[論文] テスト時マッチング: LLMベースのロールプレイング言語エージェントにおける個性、記憶、言語スタイルの分離
論文
alphaXivのまとめから引用
テスト時マッチング: LLMベースのロールプレイング言語エージェントにおける個性、記憶、言語スタイルの分離
はじめに
ロールプレイング言語エージェント(RPLA)は、人工知能において急速に進化している分野であり、大規模言語モデルが、架空のキャラクターであれ実在の人物であれ、その性格、知識、特徴的な話し方を模倣することで、特定のキャラクターを体現するように設計されています。これらのエージェントを構築するための現在の手法は、重大な課題に直面しています。ファインチューニング手法は、広範なキャラクター固有のデータと計算リソースを必要とする一方、単純なプロンプト技術では、深く一貫したキャラクターの没入感を実現できないことがよくあります。
referred from https://arxiv.org/pdf/2507.16799
TTM Framework Overview図1: Test-Time-Matchingフレームワークのパイプライン。抽出(緑)、分析(青)、会話(赤)の3つの主要なフェーズを示す。システムはテキストからキャラクター情報を自動的に抽出し、性格と言語スタイルを分析し、会話中に3段階の生成プロセスを使用する。本稿では、トレーニング不要のフレームワークであるTest-Time-Matching(TTM)を紹介します。これは、キャラクターの性格、記憶、および言語スタイルを明示的に分離するという基本的な洞察を通じて、これらの制限に対処します。「何を言うか」(認知的傾向)と「どのように言うか」(言語的表現)を分離することで、TTMは、キャラクター固有のファインチューニングを必要とせずに、高い忠実度を達成しながら、より制御可能で解釈しやすいロールプレイングを可能にします。
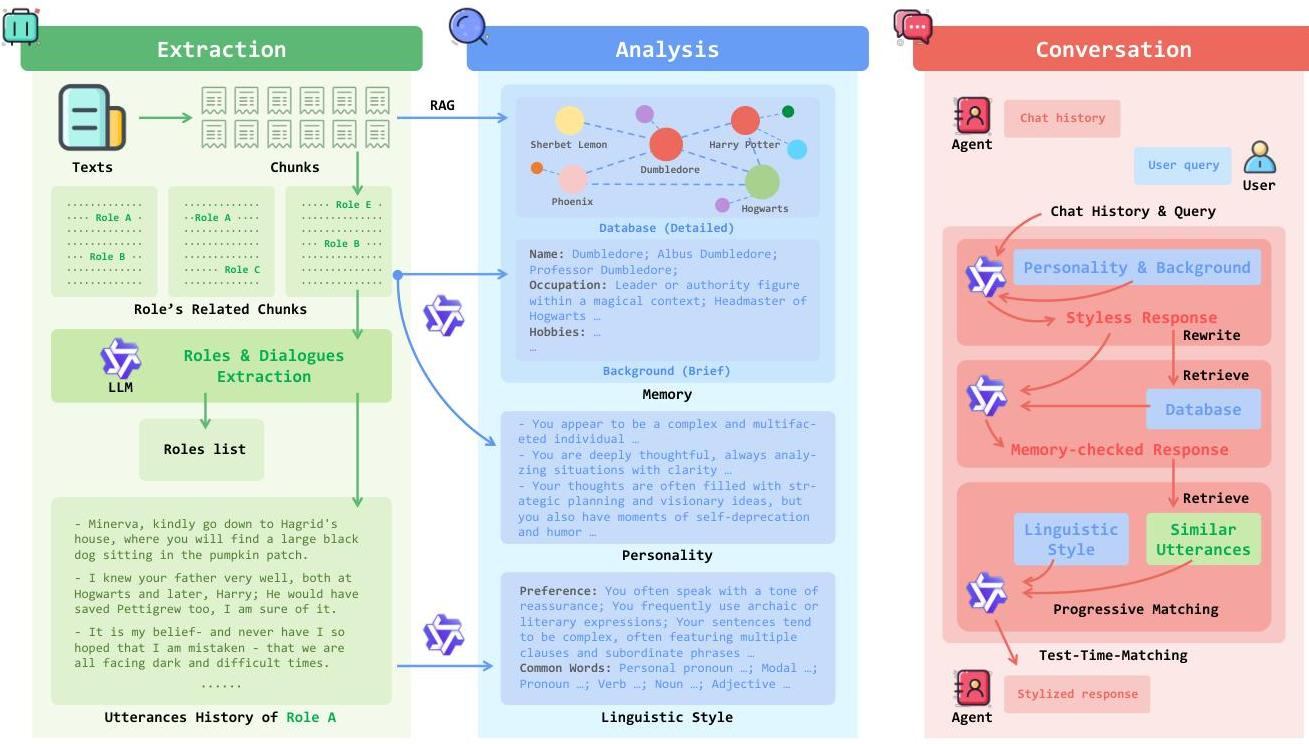
ポイントは、ペルソナを「個性」「記憶」「言語スタイル」に分けて抽出し、それぞれが独立した生成パイプラインで応答を順に書き換えていって、最終的な回答を生成するというところ。
論文中の図1を日本語化にしたもの(英語の細かい語感までは訳せてない)

referred from https://arxiv.org/pdf/2507.16799 and translated into Japanese by kun432
図1: RPLAにおける人格、記憶、言語スタイルの分離。TTMは、特定のキャラクター向けに高忠実度の応答を生成するため、構造化された3段階の生成パイプラインを採用している。(ハーマイオニーは、『ハリー・ポッター』シリーズにおいて、特にS.P.E.W.を推進する際などに、真剣で堅実、確固たる態度とやや説教臭いトーンで知られている。)
実際にやる場合は事前準備が必要になり、それらを含めた全体フローが論文中の図3になる。こちらも日本語に訳した。

referred from https://arxiv.org/pdf/2507.16799 and translated into Japanese by kun432
図3: パイプラインの概要。TTMはまず、テキスト入力から役割に関連する情報を自動的に抽出する。その後、分離された特徴量(性格、記憶、言語スタイル)を分析する。ロールプレイ中、TTMはテスト時スケーリングを採用し、構造化された3段階の生成パイプラインを通じて高忠実度性能を実現する。
これを以下の手法と比較している。以下はalphaXivとのチャットの結果(Gemini 2.5 Pro)
比較対象は、大きく分けて 「ロールプレイングに特化した手法」 と 「汎用的な大規模言語モデル(LLM)」 の2種類です。
- ロールプレイングに特化した手法(RPLA methods)
これらは、特定のキャラクターになりきって対話するために、特別な工夫が凝らされたモデルです。論文では以下の2つの手法が挙げられています。
- ChatHaruhi: プロンプト技術を駆使してキャラクターを再現する手法です。論文の5ページにあるように、これは「プロンプティング(Prompting)」に基づくアプローチで、モデルの追加学習(ファインチューニング)なしに、文脈やプロンプトの工夫だけでキャラクターの一貫性を実現しようとします。この研究は「ChatHaruhi: Reviving Anime Character in Reality via Large Language Model」で詳しく説明されています。
- CoSER: こちらはキャラクターのデータセットを用いてモデルを学習させる「パラメトリックトレーニング(Parametric Training)」に基づくアプローチです。特定のキャラクターの対話データなどを使い、モデルをファインチューニングすることで、そのキャラクターらしい応答を生成することを目指します。
- 汎用的な大規模言語モデル(Universal LLMs)
特定の役割に特化していない、一般的な対話能力を持つLLMです。これらを比較対象とすることで、提案手法TTMが汎用モデルに比べて、あるいは汎用モデルをベースとした場合にどれだけ性能が向上するかを示しています。論文では以下のモデルが比較されています。
- GPT-4o: OpenAIによって開発されたモデルです。詳細はシステムカード「Gpt-4o system card」で公開されています。
- Gemini-2.5-pro: Googleによって開発されたモデルです。オンラインの情報をリアルタイムで参照する「オンライン・グラウンディング」機能を用いて性能を高めていると論文中で言及されています。詳細は「Gemini 2.5」で確認できます。
- Qwen-3: Alibaba Cloudによって開発されたモデルシリーズです。この研究では、ベースモデルとして使用されているQwen-3-32Bと、さらに大規模なQwen-3-235B-A22Bの2つのバージョンが評価対象となっています。詳細はテクニカルレポート「Qwen3 technical report」に記載されています。
比較結果のまとめ。論文中にもグラフがある。
端的に言うと、提案手法のTTM(Test-Time-Matching)は、比較対象となった他のすべての手法をほとんどの評価指標で上回り、特にキャラクターの一貫性と知識の正確さにおいて優れた性能を示しました。
以下に、評価結果の詳細をまとめます。
総合的な評価
論文の 表1(6ページ)と図2・図7(2ページ、7ページ) に示されている通り、TTMは3種類の評価者(LLMによる自動評価、一般参加者、言語学の専門家)すべてから、総合的に最も高い評価を受けました。特に、以下の2つの指標で際立っています。
-キャラクターの一貫性 (Consistency of Persona, C.P.): キャラクターの性格や話し方がどれだけ一貫しているかという指標です。TTMはすべての評価者から最高スコアを獲得しました。
- 知識の正確性 (Accuracy of Knowledge, A.K.): キャラクターの背景(物語など)に基づいた知識がどれだけ正確かという指標です。こちらもTTMが最高スコアを記録しました。
詳細な比較結果
- 既存のロールプレイング特化手法(ChatHaruhi, CoSER)との比較
プロンプトベースのChatHaruhiや、学習ベースのCoSERと比較して、TTMはすべての指標で明確に優れた結果を出しました。これは、TTMが「人格」「記憶」「言語スタイル」を分離して扱うアプローチが、単純なプロンプティングや統合的な学習よりも効果的であることを示唆しています。- 汎用大規模言語モデル(GPT-4o, Gemini-2.5-proなど)との比較
TTMは、非常に高性能な汎用LLMと比較しても、ロールプレイングという特定のタスクにおいて、より高い忠実度を達成しました。
- TTM vs Gemini-2.5-pro: Gemini-2.5-proはオンライン情報を参照する機能により非常に高い性能を示しましたが、C.P.とA.K.のスコアではTTMが上回りました。
- TTMのベースモデルからの性能向上: 最も注目すべき点は、TTMがベースとして利用した 「Qwen-3-32B」単体の性能を劇的に向上させている ことです。表1を見ると、ベースモデルのスコアは他の汎用LLMに比べて見劣りしますが、TTMのフレームワークを適用することで、全手法中トップクラスの性能に引き上げられています。これは、TTMが追加のモデル学習(ファインチューニング)なしで、既存モデルの能力を最大限に引き出す強力な手法であることを示しています。
- 「対話の質(Quality of Conversation, Q.C.)」に関する分析
一方で、「対話の質」の指標においては、TTMは非常に高い評価を得たものの、言語学の専門家による評価ではGemini-2.5-proにわずかに劣る結果となりました。
論文ではその理由を、 TTMが生成する応答は情報量が豊富である反面、長すぎてしまい、日常会話としては不自然に感じられたり、読解に疲労感を与えたりした可能性がある と分析しています(6ページ)。これはTTMの今後の改善点として挙げられています。結論
総括すると、TTMは追加学習なしの「テスト時」の処理だけで、既存のLLMの能力を大幅に強化し、非常に忠実で一貫性のあるロールプレイング対話を実現する強力なフレームワークであることが、厳密な比較評価によって実証されたと言えます。
ファインチューニング等のトレーニング不要で、より再現度・一貫性の高いキャラクターを小型モデルでも構築が可能、というのがメリットになるのかなと思うが、複数回の推論パイプラインを組むことになるので、普通に考えると推論時間がかかることになる。このあたりは課題にも書いてあるとおり。
限界と今度の可能性
TTMはその利点にもかかわらず、いくつかの課題に直面しています。
- 計算オーバーヘッド: 3段階のパイプラインは追加の推論コストを伴いますが、著者らはこのトレードオフにより、より小型のモデルが高いパフォーマンスを達成できると主張しています。
- 情報管理: すべてのキャラクターに対して単一の書籍全体の記憶データベースを使用すると、情報過多や知識の誤用につながる可能性があり、無関係な詳細を取り込んだり、物語の情報を特定のキャラクターに誤って帰属させたりすることがあります。
- 時間的コヒーレンス: 現在の検索方法は時系列順よりも関連性を優先するため、キャラクターが時系列外のイベントを参照する可能性があります。
- 応答の長さ: TTMが詳細な応答を生成する傾向は、情報が豊富である一方で、会話の自然さに影響を与える可能性があります。
プロンプトで限界があるならば、ファインチューニングしたいところだけど、それをパイプライン+推論でカバーするので、レイテンシーが犠牲になる、というところか。
推論ステップを分けて、それぞれがやることを細かく分ける、という意味では、マルチエージェントみたいな考え方とにているのかもしれない。