「Octave TTS」を試す
大前提として現時点では日本語には対応していない。
本日、私たちは、初のText-to-Speech専用に構築されたLLMである「Octave」をリリースします。
🎨プロンプトを使ってあらゆる音声をデザイン
🎬感情や話し方(皮肉、ささやき声など)をコントロールする演技指示
🛠️クリエイタースタジオで長文コンテンツを作成従来のTTSが単に単語を「読み上げる」だけであるのに対し、Octaveは意味が発声にどのように影響するかを理解し、感情的で人間らしい音声を作り出します。
🎨音声デザイン
簡単な指示で、あらゆるAIボイスを作成できます。
「南部のASMR瞑想コーチ」から「フィルムノワール探偵」まで、コンテンツに必要な音声をOctaveが瞬時に生成します。Octaveは、ElevenLabsの音声デザインを堅牢な評価で上回りました。詳細はこちら👇
🎬演技の指示
Octaveは、感情的な表現や話し方を変える自然言語の指示を受け取ることができる初のTTSシステムです。
「皮肉っぽく聞こえるように」や「恐ろしいほどささやくように」といった指示を与えることができます。クリエイターは初めて、完全なコントロールを手にしました。
🤔文脈を理解した表現
従来のTTSよりも1000倍多い言語でトレーニングされたOctaveは、人間の俳優のようにスクリプトを理解し、リアルな感情、皮肉、テンポ、単語の強調などを表現します。
これにより、プロットの急展開、感情的な合図、キャラクターの特徴、それらを組み合わせる方法を理解することができます。愛のこもった手紙を優しく読み上げたり、スポーツの試合結果を元気にアナウンスしたりします。
🛠️クリエイター・開発者向けのツール
クリエイタースタジオを使用して、演技指示付きの長編コンテンツを正確に編集および生成できます。
開発者向けには、認証を処理し、信頼性の高い統合のための型付きインターフェースを提供するPythonおよびTypeScript SDKを通じてOctaveにアクセスできます。
Octaveの類を見ない音声インテリジェンスは、その性能が証明済みです 😉 ブラインドテストでは、OctaveはElevenLabsの音声デザインを上回る結果を出しました。
🔊71.6%がOctaveの音質を好みました
🗣️51.7%がOctaveの方がより自然だと感じました
🎯57.7%がOctaveの方が音声の説明により合っていると答えました
今すぐOctaveで作成しましょう:https://www.hume.ai/
そして、一番良いところは? Octaveは優れた機能を備えていながら、他の選択肢よりも安価です。
当社のブログでは、Octave、ブラインドスタディ、そして次なるステップについて詳しくご紹介しています。
https://www.hume.ai/blog/octave-the-first-text-to-speech-model-that-understands-what-its-saying
公式ブログの記事
色々サンプルが用意されている。
Hume AIを自分は知らなかったのだが、「音声から感情を読み取る」という技術がウリの様子。
元グーグルの研究者であるアラン・コーウェンは、2021年に同社を設立し、人の話し方から感情を解釈し、適切な返答を生成する共感型AIを構築した。それ以来、ソフトバンクや弁護士マッチングサイトのLawyer.comを含む1000社以上の企業と1000人以上の開発者がヒュームのAPIを使用し、人間の声から感情を読み取るアプリケーションを構築している。
プロダクトとしては以下の3つの様子
-
Text-to-Speech
今回のOctaveがそれにあたると思う -
EVI: Empathic Voice Interface
音声からの感情分析を組み込んだ会話型音声AI API。voice-to-voiceモデルとあるが、既存のLLMやツールと組み合わせたりもできる様子。 -
Expression Measurement
音声や表情から感情分析を行う
なかなか面白そう
料金はこちら
無料の範囲だと
- 無料プランで、10000文字/月のTTSが利用可能
- EVI/Expression Mesurementは従量課金だが$20の無料クレジットが付与
みたいなので、少し試してみる。
Text-to-Speechの開発者ドキュメント
Python SDKのQuickstartに従ってやってみる。Colaboratoryで。
パッケージインストール
!pip install hume aiofiles
!pip freeze | grep -i hume
hume==0.7.8
APIキーをセットしてクライアントを初期化。APIキーはhume.aiプラットフォームでアカウントを作成すると既に作成されていた。
from google.colab import userdata
from hume import AsyncHumeClient
import asyncio
# Notebook環境では以下が必要
import nest_asyncio
nest_asyncio.apply()
# クライアントを初期化
hume = AsyncHumeClient(api_key=userdata.get('HUME_API_KEY'))
生成結果をファイルに出力するためのヘルパー関数を設定。ドキュメントとは少し変えている。
import base64
import aiofiles
from pathlib import Path, PosixPath
output_dir = Path("output")
os.makedirs(output_dir, exist_ok=True)
# 生成された音声データをファイルに出力する
async def write_result_to_file(base64_encoded_audio: str, filename: str) -> PosixPath:
file_path = output_dir / f"{filename}.wav"
audio_data = base64.b64decode(base64_encoded_audio)
async with aiofiles.open(file_path, "wb") as f:
await f.write(audio_data)
print("出力しました: ", file_path)
return file_path
TTSを実行。発話テキストに加えてdescriptionで発話に関する説明を指定するという形。
from hume.tts import PostedUtterance
from IPython.display import Audio
speech1 = await hume.tts.synthesize_json(
utterances=[
PostedUtterance(
# テキストをどう発話するかの説明
description="A refined, British aristocrat", # 「洗練された英国貴族」
# 発話するテキスト
text="Take an arrow from the quiver.", # 「矢筒から1本の矢を取り出せ」
)
]
)
output_file = await write_result_to_file(speech1.generations[0].audio, "speech1_0")
display(Audio(output_file))
Colaboratoryだとこんな感じで確認できる。
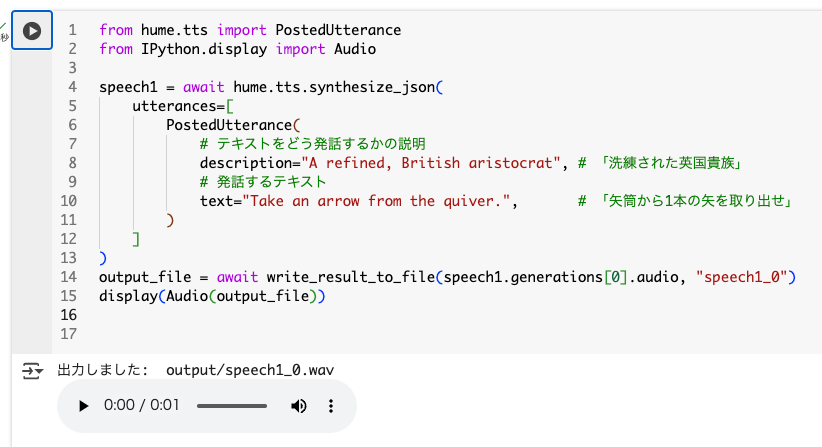
実際に生成されたもの。
で、再度生成すると音声が変わる、つまり再現性はないと思われる。
レスポンスにはgeneration_idというプロパティがある。
speech1.generations[0].generation_id
cXXXXXXX-6XXX-4XXX-aXXX-cXXXXXXXXXXX
このgeneration_idを元に音声を作成することができる。hume.aiではこれを「音声デザイン」と言っている。「音声デザイン」を作成すると、以降の生成時には再度同じ音声で生成することができる模様。
generation_id = speech1.generations[0].generation_id
await hume.tts.voices.create(
name="britshi-aristocrat-01",
generation_id=generation_id
)
ReturnVoice(id='fXXXXXXX-3XXXX-4XXXX-bXXXX-9XXXXXXXXXXX', name='BRITSHI-ARISTOCRAT-01')
hume.aiプラットフォームの画面でも音声デザインが作成されていることが確認できる。

この音声デザインを使用する際は以下のように指定する。
from hume.tts import PostedContextWithGenerationId, PostedUtteranceVoiceWithName
speech2 = await hume.tts.synthesize_json(
utterances=[
PostedUtterance(
# 前回作成した音声デザインを使用
voice=PostedUtteranceVoiceWithName(name="britshi-aristocrat-01"),
text="Now take a bow.", # 「では、一礼してください。」
)
],
# 前回生成時の音声の続きを生成する場合はgeneration_idをcontextで指定
context=PostedContextWithGenerationId(generation_id=generation_id),
# 同時に生成するバリエーションの数
num_generations=2,
)
output_file_1 = await write_result_to_file(speech2.generations[0].audio, "speech2_0")
output_file_2 = await write_result_to_file(speech2.generations[1].audio, "speech2_1")
display(Audio(output_file_1))
display(Audio(output_file_2))
まず、作成した音声デザインを使用するにはutterancesの中でvoiceに音声デザインの「名前」を指定する。
で、前回生成した際の続きの音声を生成するような場合はcontextとして前回のgeneration_idを渡す。これにより、おそらくある会話において発話音声が一貫したコンテキストを維持できる、ということなのだろうと思う。
num_generationsを指定すると、一回で複数のバリエーションを生成できる。
実際に生成されたものは以下。
音声のベースは上の方で作成したものに沿っているように聞こえるが、微妙に異なっているのがわかる。
voiceとdescriptionを合わせて指定することで「演技指示」ができる。これにより、作成した音声デザインの音声を使用しつつ、指示した内容で音声が生成されるということになる。
speech3 = await hume.tts.synthesize_json(
utterances=[
PostedUtterance(
#
voice=PostedUtteranceVoiceWithName(name="britshi-aristocrat-01"),
# 演技指示を指定: 「皮肉と軽蔑を込めて、小声でささやく」
description="Murmured softly, with a heavy dose of sarcasm and contempt",
text="Does he even know how to use that thing?", # 「彼はそれを使う方法を知っているのだろうか?」
)
],
context=PostedContextWithGenerationId(
generation_id=speech2.generations[0].generation_id
),
num_generations=1,
)
output_file_3 = await write_result_to_file(speech3.generations[0].audio, "speech3_0")
display(Audio(output_file_3))
今回の例だと、演技指示通りに発話されているのか?はネイティブじゃないと判断できない感があるな。
あと、会話の中でTTSを繰り返し生成する場合は、上記のようにgeneration_idを引き継いでいくのが1つのやり方なんだろう。
なお、音声デザインで作成した音声以外にも、プリセットされた音声が複数用意されている。

また音声デザインはプラットフォームの画面上でも行える。
まとめ
プロンプトで発話スタイルを指定したり、発話のコンテキストを引き継いだり、また生成内容に再現性が(基本的に)ない、っていうのはとてもLLM的だなと感じた。
とりあえず現状は日本語には対応していないだけども、果たして・・・
ここしばらくの間、日本語TTSを色々触ってみて、日本語TTSのつらみみたいなものがあることを知ったので、期待半分不安半分で、待ちたいと思う。
日本語TTSのつらみについては、以下のとりしまさんのスライドを一読することをオススメ。