LlamaIndexでDocuments/Nodesを色々カスタマイズしてみる
from pathlib import Path
import requests
wiki_titles = ["ドウデュース", "イクイノックス"]
for title in wiki_titles:
response = requests.get(
"https://ja.wikipedia.org/w/api.php",
params={
"action": "query",
"format": "json",
"titles": title,
"prop": "extracts",
# 'exintro': True,
"explaintext": True,
},
).json()
page = next(iter(response["query"]["pages"].values()))
wiki_text = page["extract"]
data_path = Path("data")
if not data_path.exists():
Path.mkdir(data_path)
with open(data_path / f"{title}.txt", "w") as fp:
fp.write(wiki_text)
!head data/*
==> data/イクイノックス.txt <==
イクイノックス(欧字名:Equinox、2019年3月23日 - )は、日本の競走馬。
2022年にキタサンブラック産駒として初のGI制覇を果たし、2023年には秋春グランプリ制覇を達成した。馬名の意味は「昼と夜の長さがほぼ等しくなる時」。2022年度のJRA賞年度代表馬、最優秀3歳牡馬である。
主な勝ち鞍は2022年・2023年の天皇賞(秋)連覇、2022年の有馬記念、2023年のドバイシーマクラシック、宝塚記念、ジャパンカップ。
== 血統・デビュー前 ==
キタサンブラックの初年度産駒である。GIを7勝し、演歌歌手・北島三郎が実質的なオーナーである事からも注目を浴びた父を持ち、母はマーメイドステークスを制覇したシャトーブランシュ。その父は高松宮記念を制覇したキングヘイローである。
2019年3月23日、北海道安平町のノーザンファームで誕生。一口馬主法人シルクホースクラブから総額4000万円(一口8万円×500口)で募集され、ノーザンファーム早来で育成。厩舎長の桑田裕規によると、距離適性と馬体の成長面から、当時の目標としては父の制した菊花賞が据えられていた。その後、美浦トレーニングセンターの木村哲也厩舎に入厩した。
==> data/ドウデュース.txt <==
ドウデュース(欧字名:Do Deuce、2019年5月7日 - )は、日本の競走馬。主な勝ち鞍は2021年の朝日杯フューチュリティステークス、2022年の東京優駿、2023年の有馬記念。
馬名の意味は「する+テニス用語(勝利目前の意味)」。2021年のJRA賞最優秀2歳牡馬である。
== 戦績 ==
=== デビュー前 ===
2019年5月7日、北海道安平町のノーザンファームで誕生。松島正昭が代表を務める株式会社キーファーズの所有馬となり、ノーザンファーム空港牧場で育成の後、栗東トレーニングセンターの友道康夫厩舎に入厩した。
Documentsのカスタマイズ
よくあるパターン。
from llama_index import SimpleDirectoryReader
documents = SimpleDirectoryReader("./data").load_data()
len(documents)
2
for d in documents:
print(d.id_, d.metadata['file_name'])
print(d.get_content().replace("\n","")[:100])
4a275bc5-43d2-467c-9830-c56f133f173c イクイノックス.txt
イクイノックス(欧字名:Equinox、2019年3月23日 - )は、日本の競走馬。2022年にキタサンブラック産駒として初のGI制覇を果たし、2023年には秋春グランプリ制覇を達成した。馬名の意味
bd8c3b52-7d76-4dde-8db6-746764d4d659 ドウデュース.txt
ドウデュース(欧字名:Do Deuce、2019年5月7日 - )は、日本の競走馬。主な勝ち鞍は2021年の朝日杯フューチュリティステークス、2022年の東京優駿、2023年の有馬記念。馬名の意味は「
ファイル単位でDocumentオブジェクトとして作成される。
で、これを完全に手動でやることもできる。ベタベタに書いてみた。
import glob
from llama_index import Document
text_list = []
files = glob.glob("data/*.txt")
for file in files:
with open(file) as f:
text = f.read()
text_list.append(text)
documents = [Document(text=t) for t in text_list]
for d in documents:
print(d.id_, d.metadata)
print(d.get_content().replace("\n","")[:100])
24170a9e-889b-4c9d-a840-cd77c55baa72 {}
ドウデュース(欧字名:Do Deuce、2019年5月7日 - )は、日本の競走馬。主な勝ち鞍は2021年の朝日杯フューチュリティステークス、2022年の東京優駿、2023年の有馬記念。馬名の意味は「
99b76ffc-c0b8-4b9d-8bf0-811b833a8e15 {}
イクイノックス(欧字名:Equinox、2019年3月23日 - )は、日本の競走馬。2022年にキタサンブラック産駒として初のGI制覇を果たし、2023年には秋春グランプリ制覇を達成した。馬名の意味
SimpleDirectoryReaderはファイル情報などのメタデータも作成してくれるが、手動でやった場合はメタデータが一切ないのがわかる。
メタデータのカスタマイズ
Documentオブジェクトのメタデータをカスタマイズすることができる。
上の手動で作成したDocumentに後から付与するパターン。
documents[0].metadata = {
"filename": "ドウデュース.txt",
"filepath": "data/ドウデュース.txt",
"title": "ドウデュース",
}
documents[1].metadata = {
"filename": "イクイノックス.txt",
"filepath": "data/イクイノックス.txt",
"title": "イクイノックス",
}
for d in documents:
print(d.id_, d.metadata)
print(d.get_content().replace("\n","")[:100])
f2088f64-f3d5-4c39-a418-640e3fcebded {'filename': 'ドウデュース.txt', 'filepath': 'data/ドウデュース.txt', 'title': 'ドウデュース'}
ドウデュース(欧字名:Do Deuce、2019年5月7日 - )は、日本の競走馬。主な勝ち鞍は2021年の朝日杯フューチュリティステークス、2022年の東京優駿、2023年の有馬記念。馬名の意味は「
52444ecc-4448-439c-94e7-58393706b8bd {'filename': 'イクイノックス.txt', 'filepath': 'data/イクイノックス.txt', 'title': 'イクイノックス'}
イクイノックス(欧字名:Equinox、2019年3月23日 - )は、日本の競走馬。2022年にキタサンブラック産駒として初のGI制覇を果たし、2023年には秋春グランプリ制覇を達成した。馬名の意味
Documentコンストラクタで設定するパターン。
import os
import glob
from llama_index import Document
documents = []
files = glob.glob("data/*.txt")
for file in files:
file_basename = os.path.basename(file)
horse_name = os.path.splitext(file_basename)[0]
with open(file) as f:
text = f.read()
doc = Document(
text=text,
metadata={
"filename": file_basename,
"filepath": file,
"title": horse_name,
}
)
documents.append(doc)
for d in documents:
print(d.id_, d.metadata)
print(d.get_content().replace("\n","")[:100])
0248646f-337f-4c7a-9c0b-85404a1103c6 {'filename': 'ドウデュース.txt', 'filepath': 'data/ドウデュース.txt', 'title': 'ドウデュース'}
ドウデュース(欧字名:Do Deuce、2019年5月7日 - )は、日本の競走馬。主な勝ち鞍は2021年の朝日杯フューチュリティステークス、2022年の東京優駿、2023年の有馬記念。馬名の意味は「
2aa8ecb2-0fe1-4c9f-b64c-a894bee777e7 {'filename': 'イクイノックス.txt', 'filepath': 'data/イクイノックス.txt', 'title': 'イクイノックス'}
イクイノックス(欧字名:Equinox、2019年3月23日 - )は、日本の競走馬。2022年にキタサンブラック産駒として初のGI制覇を果たし、2023年には秋春グランプリ制覇を達成した。馬名の意味
SimpleDirectoryReaderでもfile_metadataフックを利用すれば、デフォルトではなく自分でメタデータを設定できる。Python lambdaを使う場合。
from llama_index import SimpleDirectoryReader
filename_fn = lambda filename: {"file_name": filename}
documents = SimpleDirectoryReader(
"./data", file_metadata=filename_fn
).load_data()
for d in documents:
print(d.id_, d.metadata)
print(d.get_content().replace("\n","")[:100])
d10f8ef4-cb75-4eeb-a0ed-79143552a7ce {'file_name': 'data/イクイノックス.txt'}
イクイノックス(欧字名:Equinox、2019年3月23日 - )は、日本の競走馬。2022年にキタサンブラック産駒として初のGI制覇を果たし、2023年には秋春グランプリ制覇を達成した。馬名の意味
631231d4-af0e-4411-bf25-80698365480e {'file_name': 'data/ドウデュース.txt'}
ドウデュース(欧字名:Do Deuce、2019年5月7日 - )は、日本の競走馬。主な勝ち鞍は2021年の朝日杯フューチュリティステークス、2022年の東京優駿、2023年の有馬記念。馬名の意味は「
関数を使う場合。
import os
from llama_index import SimpleDirectoryReader
def fileinfo_fn(file):
file_basename = os.path.basename(file)
horse_name = os.path.splitext(file_basename)[0]
return {
"filename": file_basename,
"filepath": file,
"title": horse_name,
}
documents = SimpleDirectoryReader(
"./data", file_metadata=fileinfo_fn
).load_data()
for d in documents:
print(d.id_, d.metadata)
print(d.get_content().replace("\n","")[:100])
5843ada1-a831-4eaf-83a0-06ffa8eb9e66 {'filename': 'イクイノックス.txt', 'filepath': 'data/イクイノックス.txt', 'title': 'イクイノックス'}
イクイノックス(欧字名:Equinox、2019年3月23日 - )は、日本の競走馬。2022年にキタサンブラック産駒として初のGI制覇を果たし、2023年には秋春グランプリ制覇を達成した。馬名の意味
57f521ab-c19a-40df-ac78-286043a86e59 {'filename': 'ドウデュース.txt', 'filepath': 'data/ドウデュース.txt', 'title': 'ドウデュース'}
ドウデュース(欧字名:Do Deuce、2019年5月7日 - )は、日本の競走馬。主な勝ち鞍は2021年の朝日杯フューチュリティステークス、2022年の東京優駿、2023年の有馬記念。馬名の意味は「
メタデータで重要なのは、メタデータの情報はLLMのコンテキストに含まれる、というところ。ここは後でもう少し細かく見る。
各ドキュメントのメタデータ辞書に設定された情報はすべて、ドキュメントから作成された各ソース・ノードのメタデータに表示されます。さらに、この情報はノードに含まれるため、インデックスがクエリやレスポンスでこの情報を利用できるようになります。デフォルトでは、メタデータは、埋め込みと LLM モデル呼び出しの両方でテキストに注入されます。
また、この辺も抑えておく。
ベクトルデータベースと統合する場合、ベクトルデータベースによっては、キーは文字列でなければならず、値はフラット(str、float、intのいずれか)でなければならないことを覚えておいてください。
IDのカスタマイズ
上の例にもある通り、DocumentにはIDが必要となり、デフォルトではUUIDで付与される。
このDocument IDをカスタマイズすることもできる。
SimpleDirectoryReaderでファイル名をIDとする場合はfilename_as_idを有効にする。
from llama_index import SimpleDirectoryReader
documents = SimpleDirectoryReader("./data", filename_as_id=True).load_data()
for d in documents:
print(d.id_, d.metadata)
print(d.get_content().replace("\n","")[:100])
data/イクイノックス.txt {'file_path': 'data/イクイノックス.txt', 'file_name': 'イクイノックス.txt', 'file_type': 'text/plain', 'file_size': 27252, 'creation_date': '2024-01-16', 'last_modified_date': '2024-01-16', 'last_accessed_date': '2024-01-16'}
イクイノックス(欧字名:Equinox、2019年3月23日 - )は、日本の競走馬。2022年にキタサンブラック産駒として初のGI制覇を果たし、2023年には秋春グランプリ制覇を達成した。馬名の意味
data/ドウデュース.txt {'file_path': 'data/ドウデュース.txt', 'file_name': 'ドウデュース.txt', 'file_type': 'text/plain', 'file_size': 9510, 'creation_date': '2024-01-16', 'last_modified_date': '2024-01-16', 'last_accessed_date': '2024-01-16'}
ドウデュース(欧字名:Do Deuce、2019年5月7日 - )は、日本の競走馬。主な勝ち鞍は2021年の朝日杯フューチュリティステークス、2022年の東京優駿、2023年の有馬記念。馬名の意味は「
すでにあるDocumentのIDも変更できる。
document[0].doc_id = "イクイノックス"
document[1].doc_id = "ドウデュース"
for d in documents:
print(d.id_, d.metadata)
print(d.get_content().replace("\n","")[:100])
イクイノックス {'file_path': 'data/イクイノックス.txt', 'file_name': 'イクイノックス.txt', 'file_type': 'text/plain', 'file_size': 27252, 'creation_date': '2024-01-16', 'last_modified_date': '2024-01-16', 'last_accessed_date': '2024-01-16'}
イクイノックス(欧字名:Equinox、2019年3月23日 - )は、日本の競走馬。2022年にキタサンブラック産駒として初のGI制覇を果たし、2023年には秋春グランプリ制覇を達成した。馬名の意味
ドウデュース {'file_path': 'data/ドウデュース.txt', 'file_name': 'ドウデュース.txt', 'file_type': 'text/plain', 'file_size': 9510, 'creation_date': '2024-01-16', 'last_modified_date': '2024-01-16', 'last_accessed_date': '2024-01-16'}
ドウデュース(欧字名:Do Deuce、2019年5月7日 - )は、日本の競走馬。主な勝ち鞍は2021年の朝日杯フューチュリティステークス、2022年の東京優駿、2023年の有馬記念。馬名の意味は「
より進んだメタデータのカスタマイズ
上に書いた
デフォルトでは、メタデータは、埋め込みと LLM モデル呼び出しの両方でテキストに注入されます。
はどういうことか?というと、例えばインデックスを作成してクエリエンジンでクエリを実行した場合のプロンプトを見るとわかる。
** Messages: **
system: You are an expert Q&A system that is trusted around the world.
Always answer the query using the provided context information, and not prior knowledge.
Some rules to follow:
1. Never directly reference the given context in your answer.
2. Avoid statements like 'Based on the context, ...' or 'The context information ...' or anything along those lines.
user: Context information is below.
---------------------
file_path: data/ドウデュース.txt
1番人気には推されたものの単勝のオッズは3.9倍で、これは1984年のグレード制導入以降、1990年アイネスフウジンの4.1倍に次ぐ皐月賞1番人気の低支持率オッズであった。レースでは道中後方からじっくり運び、最後の直線は外からメンバー最速となる上がり (競馬)3ハロン33秒8の鋭い脚を使って追い詰めたものの、3着に敗れた。(snip)
file_path: data/ドウデュース.txt
ドウデュース(欧字名:Do Deuce、2019年5月7日 - )は、日本の競走馬。主な勝ち鞍は2021年の朝日杯フューチュリティステークス、2022年の東京優駿、2023年の有馬記念。
馬名の意味は「する+テニス用語(勝利目前の意味)」。2021年のJRA賞最優秀2歳牡馬である。(snip)
---------------------
Given the context information and not prior knowledge, answer the query.
Query: ドウデュースの主な勝ち鞍は?
Answer:
**************************************************
** Response: **
assistant: ドウデュースの主な勝ち鞍は、2021年の朝日杯フューチュリティステークス、2022年の東京優駿、2023年の有馬記念です。
**************************************************
ちなみに上記はSimpleDirectoryReaderで普通にドキュメントを読ませてnode parser(SentenceSpllitter)で分割したデフォルトの場合。DocumentはTextNodeオブジェクトのサブクラスなのでそこから分割して作成したNodeにもメタデータは継承される。で、user: Context information is below.以下にベクトル検索で取得されたノード情報が含まれるが、ここにテキスト情報だけでなくfile_pathが含まれているのがわかる。
どのメタデータがLLMもしくはEmbeddingに含まれるかもDocumentには設定されている。
from llama_index import SimpleDirectoryReader
documents = SimpleDirectoryReader("./data").load_data()
print(documents[0].metadata)
print(documents[0].excluded_embed_metadata_keys)
print(documents[0].excluded_llm_metadata_keys)
{'file_path': 'data/イクイノックス.txt', 'file_name': 'イクイノックス.txt', 'file_type': 'text/plain', 'file_size': 27252, 'creation_date': '2024-01-16', 'last_modified_date': '2024-01-16', 'last_accessed_date': '2024-01-16'}
['file_name', 'file_type', 'file_size', 'creation_date', 'last_modified_date', 'last_accessed_date']
['file_name', 'file_type', 'file_size', 'creation_date', 'last_modified_date', 'last_accessed_date']
excluded_embed_metadata_keysがEmbeddingで「除外」されるメタデータのキー、excluded_llm_metadata_keysがLLMで「除外」されるメタデータのキーになる。先ほどのプロンプトを見るとわかるように、file_pathだけが除外対象ではないので、これがコンテキスト情報の一部としてプロンプトに含まれているという次第らしい。
これをカスタマイズすることができる。すでに作成したDocumentの場合。
from llama_index.schema import MetadataMode
# file_nameだけ除外
documents[0].excluded_llm_metadata_keys = ["file_name"]
# get_content() でMetadataModeを設定すると、コンテキストとして利用される場合の
# 出力を確認できる(実際にはNodeに分割されることになるが)
print(documents[0].get_content(metadata_mode=MetadataMode.LLM)[:300] + "...")
file_path: data/イクイノックス.txt
file_type: text/plain
file_size: 27252
creation_date: 2024-01-16
last_modified_date: 2024-01-16
last_accessed_date: 2024-01-16
イクイノックス(欧字名:Equinox、2019年3月23日 - )は、日本の競走馬。
2022年にキタサンブラック産駒として初のGI制覇を果たし、2023年には秋春グランプリ制覇を達成した。馬名の意味は「昼と夜の長さがほぼ等しくなる時」。2022年度のJRA賞年度代表馬、最優秀3歳牡馬...
Embeddingの場合も同様
from llama_index.schema import MetadataMode
documents[1].excluded_embed_metadata_keys = ["file_path","file_type", "creation_date", "last_modified_date"]
print(documents[1].get_content(metadata_mode=MetadataMode.EMBED)[:300] + "...")
file_name: ドウデュース.txt
file_size: 9510
last_accessed_date: 2024-01-16
ドウデュース(欧字名:Do Deuce、2019年5月7日 - )は、日本の競走馬。主な勝ち鞍は2021年の朝日杯フューチュリティステークス、2022年の東京優駿、2023年の有馬記念。
馬名の意味は「する+テニス用語(勝利目前の意味)」。2021年のJRA賞最優秀2歳牡馬である。
== 戦績 ==
=== デビュー前 ===
2019年5月7日、北海道安平町のノーザンファームで誕生。松島正昭が代表を務める株式会社キーファーズの所有馬となり、ノーザ...
メタデータのフォーマットのカスタマイズ
メタデータがどのように、LLMのプロンプトやEmbeddingに含まれるかのフォーマットもカスタマイズできる。以下の3つの設定がある。
-
Document.metadata_seperator- メタデータ間のセパレータ、デフォルトは
"\n" - つまり各メタデータごとに改行される
- メタデータ間のセパレータ、デフォルトは
-
Document.metadata_template- メタデータのキーと値のフォーマット。デフォルトは
"{key}: {value}"
- メタデータのキーと値のフォーマット。デフォルトは
-
Document.text_template- メタデータとコンテキストとなるテキストのフォーマット。デフォルトは
{metadata_str}\n\n{content}
- メタデータとコンテキストとなるテキストのフォーマット。デフォルトは
さきほどのget_content(metadata_mode=MetadataMode.XXX)を見るとわかるし、実際に作成されたドキュメントにもこの情報は付与されている。
print(repr(documents[0].metadata_seperator))
print(repr(documents[0].metadata_template))
print(repr(documents[0].text_template))
'\n'
'{key}: {value}'
'{metadata_str}\n\n{content}'
全部合わせて実際に変更してみる。
import os
import glob
from llama_index import Document
documents = []
files = glob.glob("data/*.txt")
for file in files:
file_basename = os.path.basename(file)
horse_name = os.path.splitext(file_basename)[0]
with open(file) as f:
text = f.read()
doc = Document(
text=text,
metadata={
"filename": file_basename,
"filepath": file,
"title": horse_name,
"category": "horse"
},
excluded_llm_metadata_keys=["file_name", "filepath"],
metadata_seperator=", ",
metadata_template="{key}=>{value}",
text_template="## Metadata\n\n{metadata_str}\n\n## Content\n\n{content}",
)
documents.append(doc)
for i, d in enumerate(documents, start=1):
print(f"# Doc No.{i}\n")
print(d.get_content(metadata_mode=MetadataMode.LLM)[:300] + "...")
# Doc No.1
## Metadata
filename=>ドウデュース.txt, title=>ドウデュース, category=>horse
## Content
ドウデュース(欧字名:Do Deuce、2019年5月7日 - )は、日本の競走馬。主な勝ち鞍は2021年の朝日杯フューチュリティステークス、2022年の東京優駿、2023年の有馬記念。
馬名の意味は「する+テニス用語(勝利目前の意味)」。2021年のJRA賞最優秀2歳牡馬である。
== 戦績 ==
=== デビュー前 ===
2019年5月7日、北海道安平町のノーザンファームで誕生。松島正昭が代表を務める株式会社キーファーズの所...
# Doc No.2
## Metadata
filename=>イクイノックス.txt, title=>イクイノックス, category=>horse
## Content
イクイノックス(欧字名:Equinox、2019年3月23日 - )は、日本の競走馬。
2022年にキタサンブラック産駒として初のGI制覇を果たし、2023年には秋春グランプリ制覇を達成した。馬名の意味は「昼と夜の長さがほぼ等しくなる時」。2022年度のJRA賞年度代表馬、最優秀3歳牡馬である。
主な勝ち鞍は2022年・2023年の天皇賞(秋)連覇、2022年の有馬記念、2023年のドバイシーマクラシック、宝塚記念、ジャパンカップ。
...
その他
あとはLLMを使ってメタデータを抽出させることもできるExtractorもある。
Nodesのカスタマイズ
Documentを一定のチャンクで分割したのがNodeであり、これにはNodeParserクラスを使う。例えばこんな感じ。
from llama_index import SimpleDirectoryReader
from llama_index.node_parser import SentenceSplitter
reader = SimpleDirectoryReader("./data")
parser = SentenceSplitter()
documents = reader.load_data()
nodes = parser.get_nodes_from_documents(documents)
分割されたNodeには、テキストだけでなくメタデータやNode間のリレーションなど様々な情報が付与され、これを元にインデックスが構成される。このあたりは以前まとめた通り。
で、Nodeの特徴的なものとして(厳密にはDocumentにもあるけども)リレーションがある。上で作成したDocumentとNodeの中身を見てみる。
print("## DOCUMENTS\n")
for d in documents:
print(d.id_, d.metadata["file_name"])
print()
print("## NODES\n")
print("### SOURCE\n")
for n in nodes:
print("SOURCE: {} --> THIS: {}".format(n.source_node.node_id, n.id_))
print()
print("### NEXT\n")
for n in nodes:
if n.next_node:
print("THIS: {} --> NEXT: {}".format(n.id_, n.next_node.node_id))
else:
print("THIS: {} --> NEXT: {}".format(n.id_, None))
print()
print("### PREV\n")
for n in nodes:
if n.prev_node:
print("PREV: {} --> THIS: {}".format(n.prev_node.node_id, n.id_))
else:
print("PREV: {} --> THIS: {}".format(None, n.id_))
print()
## DOCUMENTS
92dd1e9b-7b0b-4c72-890e-ef178775f588 イクイノックス.txt
d077857b-0ee3-4a1f-aa3b-1827abd446d2 ドウデュース.txt
## NODES
### SOURCE
SOURCE: 92dd1e9b-7b0b-4c72-890e-ef178775f588 --> THIS: cd363c0f-6c0d-40c5-9629-19c01275e6e3
SOURCE: 92dd1e9b-7b0b-4c72-890e-ef178775f588 --> THIS: 0b2604c1-d3fd-440f-b2e5-f46f0488d675
SOURCE: 92dd1e9b-7b0b-4c72-890e-ef178775f588 --> THIS: f2a253c6-7900-4836-ba49-c5659c697f62
SOURCE: 92dd1e9b-7b0b-4c72-890e-ef178775f588 --> THIS: 967d866e-2270-4e23-b874-770f82e11147
SOURCE: 92dd1e9b-7b0b-4c72-890e-ef178775f588 --> THIS: 03f9188e-2661-4f77-bf9b-b4d584853a5e
SOURCE: 92dd1e9b-7b0b-4c72-890e-ef178775f588 --> THIS: 31cab060-cd7a-4473-ac0b-3f785ebbba5e
SOURCE: 92dd1e9b-7b0b-4c72-890e-ef178775f588 --> THIS: 356341e3-d359-4c4b-abdf-56ae5f701263
SOURCE: 92dd1e9b-7b0b-4c72-890e-ef178775f588 --> THIS: 948d7a29-9539-4f96-abac-cc76a4bc429e
SOURCE: 92dd1e9b-7b0b-4c72-890e-ef178775f588 --> THIS: da38433c-8934-429d-a5c6-935ff2e90eb5
SOURCE: 92dd1e9b-7b0b-4c72-890e-ef178775f588 --> THIS: 9be62fe1-26f9-440f-8a9c-80e3e40c0612
SOURCE: 92dd1e9b-7b0b-4c72-890e-ef178775f588 --> THIS: 9622884e-3cd7-4219-af7c-b57584cf3396
SOURCE: 92dd1e9b-7b0b-4c72-890e-ef178775f588 --> THIS: b25c6598-bdfd-4d85-876e-47c8bdbdb9d4
SOURCE: 92dd1e9b-7b0b-4c72-890e-ef178775f588 --> THIS: 9f83a483-b33e-4259-a798-41c3de239dc8
SOURCE: 92dd1e9b-7b0b-4c72-890e-ef178775f588 --> THIS: 2448dee0-544a-411d-a717-d4d74d40ebcb
SOURCE: 92dd1e9b-7b0b-4c72-890e-ef178775f588 --> THIS: c0063c62-f9f4-40d1-9405-27a04dfe63ea
SOURCE: d077857b-0ee3-4a1f-aa3b-1827abd446d2 --> THIS: 686b0701-081a-409b-8bbc-080aea6c3308
SOURCE: d077857b-0ee3-4a1f-aa3b-1827abd446d2 --> THIS: 6148ee04-ba88-4799-922b-1eca538d5090
SOURCE: d077857b-0ee3-4a1f-aa3b-1827abd446d2 --> THIS: fe0032fe-f784-48e3-81ed-ca792c3fa1ef
SOURCE: d077857b-0ee3-4a1f-aa3b-1827abd446d2 --> THIS: 887be00e-0633-4a00-a58d-193c4b4934d8
SOURCE: d077857b-0ee3-4a1f-aa3b-1827abd446d2 --> THIS: 208f3113-fcbe-4369-a47f-f69c93c17930
### NEXT
THIS: cd363c0f-6c0d-40c5-9629-19c01275e6e3 --> NEXT: 0b2604c1-d3fd-440f-b2e5-f46f0488d675
THIS: 0b2604c1-d3fd-440f-b2e5-f46f0488d675 --> NEXT: f2a253c6-7900-4836-ba49-c5659c697f62
THIS: f2a253c6-7900-4836-ba49-c5659c697f62 --> NEXT: 967d866e-2270-4e23-b874-770f82e11147
THIS: 967d866e-2270-4e23-b874-770f82e11147 --> NEXT: 03f9188e-2661-4f77-bf9b-b4d584853a5e
THIS: 03f9188e-2661-4f77-bf9b-b4d584853a5e --> NEXT: 31cab060-cd7a-4473-ac0b-3f785ebbba5e
THIS: 31cab060-cd7a-4473-ac0b-3f785ebbba5e --> NEXT: 356341e3-d359-4c4b-abdf-56ae5f701263
THIS: 356341e3-d359-4c4b-abdf-56ae5f701263 --> NEXT: 948d7a29-9539-4f96-abac-cc76a4bc429e
THIS: 948d7a29-9539-4f96-abac-cc76a4bc429e --> NEXT: da38433c-8934-429d-a5c6-935ff2e90eb5
THIS: da38433c-8934-429d-a5c6-935ff2e90eb5 --> NEXT: 9be62fe1-26f9-440f-8a9c-80e3e40c0612
THIS: 9be62fe1-26f9-440f-8a9c-80e3e40c0612 --> NEXT: 9622884e-3cd7-4219-af7c-b57584cf3396
THIS: 9622884e-3cd7-4219-af7c-b57584cf3396 --> NEXT: b25c6598-bdfd-4d85-876e-47c8bdbdb9d4
THIS: b25c6598-bdfd-4d85-876e-47c8bdbdb9d4 --> NEXT: 9f83a483-b33e-4259-a798-41c3de239dc8
THIS: 9f83a483-b33e-4259-a798-41c3de239dc8 --> NEXT: 2448dee0-544a-411d-a717-d4d74d40ebcb
THIS: 2448dee0-544a-411d-a717-d4d74d40ebcb --> NEXT: c0063c62-f9f4-40d1-9405-27a04dfe63ea
THIS: c0063c62-f9f4-40d1-9405-27a04dfe63ea --> NEXT: 686b0701-081a-409b-8bbc-080aea6c3308
THIS: 686b0701-081a-409b-8bbc-080aea6c3308 --> NEXT: 6148ee04-ba88-4799-922b-1eca538d5090
THIS: 6148ee04-ba88-4799-922b-1eca538d5090 --> NEXT: fe0032fe-f784-48e3-81ed-ca792c3fa1ef
THIS: fe0032fe-f784-48e3-81ed-ca792c3fa1ef --> NEXT: 887be00e-0633-4a00-a58d-193c4b4934d8
THIS: 887be00e-0633-4a00-a58d-193c4b4934d8 --> NEXT: 208f3113-fcbe-4369-a47f-f69c93c17930
THIS: 208f3113-fcbe-4369-a47f-f69c93c17930 --> NEXT: None
### PREV
PREV: None --> THIS: cd363c0f-6c0d-40c5-9629-19c01275e6e3
PREV: cd363c0f-6c0d-40c5-9629-19c01275e6e3 --> THIS: 0b2604c1-d3fd-440f-b2e5-f46f0488d675
PREV: 0b2604c1-d3fd-440f-b2e5-f46f0488d675 --> THIS: f2a253c6-7900-4836-ba49-c5659c697f62
PREV: f2a253c6-7900-4836-ba49-c5659c697f62 --> THIS: 967d866e-2270-4e23-b874-770f82e11147
PREV: 967d866e-2270-4e23-b874-770f82e11147 --> THIS: 03f9188e-2661-4f77-bf9b-b4d584853a5e
PREV: 03f9188e-2661-4f77-bf9b-b4d584853a5e --> THIS: 31cab060-cd7a-4473-ac0b-3f785ebbba5e
PREV: 31cab060-cd7a-4473-ac0b-3f785ebbba5e --> THIS: 356341e3-d359-4c4b-abdf-56ae5f701263
PREV: 356341e3-d359-4c4b-abdf-56ae5f701263 --> THIS: 948d7a29-9539-4f96-abac-cc76a4bc429e
PREV: 948d7a29-9539-4f96-abac-cc76a4bc429e --> THIS: da38433c-8934-429d-a5c6-935ff2e90eb5
PREV: da38433c-8934-429d-a5c6-935ff2e90eb5 --> THIS: 9be62fe1-26f9-440f-8a9c-80e3e40c0612
PREV: 9be62fe1-26f9-440f-8a9c-80e3e40c0612 --> THIS: 9622884e-3cd7-4219-af7c-b57584cf3396
PREV: 9622884e-3cd7-4219-af7c-b57584cf3396 --> THIS: b25c6598-bdfd-4d85-876e-47c8bdbdb9d4
PREV: b25c6598-bdfd-4d85-876e-47c8bdbdb9d4 --> THIS: 9f83a483-b33e-4259-a798-41c3de239dc8
PREV: 9f83a483-b33e-4259-a798-41c3de239dc8 --> THIS: 2448dee0-544a-411d-a717-d4d74d40ebcb
PREV: 2448dee0-544a-411d-a717-d4d74d40ebcb --> THIS: c0063c62-f9f4-40d1-9405-27a04dfe63ea
PREV: c0063c62-f9f4-40d1-9405-27a04dfe63ea --> THIS: 686b0701-081a-409b-8bbc-080aea6c3308
PREV: 686b0701-081a-409b-8bbc-080aea6c3308 --> THIS: 6148ee04-ba88-4799-922b-1eca538d5090
PREV: 6148ee04-ba88-4799-922b-1eca538d5090 --> THIS: fe0032fe-f784-48e3-81ed-ca792c3fa1ef
PREV: fe0032fe-f784-48e3-81ed-ca792c3fa1ef --> THIS: 887be00e-0633-4a00-a58d-193c4b4934d8
PREV: 887be00e-0633-4a00-a58d-193c4b4934d8 --> THIS: 208f3113-fcbe-4369-a47f-f69c93c17930
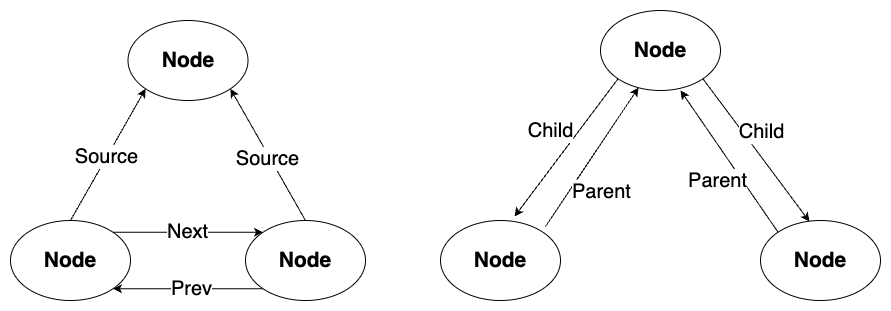
Documentをチャンク分割して作成されたNode(TextNode)にはSOURCE NodeとしてDocument(のID)が紐づく(DocumentオブジェクトもTextNodeのサブクラスなので。)そして、各Nodeは分割された順番にNEXT Node/PREV Nodeというリレーションができる。これによりDocumentとNodeの親子関係、Node間の前後関係が構築され、いろいろなインデックス手法で活用されるということらしい。
なお、Node間の関係を抽象化するNodeRelationshipには上記以外にもPARENTとCHILDというものがある。今回使用したSentenceSplitterはおそらくそれを使わないのだろうと思う。
これらを含めて、Nodeを手動で作成することができる。
from llama_index.schema import TextNode, NodeRelationship, RelatedNodeInfo
s_node = TextNode(text="source_node_text", id_="s")
node1 = TextNode(text="node_1_text", id_="n1")
node2 = TextNode(text="node_2_text", id_="n2")
p_node = TextNode(text="parent_node_text", id_="p")
c_node1 = TextNode(text="child_node1_text", id_="c1")
c_node2 = TextNode(text="child_node2_text", id_="c2")
node1.relationships[NodeRelationship.SOURCE] = RelatedNodeInfo(
node_id=s_node.node_id
)
node2.relationships[NodeRelationship.SOURCE] = RelatedNodeInfo(
node_id=s_node.node_id
)
node1.relationships[NodeRelationship.NEXT] = RelatedNodeInfo(
node_id=node2.node_id
)
node2.relationships[NodeRelationship.PREVIOUS] = RelatedNodeInfo(
node_id=node1.node_id
)
p_node.relationships[NodeRelationship.CHILD] = [
RelatedNodeInfo(node_id=c_node1.node_id),
RelatedNodeInfo(node_id=c_node2.node_id),
]
c_node1.relationships[NodeRelationship.PARENT] = RelatedNodeInfo(
node_id=p_node.node_id
)
c_node2.relationships[NodeRelationship.PARENT] = RelatedNodeInfo(
node_id=p_node.node_id
)
nodes = [s_node, node1, node2, p_node, c_node1, c_node1]
TextNodeでNodeオブジェクトを作成し、NodeRelationshipとRelatedNodeInfoでNode間のリレーションを設定する。作成されたNodeは以下となった。
nodes
[
TextNode(
id_='s',
embedding=None,
metadata={},
excluded_embed_metadata_keys=[],
excluded_llm_metadata_keys=[],
relationships={},
hash='68f90b1596581a2ce598b99aec41b11322074082746302a7a0ca1a1ab741db1a',
text='source_node_text',
start_char_idx=None, end_char_idx=None,
text_template='{metadata_str}\n\n{content}',
metadata_template='{key}: {value}',
metadata_seperator='\n'
),
TextNode(
id_='n1',
embedding=None,
metadata={},
excluded_embed_metadata_keys=[],
excluded_llm_metadata_keys=[],
relationships={
<NodeRelationship.SOURCE: '1'>: RelatedNodeInfo(node_id='s', node_type=None, metadata={}, hash=None),
<NodeRelationship.NEXT: '3'>: RelatedNodeInfo(node_id='n2', node_type=None, metadata={}, hash=None)
},
hash='1e6386a57a2e0a24b8c412c4067cd6e11fb7ae38d95b32517448822ea2b2f945',
text='node_1_text',
start_char_idx=None,
end_char_idx=None,
text_template='{metadata_str}\n\n{content}',
metadata_template='{key}: {value}',
metadata_seperator='\n'
),
TextNode(
id_='n2',
embedding=None,
metadata={},
excluded_embed_metadata_keys=[],
excluded_llm_metadata_keys=[],
relationships={
<NodeRelationship.SOURCE: '1'>: RelatedNodeInfo(node_id='s', node_type=None, metadata={}, hash=None),
<NodeRelationship.PREVIOUS: '2'>: RelatedNodeInfo(node_id='n1', node_type=None, metadata={}, hash=None)
},
hash='a5d11ae0373cfae98b8a82da0f9549d7f06aeb6cfd1302610deb931cb78d553b',
text='node_2_text',
start_char_idx=None,
end_char_idx=None,
text_template='{metadata_str}\n\n{content}',
metadata_template='{key}: {value}',
metadata_seperator='\n'
),
TextNode(
id_='p', embedding=None, metadata={},
excluded_embed_metadata_keys=[],
excluded_llm_metadata_keys=[],
relationships={
<NodeRelationship.CHILD: '5'>: [
RelatedNodeInfo(node_id='c1', node_type=None, metadata={}, hash=None),
RelatedNodeInfo(node_id='c2', node_type=None, metadata={}, hash=None)
]
},
hash='d42b3605849d74225e1b5623c9b50bb5ec9a1376ad3299c1e425dcbd5bac3ea8',
text='parent_node_text',
start_char_idx=None,
end_char_idx=None,
text_template='{metadata_str}\n\n{content}',
metadata_template='{key}: {value}',
metadata_seperator='\n'
),
TextNode(
id_='c1',
embedding=None,
metadata={},
excluded_embed_metadata_keys=[],
excluded_llm_metadata_keys=[],
relationships={
<NodeRelationship.PARENT: '4'>: RelatedNodeInfo(node_id='p', node_type=None, metadata={}, hash=None)
},
hash='39645a062880a4e7a01a5eccab22b0b105d6803e8c0c5fbba2eb021fc771adda',
text='child_node1_text',
start_char_idx=None,
end_char_idx=None,
text_template='{metadata_str}\n\n{content}',
metadata_template='{key}: {value}',
metadata_seperator='\n'
),
TextNode(
id_='c1', embedding=None, metadata={}, excluded_embed_metadata_keys=[], excluded_llm_metadata_keys=[],
relationships={
<NodeRelationship.PARENT: '4'>: RelatedNodeInfo(node_id='p', node_type=None, metadata={}, hash=None)
},
hash='39645a062880a4e7a01a5eccab22b0b105d6803e8c0c5fbba2eb021fc771adda',
text='child_node1_text',
start_char_idx=None,
end_char_idx=None,
text_template='{metadata_str}\n\n{content}',
metadata_template='{key}: {value}',
metadata_seperator='\n'
)
]
ちゃんと理解できてないかもだけど、こういう関係性なのだと思う。もしかしたら間違ってるかもだけど。
Nodeにもmetadetaは付与できる。
from llama_index.schema import TextNode, NodeRelationship, RelatedNodeInfo
node = TextNode(text="node_text", id_="n1")
node.metadata={"fiile_name":"node_file"}
node
TextNode(
id_='n1',
embedding=None,
metadata={'fiile_name': 'hoge'},
excluded_embed_metadata_keys=[],
excluded_llm_metadata_keys=[],
relationships={},
hash='1e6386a57a2e0a24b8c412c4067cd6e11fb7ae38d95b32517448822ea2b2f945',
text='node_1_text',
start_char_idx=None,
end_char_idx=None,
text_template='{metadata_str}\n\n{content}',
metadata_template='{key}: {value}',
metadata_seperator='\n'
)
NodeそのもののメタデータはSimpleFileReader(+NodeParser)だとDocumentから継承されたりもするけど。
なお、リレーションにメタデータを設定することもできる。
c_node = TextNode(text="c_node_text", id_="p1")
c_node.relationships[NodeRelationship.PARENT] = RelatedNodeInfo(
node_id=node.node_id, metadata={"key": "val"}
)
c_node
TextNode(
id_='p1'
embedding=None,
metadata={},
excluded_embed_metadata_keys=[],
excluded_llm_metadata_keys=[],
relationships={
<NodeRelationship.PARENT: '4'>:
RelatedNodeInfo(node_id='n1', node_type=None, metadata={'key': 'val'}, hash=None)
},
hash='ca570a8c46bd8427ae388df85e927c24478e770b047a5d08cbc9f045873f9e5a',
text='c_node_text',
start_char_idx=None,
end_char_idx=None,
text_template='{metadata_str}\n\n{content}',
metadata_template='{key}: {value}',
metadata_seperator='\n')
ちょっと使いどころまでは想像できないけども。
IDのカスタマイズも。ちょっとここはドキュメント通りではなかった。
print(node.node_id)
n1
node.id_ = "ノードID変えてみた" # node.node_idは参照はできるが、変更時はnode.id_じゃないとエラーになる
print(node.node_id)
ノードID変えてみた
普段遣いだとここまで気にしなくて良さそうだけども、ちょっと複雑なインデックスで必要になりそうな気がしたのでやってみた次第。