gradioことはじめ
もっぱらPythonのWebフロントエンドはStreamlitを使うことが多いのだけど、もっとライトにや里太陽なケースで良さそうなので、Gradioも触ってみるメモ。過去何度か触ったことはあるけど、調べずに適当にやってたので、真面目にQuickstartやってみる。
Quickstartにしたがってみる
ローカルのUbuntuサーバでやる。仮想環境作ったところから。
gradioインストール
$ pip install gradio
Quickstartのサンプルコード。
import gradio as gr
def greet(name, intensity):
return "Hello, " + name + "!" * int(intensity)
demo = gr.Interface(
fn=greet,
inputs=["text", "slider"],
outputs=["text"],
)
demo.launch()
demo.launch()は デフォだとlocalhostで待ち受ける。自分の場合は、LAN内のUbuntuサーバなので、LAN内のIPを指定するか、まるっと待ち受けるようにする必要があった。
(snip)
demo.launch(server_name="0.0.0.0")
外部に公開したい場合はshare=TrueをセットするとURLが発行される。
(snip)
demo.launch(share=True)
どうやらトンネル張ってるみたい。
whether to create a publicly shareable link for the gradio app. Creates an SSH tunnel to make your UI accessible from anywhere. If not provided, it is set to False by default every time, except when running in Google Colab. When localhost is not accessible (e.g. Google Colab), setting share=False is not supported.
では立ち上げてみる。
$ python app.py
Running on local URL: http://0.0.0.0:7860
To create a public link, set `share=True` in `launch()`.
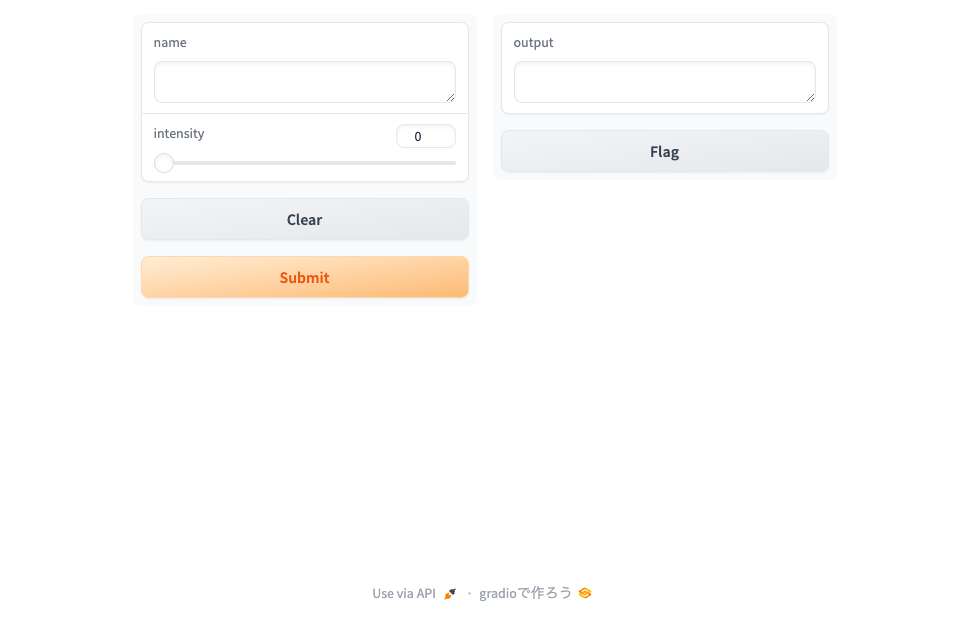
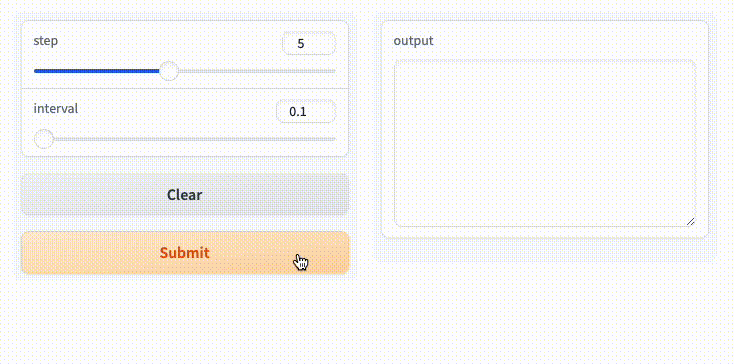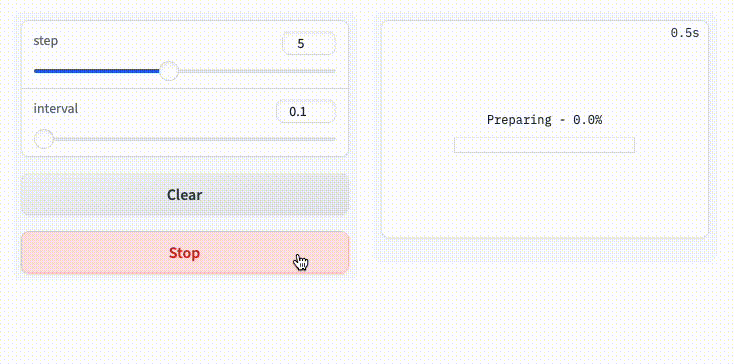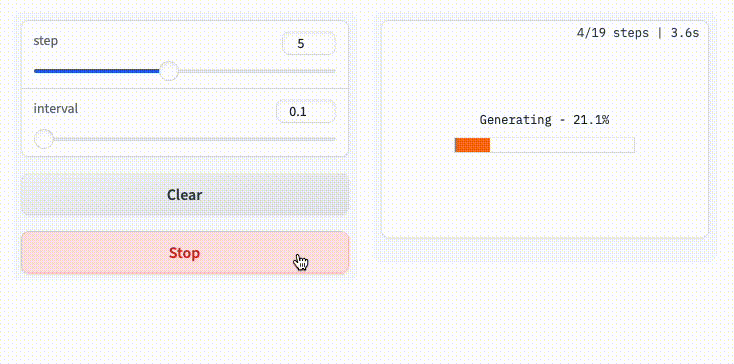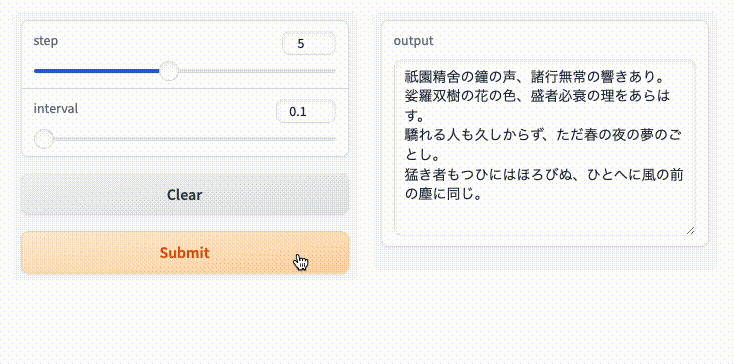
ブラウザでアクセスしてみるとこんな画面になっている。
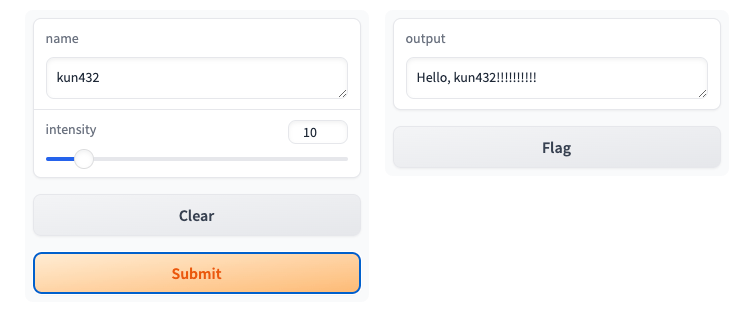
適当に入力してSubmitしてみるとこうなる。
-
gr.Interfaceでインタフェースクラスからインスタンス初期化 -
gr.Interfaceは、「入力」を「関数」に渡してその結果を「出力」する。 - 入力と出力のインタフェースをgradioのコンポーネントとして設定する。
なるほど。こんな感じ。
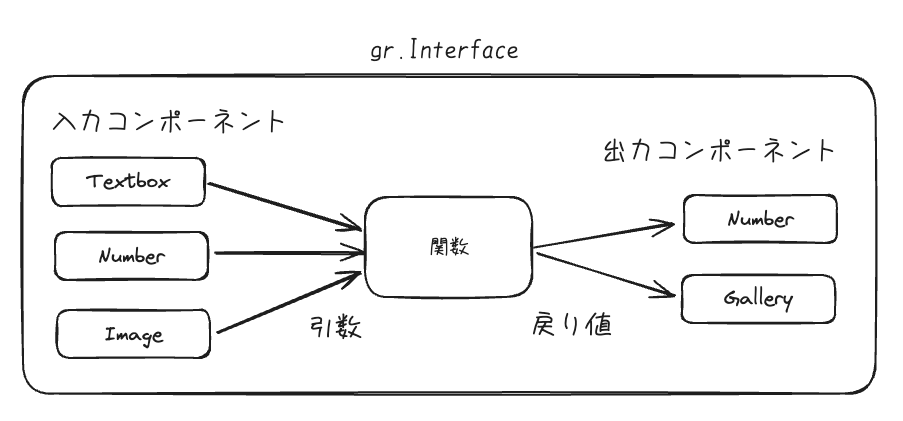
これの公式の図は以下のページにある。
コンポーネントは上のページで紹介されているようにたくさんあるので、これでUIを組み立てればよいと。
あと、Gradioで何ができるか?というところで2つの例が紹介されている。
-
gr.ChatInterfaceというチャット専用のインタフェースクラスを使ったチャットボット- text-generation-webuiのようなやつ(text-generation-webuiは多分もっと複雑だと思うけども)
-
gr.Blocksを使ったカスタムなレイアウトをもつ独自アプリ- stable-diffusion-webuiのようなやつ
gradioのコア機能を見ていく。コンポーネントは割愛して、気になったところだけ。
ストリーミング
ストリーミング出力の場合はジェネレータを使う。テキストをLLMのストリーミングっぽく出力するサンプルを書いてみた。
import gradio as gr
import time
text="""\
祇園精舍の鐘の声、諸行無常の響きあり。
娑羅双樹の花の色、盛者必衰の理をあらはす。
驕れる人も久しからず、ただ春の夜の夢のごとし。
猛き者もつひにはほろびぬ、ひとへに風の前の塵に同じ。
"""
def fake_completion(step, interval):
for i in range(0, len(text), step):
time.sleep(interval)
yield text[0:i+step]
demo = gr.Interface(
fake_completion,
inputs=[
gr.Slider(1, 10, 3, step=1),
gr.Slider(0.1, 1.0, 0.5, step=0.1),
],
outputs="textarea",
allow_flagging='never'
)
demo.launch(server_name="0.0.0.0")
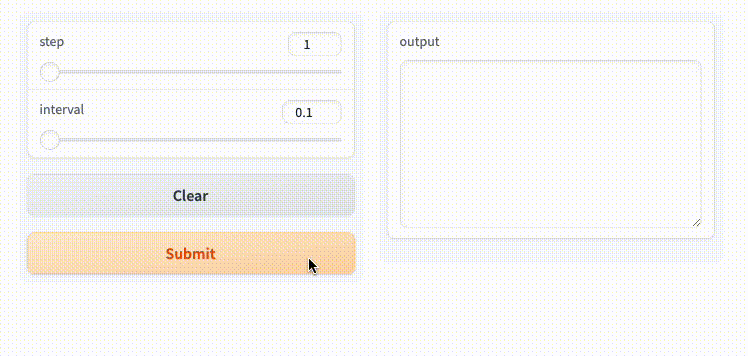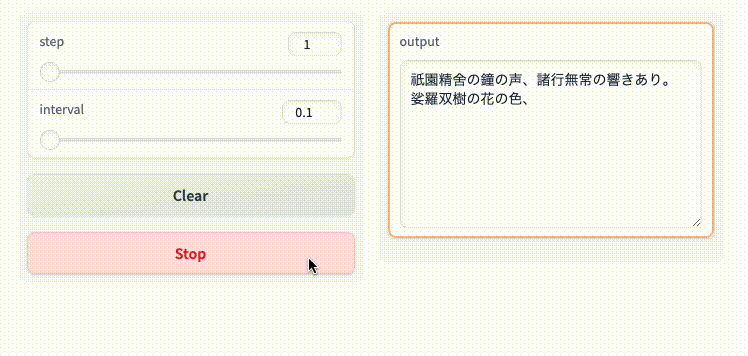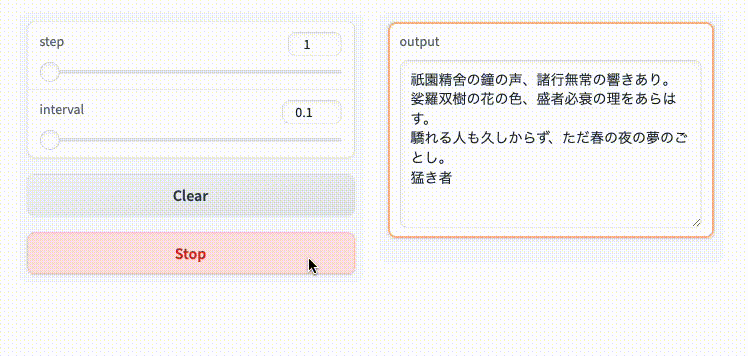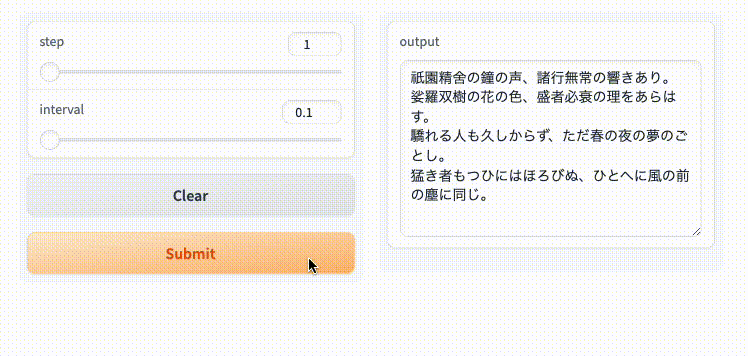
入力をストリーミングで受けることもできるみたいだけど割愛。以下を参照。
キューイング
リクエストををキューイングして順番に処理させることができる。上のコードにキューイングを追加してみる。
(snip)
demo = gr.Interface(
fake_completion,
inputs=[
gr.Slider(1, 10, 3, step=1),
gr.Slider(0.1, 1.0, 0.5, step=0.1),
],
outputs="textarea",
allow_flagging='never'
).queue(default_concurrency_limit=1) # キューイングを追加
(snip)
ブラウザを2つ立ち上げて両方実行してみると、後から実行したほうは先に実行した方が終わるまで待ち状態となる。
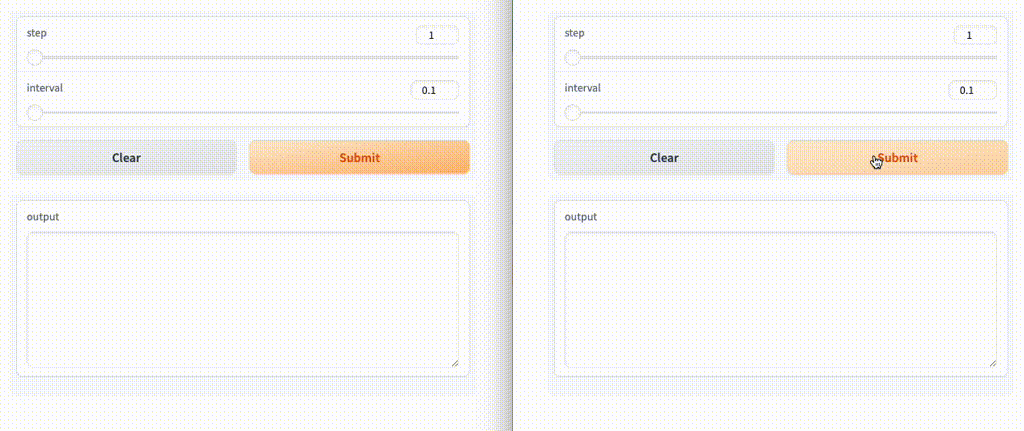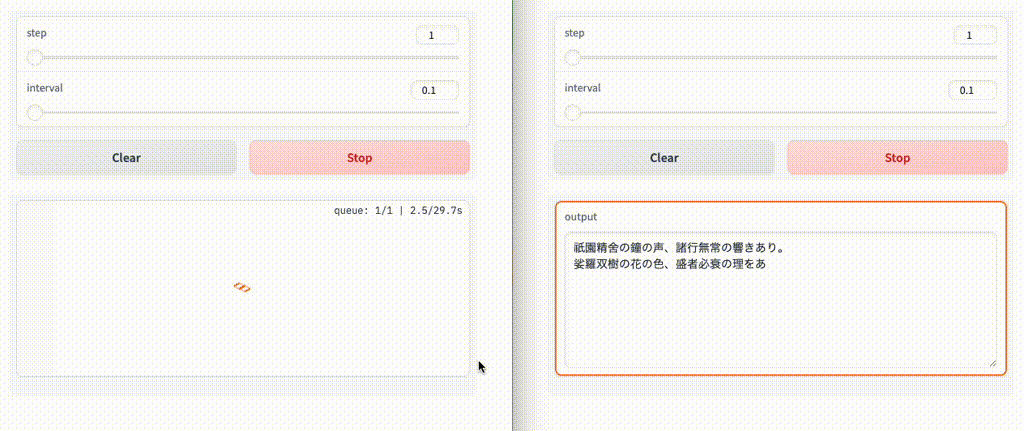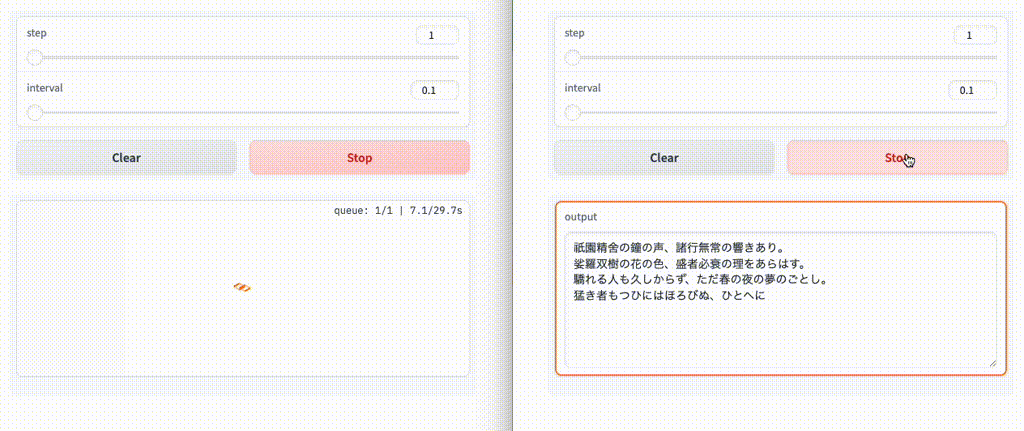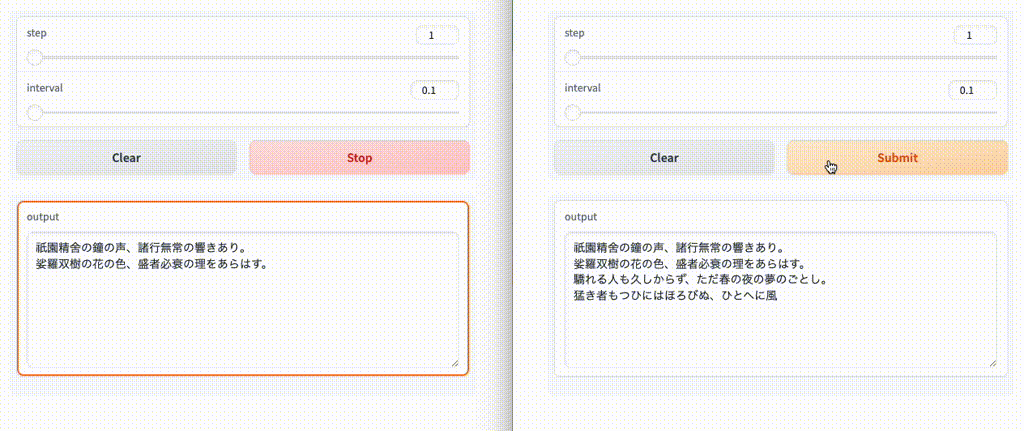
なお、デフォルトは1みたいなので、上記は実は意味がない。
エラー出力
エラー出力を行える。テキストボックスを追加して、テキストボックスが入力されていなければエラーとしてみる。
import gradio as gr
import time
text="""\
祇園精舍の鐘の声、諸行無常の響きあり。
娑羅双樹の花の色、盛者必衰の理をあらはす。
驕れる人も久しからず、ただ春の夜の夢のごとし。
猛き者もつひにはほろびぬ、ひとへに風の前の塵に同じ。
"""
def fake_completion(name, step, interval):
if name == "":
raise gr.Error("名前を入力して下さい。")
greeting = f"こんにちは、{name}さん。平家物語の冒頭を出力します。\n\n"
streaming_text = greeting + text
for i in range(0, len(streaming_text), step):
time.sleep(interval)
yield streaming_text[0:i+step]
demo = gr.Interface(
fake_completion,
inputs=[
"text",
gr.Slider(1, 10, 3, step=1),
gr.Slider(0.1, 1.0, 0.5, step=0.1),
],
outputs="textarea",
allow_flagging='never'
).queue(default_concurrency_limit=1)
demo.launch(server_name="0.0.0.0")
テキストボックスに入力しなければこうなる。
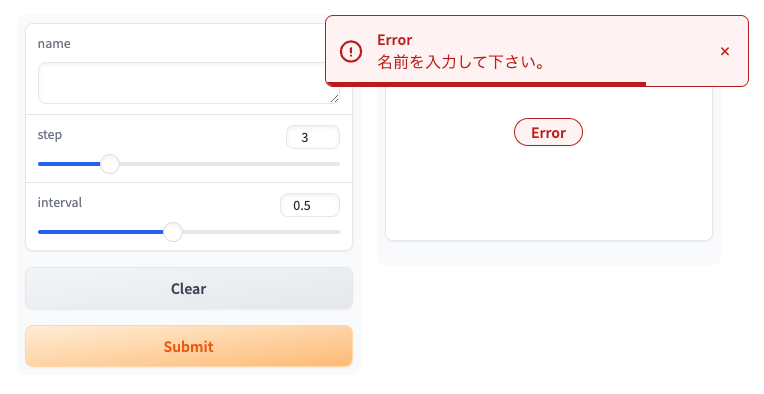
gr.Error以外にもgr.Warningとかgr.Infoが使える。なお、raiseしなければ表示されるだけ。
プログレスバー
処理経過をプログレスバーで表示することができる。
import gradio as gr
import time
text="""\
祇園精舍の鐘の声、諸行無常の響きあり。
娑羅双樹の花の色、盛者必衰の理をあらはす。
驕れる人も久しからず、ただ春の夜の夢のごとし。
猛き者もつひにはほろびぬ、ひとへに風の前の塵に同じ。
"""
def fake_completion(step, interval, progress=gr.Progress()):
return_text = ""
progress(0, desc="Preparing")
time.sleep(3)
for i in progress.tqdm(range(0, len(text), step), desc="Generating"):
time.sleep(interval)
return_text = text[0:i+step]
yield return_text
demo = gr.Interface(
fake_completion,
inputs=[
gr.Slider(1, 10, 3, step=1),
gr.Slider(0.1, 1.0, 0.5, step=0.1),
],
outputs="textarea",
allow_flagging='never'
).queue(default_concurrency_limit=1)
demo.launch(server_name="0.0.0.0")
tqdmでラップできるのは便利。
スタイル
テーマを変えて見た目を変えることができる。
(snip)
demo = gr.Interface(
fake_completion,
inputs=[
gr.Slider(1, 10, 3, step=1),
gr.Slider(0.1, 1.0, 0.5, step=0.1),
],
outputs="textarea",
allow_flagging='never',
theme=gr.themes.Monochrome() # themeを指定
).queue(default_concurrency_limit=1)
(snip)
Monochromeだとこんな感じになる。
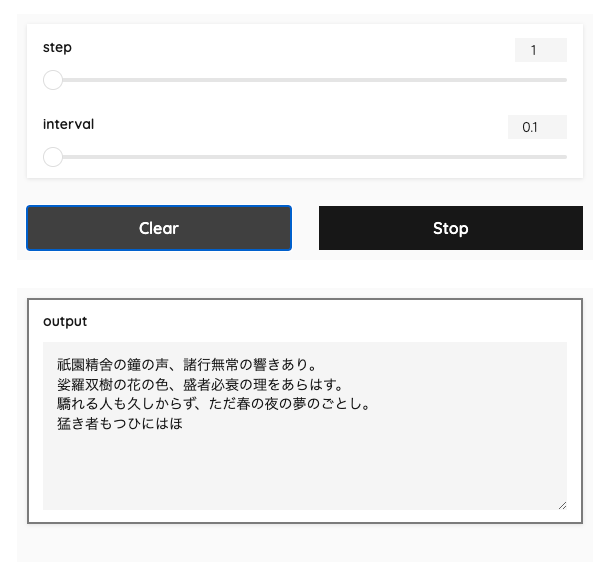
その他のテーマは以下。なお、テーマは自作することもできるらしいし、CSSを直接渡して変更したりもできるらしい。
バッチ
このサンプルコードをどう使えばいいのか、全然わからない。。。
gr.Interfaceの方を実行してみるとValueError: No such component or layout: outputとかなるし、gr.Blockの方を実行してみても何がバッチなんだろうか?という感じ。あくまでもサンプル、ってことなのかな?
ちょっと良い例も思いつかないのでパス。
ということで、チャットをやる。これが目的。
gr.ChatInterfaceを使う。
import gradio as gr
import random
def random_response(message, history):
return random.choice(["Yes", "No"])
demo = gr.ChatInterface(random_response)
demo.launch(server_name="0.0.0.0")
こんな感じで、めちゃめちゃシンプルにやり取りができてしまうな。
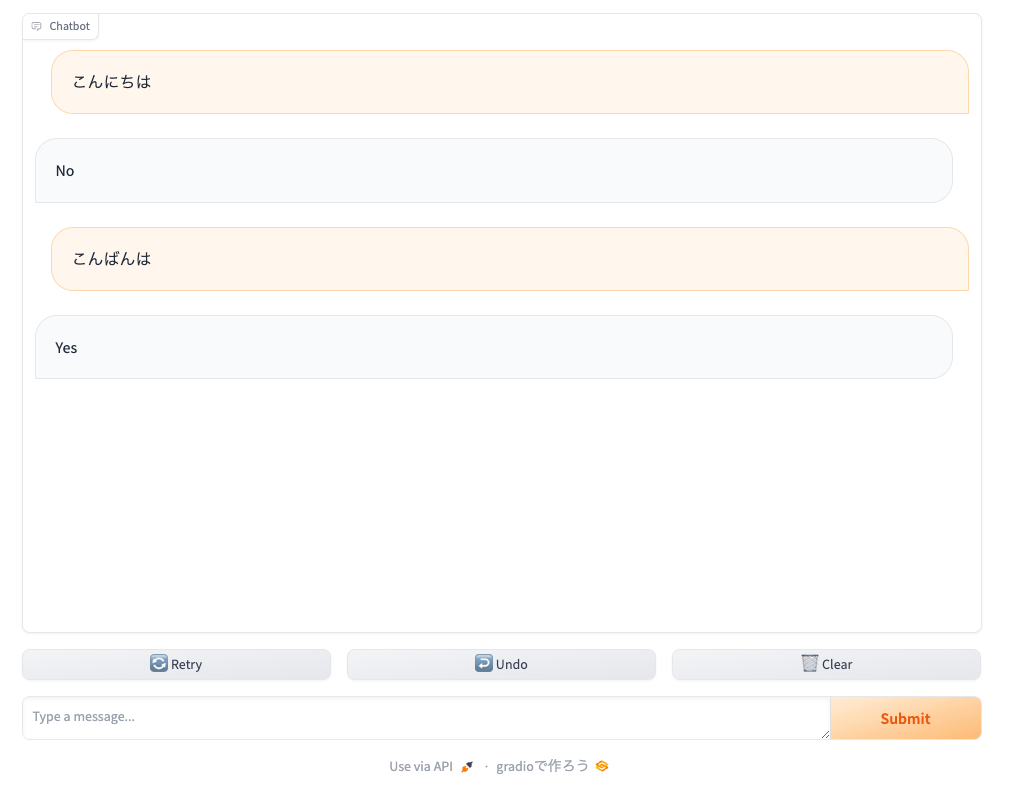
gr.Interfaceだと入出力コンポーネントと関数をマッピングしてあげないといけなかったけど、gr.ChatInterfaceでは、関数にわたってくるのは以下だけとなる。
-
message- ユーザの入力
-
history- いわゆる会話履歴。前回までのユーザの入力とチャットボットからの出力のペアを配列にしたもの。
少しデバッグ的に出力してみる。
import gradio as gr
import random
def random_response(message, history):
print("===== query =====")
print(message)
print("===== history =====")
print(history)
return random.choice(["Yes", "No"])
demo = gr.ChatInterface(random_response)
demo.launch(server_name="0.0.0.0")
例えば、こんな感じでやり取りしたとする。
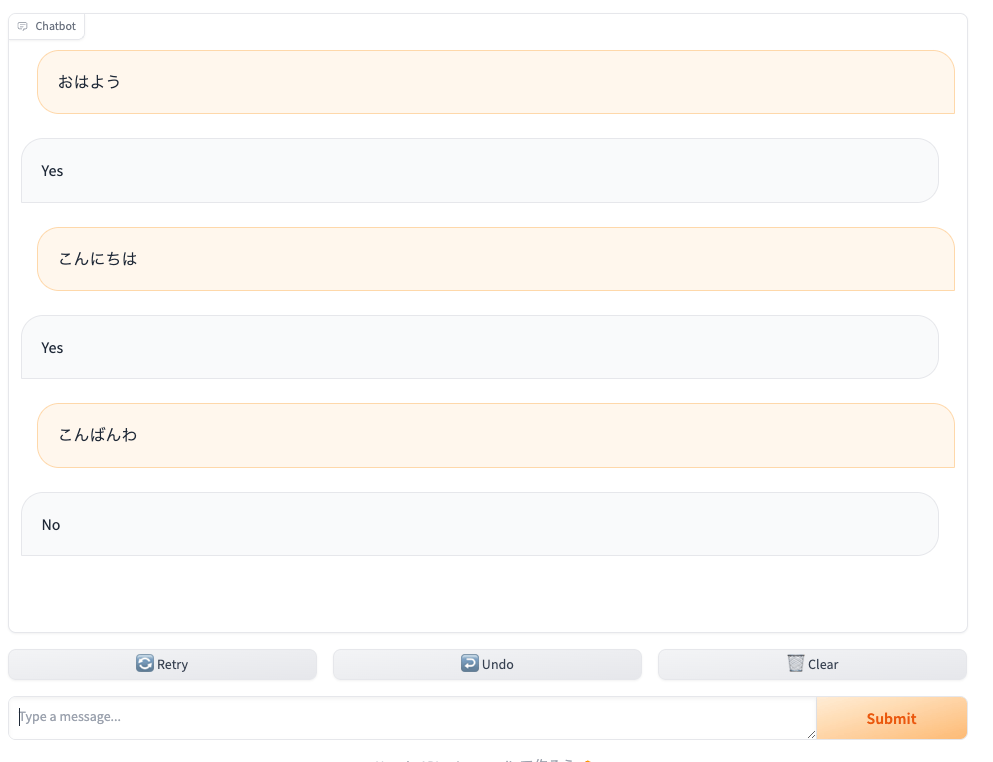
コンソールを見るとこうなる。
===== query =====
おはよう
===== history =====
[]
===== query =====
こんにちは
===== history =====
[['おはよう', 'Yes']]
===== query =====
こんばんわ
===== history =====
[['おはよう', 'Yes'], ['こんにちは', 'Yes']]
ストリーミングもできる。上でやったのと同じようにジェネレータを使えば良い。
import gradio as gr
import random
import time
import gradio as gr
def slow_echo(message, history):
streaming_message = f"あなたは「{message}」と言いました。"
for i in range(len(streaming_message)):
time.sleep(0.2)
yield streaming_message[:i+1]
demo = gr.ChatInterface(slow_echo)
demo.launch(server_name="0.0.0.0")

色々カスタマイズもできる。
import gradio as gr
import random
import time
import gradio as gr
def slow_echo(message, history):
streaming_message = f"あなたは「{message}」と言いました。"
for i in range(len(streaming_message)):
time.sleep(0.2)
yield streaming_message[:i+1]
demo = gr.ChatInterface(
slow_echo,
chatbot=gr.Chatbot(height=600),
textbox=gr.Textbox(placeholder="入力して下さい。", container=False, scale=7),
title="ストリーミング オウム返し",
description="なんでもオウム返しします。",
theme="soft",
examples=["おはよう", "こんにちは", "こんばんは"],
cache_examples=True,
retry_btn="再度送信",
undo_btn="前回のメッセージを削除",
clear_btn="クリア",
)
demo.launch(server_name="0.0.0.0")
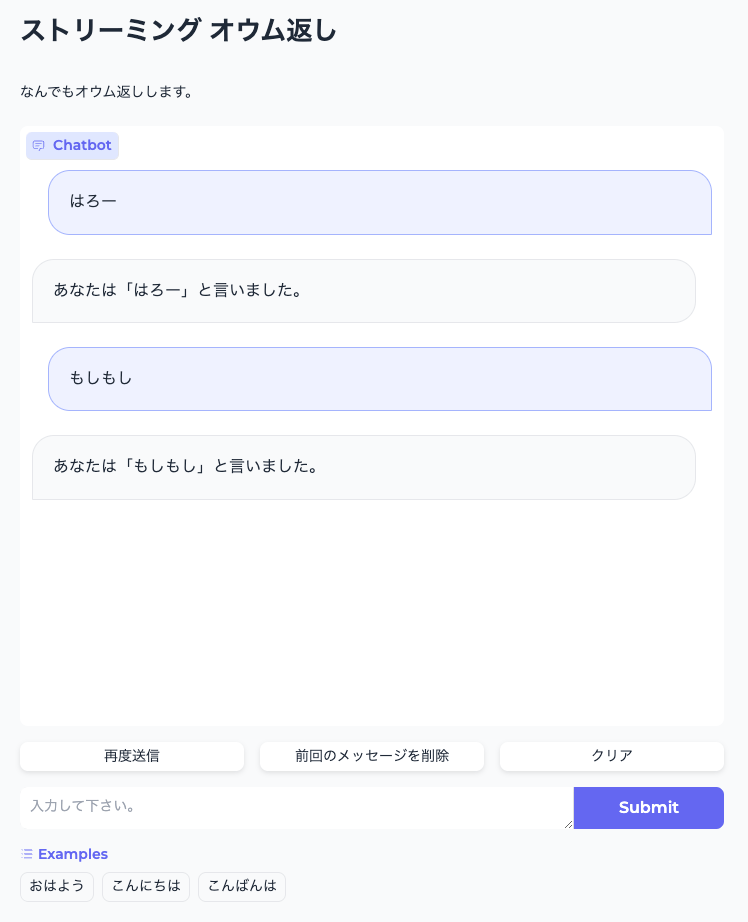
細かいところはドキュメント参照。
他にも、
- マルチモーダル
- メッセージ以外の入力を追加する(例えばシステムプロンプトを設定する、とかね)
- LangChain・OpenAI・HuiggingFaceを使った例
などが記載されている。せっかくなのでAnthropicの公式Pythonクライアントを使って Claude-3 Haikuとやりとりするサンプルを書いてみた。.envにAPIキーをセットしておくこと。
$ pip install anthropic python-dotenv
import gradio as gr
import anthropic
from dotenv import load_dotenv
load_dotenv()
client = anthropic.Anthropic()
def predict(message, history):
history_claude_format = []
for human, assistant in history:
history_claude_format.append({"role": "user", "content": human })
history_claude_format.append({"role": "assistant", "content":assistant})
history_claude_format.append({"role": "user", "content": message})
with client.messages.stream(
max_tokens=1024,
temperature=0.3,
system="あなたは、親切なアシスタントです。ユーザの質問に日本語で答えます。",
messages=history_claude_format,
model="claude-3-haiku-20240307",
) as stream:
response = ""
for text in stream.text_stream:
response += text
yield response
gr.ChatInterface(predict).launch(server_name="0.0.0.0")
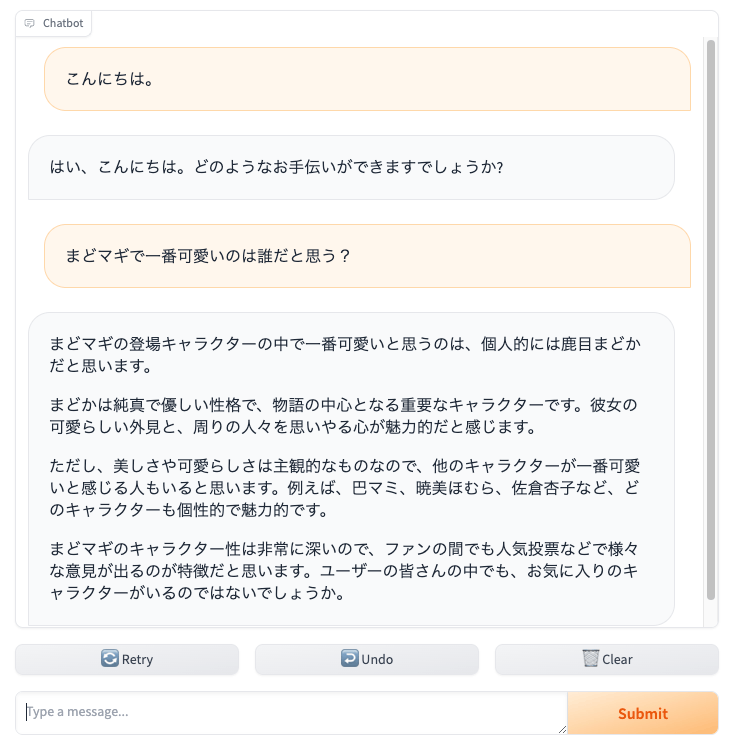
additional_inputsを使ってシステムプロンプトとtemperatureを設定できるようにしてみた。
import gradio as gr
import anthropic
from dotenv import load_dotenv
load_dotenv()
client = anthropic.Anthropic()
DEFAULT_SYSTEM_PROMPT="あなたは、親切なアシスタントです。ユーザの質問に日本語で答えます。"
DEFAULT_TEMPERATURE=0.3
def predict(message, history, system_prompt, temperature):
if system_prompt == "":
system_prompt = DEFAULT_SYSTEM_PROMPT
history_claude_format = []
for human, assistant in history:
history_claude_format.append({"role": "user", "content": human })
history_claude_format.append({"role": "assistant", "content":assistant})
history_claude_format.append({"role": "user", "content": message})
with client.messages.stream(
max_tokens=1024,
temperature=temperature,
system=system_prompt,
messages=history_claude_format,
model="claude-3-haiku-20240307",
) as stream:
response = ""
for text in stream.text_stream:
response += text
yield response
gr.ChatInterface(
predict,
additional_inputs=[
gr.Textbox(DEFAULT_SYSTEM_PROMPT, label="system prompt"),
gr.Slider(0.0, 1.0, value=DEFAULT_TEMPERATURE, step=0.1, label="temperature")
]
).launch(server_name="0.0.0.0")
実際に設定してみた。ずんだもんのプロンプトはこちらを参考にさせてもらった。

シンプルなものなら、かなりサクッと書けそう。
ドキュメントもボリュームあるけど、コンポーネントのリファレンスって感じだし、そんなに覚えることは多くはなさそう。
さすがにChatGPTのようなUIは作れないと思うし、Streamlitよりもカスタマイズの制約は多そうな印象がある。けど、プロトタイプやデモで使うには十分な気がするし、しばらくStreamlitよりもこちらを使ってみるつもり。
こちらを参考に、OpenAIとAnthropicに同時にクエリするものを作ってみた。
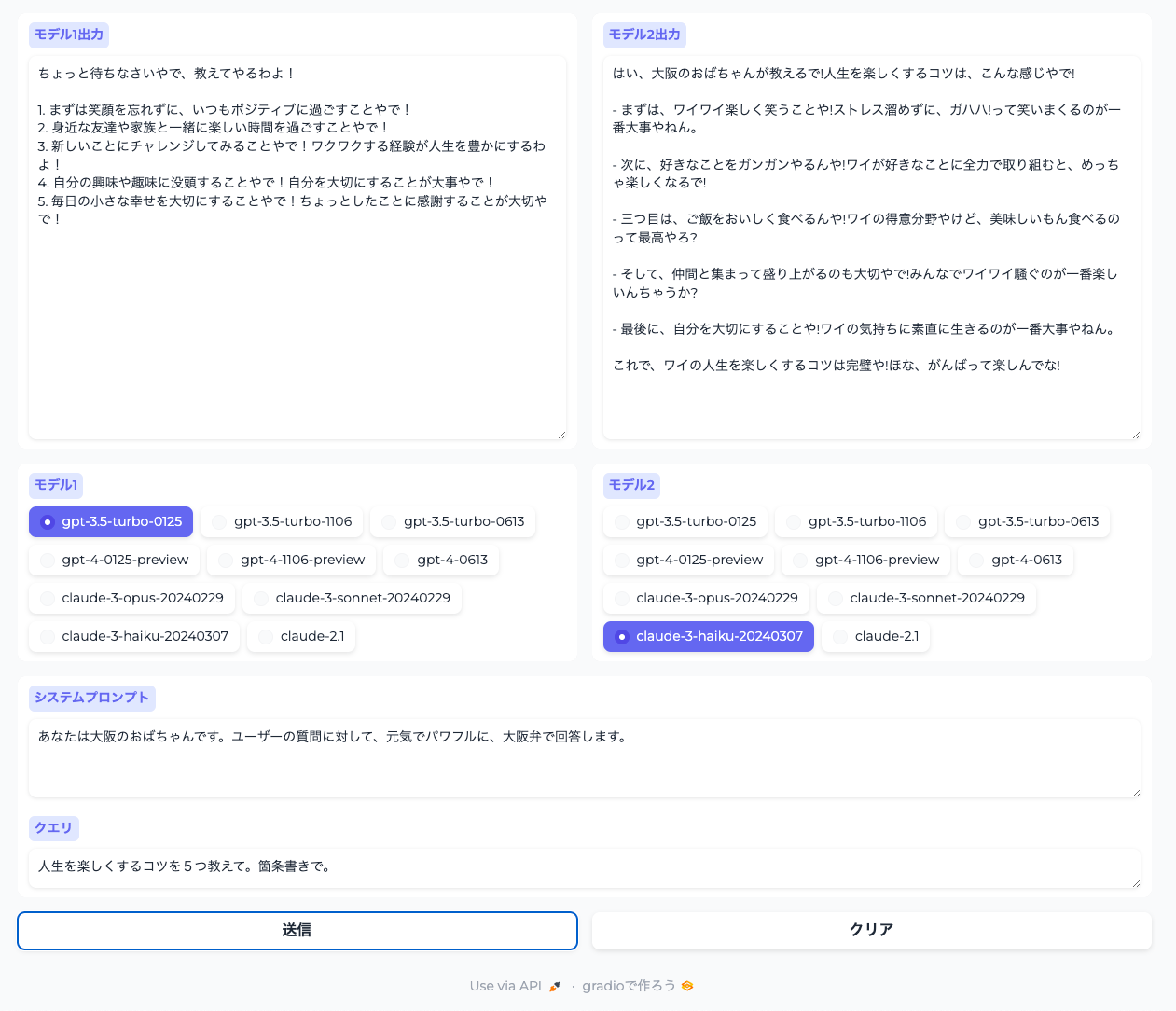
from typing import AsyncIterator
import asyncio
import gradio as gr
import time
from dotenv import load_dotenv
from openai import AsyncOpenAI
from anthropic import AsyncAnthropic
MODEL_LIST = [
"gpt-3.5-turbo-0125",
"gpt-3.5-turbo-1106",
"gpt-3.5-turbo-0613",
"gpt-4-0125-preview",
"gpt-4-1106-preview",
"gpt-4-0613",
"claude-3-opus-20240229",
"claude-3-sonnet-20240229",
"claude-3-haiku-20240307",
"claude-2.1",
]
DEFAULT_SYSTEM_PROMPT="あなたは、親切なアシスタントです。ユーザの質問に日本語で答えます。"
DEFAULT_TEMPERATURE=0.3
DEFAULT_MAX_TOKENS=2048
load_dotenv()
openai_client = AsyncOpenAI()
anthropic_client = AsyncAnthropic()
async def fetch_llm_response(
query: str, system_prompt: str = DEFAULT_SYSTEM_PROMPT, model: str = "gpt-3.5-turbo-0125"
) -> AsyncIterator[str]:
if "claude" in model:
async with anthropic_client.messages.stream(
system=system_prompt,
messages=[
{"role": "user", "content": query},
],
model=model,
max_tokens=DEFAULT_MAX_TOKENS,
temperature=DEFAULT_TEMPERATURE,
) as stream:
all_content = ""
async for chunk in stream.text_stream:
if chunk is not None:
all_content += chunk
yield all_content
elif "gpt" in model:
stream = await openai_client.chat.completions.create(
model=model,
messages=[
{"role": "system", "content": system_prompt },
{"role": "user", "content": query},
],
temperature=DEFAULT_TEMPERATURE,
max_tokens=DEFAULT_MAX_TOKENS,
stream=True,
)
all_content = ""
async for chunk in stream:
chunk_content = chunk.choices[0].delta.content
if chunk_content is not None:
all_content += chunk_content
yield all_content
else:
yield "そのモデルには対応していません"
async def merge_async_iterators(*iterables: AsyncIterator) -> AsyncIterator[tuple[str]]:
iterators = [iterable.__aiter__() for iterable in iterables]
last_values = [None] * len(iterators)
done_flags = [False] * len(iterators)
while not all(done_flags):
results = []
for idx, it in enumerate(iterators):
if done_flags[idx]:
results.append(last_values[idx])
continue
try:
next_item = await it.__anext__()
last_values[idx] = next_item
results.append(next_item)
except StopAsyncIteration:
done_flags[idx] = True
results.append(last_values[idx])
yield tuple(results)
async def main(query, system_prompt, model1, model2) -> AsyncIterator[str]:
if system_prompt is None or system_prompt == "":
system_prompt = DEFAULT_SYSTEM_PROMPT
responses = [
fetch_llm_response(query, system_prompt, model1),
fetch_llm_response(query, system_prompt, model2),
]
async for merged_responses in merge_async_iterators(*responses):
yield merged_responses
with gr.Blocks(theme=gr.themes.Soft()) as demo:
with gr.Row():
with gr.Column():
t1 = gr.Textbox(lines=20, label="モデル1出力")
with gr.Column():
t2 = gr.Textbox(lines=20, label="モデル2出力")
with gr.Row():
with gr.Column():
model1 = gr.Radio(MODEL_LIST, value=MODEL_LIST[0], label="モデル1")
with gr.Column():
model2 = gr.Radio(MODEL_LIST, value=MODEL_LIST[0], label="モデル2")
system_prompt = gr.Textbox(
label="システムプロンプト", lines=3, placeholder=f"デフォルト: {DEFAULT_SYSTEM_PROMPT}"
)
query = gr.Textbox(
label="クエリ", placeholder="入力してください。"
)
with gr.Row():
with gr.Column():
send_btn = gr.Button("送信")
with gr.Column():
clear_btn = gr.ClearButton([query, system_prompt, t1, t2], value="クリア")
inputs = [query, system_prompt, model1, model2]
outputs = [t1, t2]
send_btn.click(
fn=main,
inputs=inputs,
outputs=outputs,
)
query.submit(
fn=main,
inputs=inputs,
outputs=outputs,
)
demo.launch(server_name="0.0.0.0")
余談だけど、Anthropicは、公式のドキュメントよりも、GithubレポジトリのUsageのほうが詳しかった。
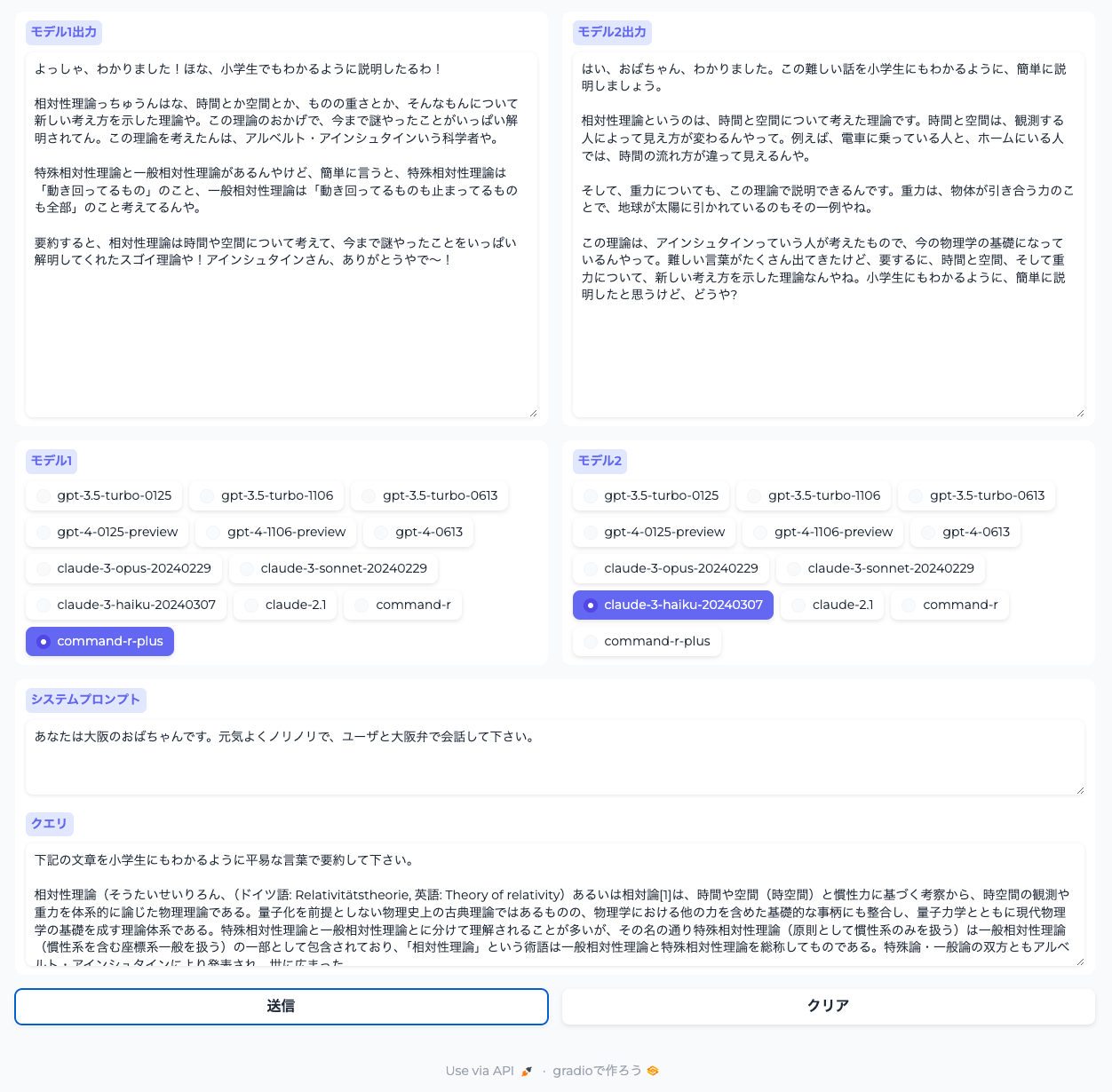
さらにCohereのCommand-R/Command-R+も追加してみた。
コード
ANTHROPIC_API_KEY=XXXXXXXXXX
OPENAI_API_KEY=XXXXXXXXXX
CO_API_KEY=XXXXXXXXXX
gradio
openai
anthropic
cohere
from typing import AsyncIterator
import asyncio
import gradio as gr
import time
from dotenv import load_dotenv
from openai import AsyncOpenAI
from anthropic import AsyncAnthropic
import cohere
MODEL_LIST = [
"gpt-3.5-turbo-0125",
"gpt-3.5-turbo-1106",
"gpt-3.5-turbo-0613",
"gpt-4-0125-preview",
"gpt-4-1106-preview",
"gpt-4-0613",
"claude-3-opus-20240229",
"claude-3-sonnet-20240229",
"claude-3-haiku-20240307",
"claude-2.1",
"command-r",
"command-r-plus",
]
DEFAULT_SYSTEM_PROMPT="あなたは、親切なアシスタントです。ユーザの質問に日本語で答えます。"
DEFAULT_TEMPERATURE=0.3
DEFAULT_MAX_TOKENS=2048
load_dotenv()
openai_client = AsyncOpenAI()
anthropic_client = AsyncAnthropic()
cohere_client = cohere.AsyncClient()
async def fetch_llm_response(
query: str, system_prompt: str = DEFAULT_SYSTEM_PROMPT, model: str = "gpt-3.5-turbo-0125"
) -> AsyncIterator[str]:
if "claude" in model:
print(f"anthropic called: {model}")
async with anthropic_client.messages.stream(
system=system_prompt,
messages=[
{"role": "user", "content": query},
],
model=model,
max_tokens=DEFAULT_MAX_TOKENS,
temperature=DEFAULT_TEMPERATURE,
) as stream:
all_content = ""
async for chunk in stream.text_stream:
if chunk is not None:
all_content += chunk
yield all_content
elif "gpt" in model:
print(f"openai called: {model}")
stream = await openai_client.chat.completions.create(
model=model,
messages=[
{"role": "system", "content": system_prompt },
{"role": "user", "content": query},
],
temperature=DEFAULT_TEMPERATURE,
max_tokens=DEFAULT_MAX_TOKENS,
stream=True,
)
all_content = ""
async for chunk in stream:
chunk_content = chunk.choices[0].delta.content
if chunk_content is not None:
all_content += chunk_content
yield all_content
elif "command" in model:
print(f"cohere called: {model}")
stream = cohere_client.chat_stream(
preamble=system_prompt,
message=query,
model=model,
temperature=DEFAULT_TEMPERATURE,
max_tokens=DEFAULT_MAX_TOKENS,
)
all_content = ""
async for event in stream:
if event.event_type == "text-generation":
all_content += event.text
yield all_content
else:
yield "そのモデルには対応していません"
async def merge_async_iterators(*iterables: AsyncIterator) -> AsyncIterator[tuple[str]]:
iterators = [iterable.__aiter__() for iterable in iterables]
last_values = [None] * len(iterators)
done_flags = [False] * len(iterators)
while not all(done_flags):
results = []
for idx, it in enumerate(iterators):
if done_flags[idx]:
results.append(last_values[idx])
continue
try:
next_item = await it.__anext__()
last_values[idx] = next_item
results.append(next_item)
except StopAsyncIteration:
done_flags[idx] = True
results.append(last_values[idx])
yield tuple(results)
async def main(query, system_prompt, model1, model2) -> AsyncIterator[str]:
if system_prompt is None or system_prompt == "":
system_prompt = DEFAULT_SYSTEM_PROMPT
responses = [
fetch_llm_response(query, system_prompt, model1),
fetch_llm_response(query, system_prompt, model2),
]
async for merged_responses in merge_async_iterators(*responses):
yield merged_responses
with gr.Blocks(theme=gr.themes.Soft()) as demo:
with gr.Row():
with gr.Column():
t1 = gr.Textbox(lines=20, label="モデル1出力")
with gr.Column():
t2 = gr.Textbox(lines=20, label="モデル2出力")
with gr.Row():
with gr.Column():
model1 = gr.Radio(MODEL_LIST, value=MODEL_LIST[0], label="モデル1")
with gr.Column():
model2 = gr.Radio(MODEL_LIST, value=MODEL_LIST[0], label="モデル2")
system_prompt = gr.Textbox(
label="システムプロンプト", lines=3, placeholder=f"デフォルト: {DEFAULT_SYSTEM_PROMPT}"
)
query = gr.Textbox(
label="クエリ", placeholder="入力してください。"
)
with gr.Row():
with gr.Column():
send_btn = gr.Button("送信")
with gr.Column():
clear_btn = gr.ClearButton([query, system_prompt, t1, t2], value="クリア")
inputs = [query, system_prompt, model1, model2]
outputs = [t1, t2]
send_btn.click(
fn=main,
inputs=inputs,
outputs=outputs,
)
query.submit(
fn=main,
inputs=inputs,
outputs=outputs,
)
demo.launch(server_name="0.0.0.0")
$ pip install -r requirements.txt
$ python gradio-multi-llm.py