをロード
from transformers import AutoModelForCausalLM, AutoProcessor, GenerationConfig
from PIL import Image
import requests
# load the processor
processor = AutoProcessor.from_pretrained(
'allenai/MolmoE-1B-0924',
trust_remote_code=True,
torch_dtype='auto',
device_map='auto'
)
# load the model
model = AutoModelForCausalLM.from_pretrained(
'allenai/MolmoE-1B-0924',
trust_remote_code=True,
torch_dtype='auto',
device_map='auto'
)
多少減った。
では推論。
# process the image and text
inputs = processor.process(
images=[Image.open(requests.get("https://picsum.photos/id/237/536/354", stream=True).raw)],
text="この画像について説明して"
)
# move inputs to the correct device and make a batch of size 1
inputs = {k: v.to(model.device).unsqueeze(0) for k, v in inputs.items()}
# generate output; maximum 200 new tokens; stop generation when <|endoftext|> is generated
output = model.generate_from_batch(
inputs,
GenerationConfig(max_new_tokens=200, stop_strings="<|endoftext|>"),
tokenizer=processor.tokenizer
)
# only get generated tokens; decode them to text
generated_tokens = output[0,inputs['input_ids'].size(1):]
generated_text = processor.tokenizer.decode(generated_tokens, skip_special_tokens=True)
# print the generated text
print(generated_text)
# >>> This photograph captures a small black puppy, likely a Labrador or a similar breed,
# sitting attentively on a weathered wooden deck. The deck, composed of three...
推論中のメモリも問題なさそうなんだけど、待てど暮せど結果が返ってこない。
10分ぐらいでやっと返ってきた。
This image features an adorable black Labrador puppy sitting on a wooden deck. The puppy is positioned in the center of the frame, with its body facing forward and its head slightly tilted to the right. Its expressive brown eyes and black nose are prominent, giving it an endearing appearance. The puppy's ears are floppy, and its tail is slightly raised, adding to its charming demeanor.
The wooden deck beneath the puppy is composed of three visible planks. The wood has a light brown color with darker brown grain patterns, creating a rustic backdrop for the cute pup.
The photograph is taken from a top-down perspective, focusing entirely on the puppy and the deck. This angle emphasizes the puppy's cuteness and creates a warm, inviting atmosphere. The composition draws the viewer's attention directly to the puppy's face and front paws, making it the clear focal point of the image.
Overall, this picture captures the essence of puppy cuteness in a
んー、英語かぁ・・・
環境変数無しで4ビット量子化した場合。ランタイムは削除してやり直し。
bitsandbytesを追加しておく
!pip install einops torchvision bitsandbytes
モデルロード時にload_in_4bit=Trueを付与
from transformers import AutoModelForCausalLM, AutoProcessor, GenerationConfig
from PIL import Image
import requests
processor = AutoProcessor.from_pretrained(
'allenai/MolmoE-1B-0924',
trust_remote_code=True,
torch_dtype='auto',
device_map='auto'
)
model = AutoModelForCausalLM.from_pretrained(
'allenai/MolmoE-1B-0924',
trust_remote_code=True,
torch_dtype='auto',
device_map='auto',
load_in_4bit=True,
)
めちゃめちゃ下がったな。
では推論
inputs = processor.process(
images=[Image.open(requests.get("https://picsum.photos/id/237/536/354", stream=True).raw)],
text="この画像について説明して"
)
inputs = {k: v.to(model.device).unsqueeze(0) for k, v in inputs.items()}
output = model.generate_from_batch(
inputs,
GenerationConfig(max_new_tokens=200, stop_strings="<|endoftext|>"),
tokenizer=processor.tokenizer
)
generated_tokens = output[0,inputs['input_ids'].size(1):]
generated_text = processor.tokenizer.decode(generated_tokens, skip_special_tokens=True)
print(generated_text)

1分ぐらいで返ってきた
This image features an adorable black Labrador puppy sitting on a weathered wooden deck. The puppy's sleek, shiny coat contrasts beautifully with the rustic background of aged wooden planks. Its floppy ears, expressive eyes, and curious expression capture the essence of youthful innocence and charm. The puppy's posture, with its front paws slightly raised, suggests a playful or attentive stance. The overall scene evokes a sense of warmth and nostalgia, highlighting the simple beauty of a young dog enjoying time outdoors.
もう一度やってみた
inputs = processor.process(
images=[Image.open(requests.get("https://picsum.photos/id/237/536/354", stream=True).raw)],
text="この画像について説明して。日本語で。"
)
(snip)
この写真について説明します。
ペンジンの子どもです。 黒い母鳴動をしている。 眼を見る。 ペンジンの子どもは、黒い母鳴動をしている。 眼を見る。 ペンジンの子どもは、黒い母鳴動をしている。 眼を見る。 ペンジンの子どもは、黒い母鳴動をしている。 眼を見る。 ペンジンの子どもは、黒い母鳴動をしている。 眼を見る。 ペンジンの子どもは、黒い母鳴動をしている。 眼を見る
うーん、量子化したというのもあるかもだけど、このモデル自体が日本語あまりできなさそうな気がする
Molmo-7B-O
パッケージインストール。bitsandbytesは量子化が必要な場合に備えて。
!pip install einops torchvision bitsandbytes
モデルのロード
from transformers import AutoModelForCausalLM, AutoProcessor, GenerationConfig
from PIL import Image
import requests
processor = AutoProcessor.from_pretrained(
'allenai/Molmo-7B-O-0924',
trust_remote_code=True,
torch_dtype='auto',
device_map='auto'
)
model = AutoModelForCausalLM.from_pretrained(
'allenai/Molmo-7B-O-0924',
trust_remote_code=True,
torch_dtype='auto',
device_map='auto'
)
推論
inputs = processor.process(
images=[Image.open(requests.get("https://picsum.photos/id/237/536/354", stream=True).raw)],
text="この画像について説明して"
)
inputs = {k: v.to(model.device).unsqueeze(0) for k, v in inputs.items()}
output = model.generate_from_batch(
inputs,
GenerationConfig(max_new_tokens=200, stop_strings="<|endoftext|>"),
tokenizer=processor.tokenizer
)
generated_tokens = output[0,inputs['input_ids'].size(1):]
generated_text = processor.tokenizer.decode(generated_tokens, skip_special_tokens=True)
print(generated_text)
OutOfMemoryError: CUDA out of memory. Tried to allocate 1.53 GiB. GPU 0 has a total capacity of 22.17 GiB of which 826.88 MiB is free. Process 41370 has 21.35 GiB memory in use.
モデルのページに色々書いてあるけど、以下のようにbf16にしてみた。
from transformers import AutoModelForCausalLM, AutoProcessor, GenerationConfig
from PIL import Image
import requests
import torch
processor = AutoProcessor.from_pretrained(
'allenai/Molmo-7B-O-0924',
trust_remote_code=True,
torch_dtype=torch.bfloat16, # BF16
device_map='auto'
)
model = AutoModelForCausalLM.from_pretrained(
'allenai/Molmo-7B-O-0924',
trust_remote_code=True,
torch_dtype=torch.bfloat16, # BF16
device_map='auto'
)

inputs = processor.process(
images=[Image.open(requests.get("https://picsum.photos/id/237/536/354", stream=True).raw)],
text="この画像について説明して"
)
inputs = {k: v.to(model.device).unsqueeze(0) for k, v in inputs.items()}
with torch.autocast(device_type="cuda", enabled=True, dtype=torch.bfloat16):
output = model.generate_from_batch(
inputs,
GenerationConfig(max_new_tokens=200, stop_strings="<|endoftext|>"),
tokenizer=processor.tokenizer
)
generated_tokens = output[0,inputs['input_ids'].size(1):]
generated_text = processor.tokenizer.decode(generated_tokens, skip_special_tokens=True)
print(generated_text)
この画像では、狐の頭を見るということができます。狐の頭は、狐の特殊な頭形を示します。狐の頭は、狐の獣の頭とは異なり、狐の頭は狐の獣の頭とは異なります。狐の頭は、狐の獣の頭とは異なります。狐の頭は、狐の獣の頭とは異なります。狐の頭は、狐の獣の頭とは異なります。狐の頭は、狐の獣の頭とは異なります
うーん、なかなかつらい。
英語だとこう
inputs = processor.process(
images=[Image.open(requests.get("https://picsum.photos/id/237/536/354", stream=True).raw)],
text="Describe this image."
)
(snip)
This image captures a heartwarming scene of a black Labrador puppy sitting on a weathered wooden deck. The puppy's glossy coat contrasts beautifully with the rustic, grayish-brown planks beneath it. Its large, expressive brown eyes gaze up at the camera, conveying a sense of curiosity and innocence. The puppy's ears are floppy, adding to its adorable appearance. One of its front paws is visible, while the other is tucked underneath its body. The wooden deck shows signs of age and wear, with visible cracks and a slightly faded finish, enhancing the rustic charm of the setting. The overall composition creates a touching portrait that highlights the puppy's endearing presence against the backdrop of the weathered deck.
Molmo-7B-D
パッケージインストール。bitsandbytesは量子化が必要な場合に備えて。
!pip install einops torchvision bitsandbytes
まずはREADME通りに。
モデルのロード
from transformers import AutoModelForCausalLM, AutoProcessor, GenerationConfig
from PIL import Image
import requests
processor = AutoProcessor.from_pretrained(
'allenai/Molmo-7B-D-0924',
trust_remote_code=True,
torch_dtype='auto',
device_map='auto'
)
model = AutoModelForCausalLM.from_pretrained(
'allenai/Molmo-7B-D-0924',
trust_remote_code=True,
torch_dtype='auto',
device_map='auto'
)
推論
inputs = processor.process(
images=[Image.open(requests.get("https://picsum.photos/id/237/536/354", stream=True).raw)],
text="この画像について説明して"
)
inputs = {k: v.to(model.device).unsqueeze(0) for k, v in inputs.items()}
output = model.generate_from_batch(
inputs,
GenerationConfig(max_new_tokens=200, stop_strings="<|endoftext|>"),
tokenizer=processor.tokenizer
)
generated_tokens = output[0,inputs['input_ids'].size(1):]
generated_text = processor.tokenizer.decode(generated_tokens, skip_special_tokens=True)
print(generated_text)
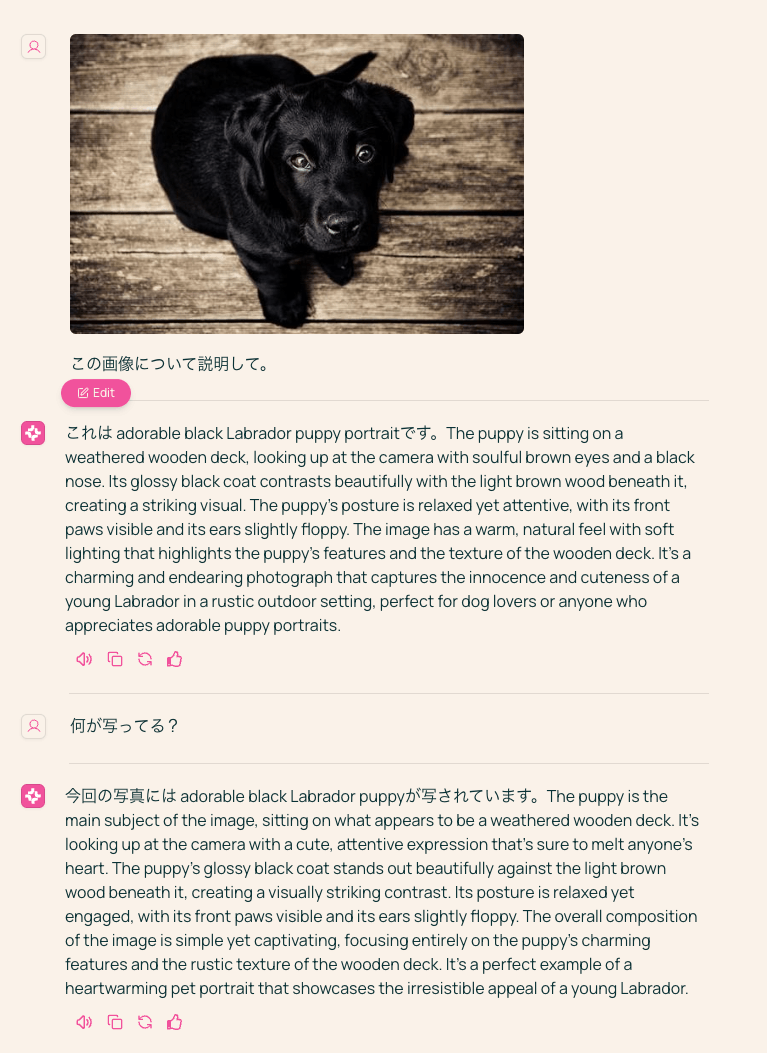
これは adorable black Labrador puppy portraitです。The puppy is sitting on a weathered wooden deck, looking up at the camera with soulful brown eyes and a black nose. Its glossy black coat contrasts beautifully with the light brown wood beneath it. The puppy's posture is relaxed, with its front paws visible and its ears slightly floppy. The image has a warm, natural feel with soft lighting that highlights the puppy's features and the texture of the wooden deck. It's a charming and endearing photograph that captures the innocence and cuteness of a young Labrador in a cozy outdoor setting.
今回は何もせずにVRAM22GBに収まって推論まで行けたんだけど、日本語がなぁ。。。ただまあ文意は破綻しているわけではないし、間違ってはいない。
あと推論も結構遅くて5分ぐらいかかる。
ということでこちらもBF16に。
from transformers import AutoModelForCausalLM, AutoProcessor, GenerationConfig
from PIL import Image
import requests
import torch
processor = AutoProcessor.from_pretrained(
'allenai/Molmo-7B-D-0924',
trust_remote_code=True,
torch_dtype=torch.bfloat16, # BF16
device_map='auto'
)
model = AutoModelForCausalLM.from_pretrained(
'allenai/Molmo-7B-D-0924',
trust_remote_code=True,
torch_dtype=torch.bfloat16, # BF16
device_map='auto'
)
inputs = processor.process(
images=[Image.open(requests.get("https://picsum.photos/id/237/536/354", stream=True).raw)],
text="この画像について説明して。"
)
inputs = {k: v.to(model.device).unsqueeze(0) for k, v in inputs.items()}
with torch.autocast(device_type="cuda", enabled=True, dtype=torch.bfloat16):
output = model.generate_from_batch(
inputs,
GenerationConfig(max_new_tokens=200, stop_strings="<|endoftext|>"),
tokenizer=processor.tokenizer
)
generated_tokens = output[0,inputs['input_ids'].size(1):]
generated_text = processor.tokenizer.decode(generated_tokens, skip_special_tokens=True)
print(generated_text)
これは adorable black Labrador puppy portraitです。The puppy is sitting on a weathered wooden deck, looking up at the camera with soulful brown eyes and a black nose. Its glossy black coat contrasts beautifully with the light brown wood beneath it, creating a striking visual. The puppy's posture is relaxed yet attentive, with its front paws visible and its ears slightly floppy. The image has a warm, natural light that enhances the puppy's cute features and gives the scene a cozy, homey feel. It's a charming capture of a young Labrador's innocent charm and the simple beauty of a sunny day outdoors.
うーん、ダメダメだなぁ・・・
一応公式のデモはこのモデルらしいけど。。。
同じ画像でデモを試してみたけど、日本語はあんまりかもしれない。なんかうまく行ったような気がしてたんだけども、んー、気のせいだったのかも?
とりあえず日本語にはちょっと難がありそうではあるのと、f32だと大きすぎるってところが使いにくいが、座標的なものをきちんと取れるという強みがあるっぽいので、ユースケースに合えば使えるかもしれない。