リアルタイムな音声チャットを実現する「RealtimeVoiceChat」を試す
ここで知ったのだけど
GitHubレポジトリ
以前試した「RealtimeSTT」「RealtimeTTS」の作者の方で、「RealtimeVoiceChat」はこれらのコンポーネントをLLMと組み合わせて、1つのパッケージっぽくまとめられている様子。
自分も上記を試した際にこれらにLLMを組み合わせてチャットを作ってみたのだけど、ある程度までは速くなったのだけども、GitHubにあるデモ動画を見ると、これほどには速くならなかったし、割り込みなども実装されているようなので、どういう工夫がされているのかを確認してみたい。
GitHubのREADMEにデモ動画があるのだが、これはGitHub上でしか見られない。調べてみると、YouTubeにもデモ動画がアップされていた。
GitHubのREADME上のものとは微妙に違うようなので、合わせて確認してみることをオススメ
GitHubレポジトリ
Real-Time AI Voice Chat 🎤💬🧠🔊
AIと自然な音声会話を楽しもう!
こちらのプロジェクトでは、音声だけでLLM(大規模言語モデル)とチャットし、ほぼリアルタイムで音声応答を受け取れます。まるでデジタルな会話パートナーです。
内部構造は?
低遅延対話のために設計された高度なクライアント–サーバーシステム:
- 🎙️ Capture: ブラウザで音声をキャプチャ
- ➡️ Stream: 音声チャンクをWebSocket経由でPythonバックエンドへ送信
- ✍️ Transcribe:
RealtimeSTTで音声を高速にテキスト化- 🤔 Think: テキストをLLM(OllamaやOpenAIなど)に送信して処理
- 🗣️ Synthesize: AIのテキスト応答を
RealtimeTTSで音声合成- ⬅️ Return: 生成された音声をブラウザへストリーム再生
- 🔄 Interrupt: いつでも会話に割り込めます。中断もスムーズに処理。
主な機能✨
- 滑らかな会話: 音声で話し、音声で聞く、まるで人との会話のように
- リアルタイムなフィードバック: 部分的な文字起こしやAI応答をリアルタイム表示
- 低レイテンシーにフォーカス: 音声チャンクストリーミングによる最適化アーキテクチャ
- スマートなターンテイキング: 動的な無音検知(
turndetect.py)で会話のリズムに対応- 柔軟なAI脳: プラグイン式LLMバックエンド(デフォルトOllama、
llm_module.pyでOpenAI対応)- カスタマイズ可能な音声: 複数のTTSエンジン選択可(Kokoro、Coqui、Orpheus/
audio_module.py)- Webインタフェース: Vanilla JSとWeb Audio APIによるシンプルUI
- Dockerでデプロイ: Docker Compose推奨、依存関係管理が簡単
Technology Stack 🛠️
- バックエンド: Python 3.x、FastAPI
- フロントエンド: HTML、CSS、JavaScript(Vanilla JS、Web Audio API、AudioWorklets)
- 通信: WebSockets
- コンテナ: Docker、Docker Compose
- コアの AI/ML ライブラリ:
RealtimeSTT(Speech-to-Text)RealtimeTTS(Text-to-Speech)transformers(ターン検出、トークナイゼーション)torch/torchaudio(機械学習フレームワーク)ollama/openai(LLMクライアント)- オーディオ処理:
numpy、scipy始める前に: 前提条件 🏊♀️
強力なAIモデルを活用するため、以下が必要です:
- オペレーティングシステム:
- Docker: GPU連携のためLinux推奨
- Manual:
install.batはWindows用。Linux/macOSでは手動手順が可能ですが、DeepSpeedなどで追加トラブルシュートが必要- 🐍 Python: バージョン 3.9以上(手動セットアップ時)
- 🚀 GPU: CUDA対応NVIDIA GPUを強く推奨(WhisperやCoquiの高速化)。CPUのみや非力GPUでは性能低下
- セットアップはCUDA 12.1前提。異なるCUDAの場合はPyTorchインストールを調整
- Docker(Linux): NVIDIA Container Toolkitが必要
- 🐳 Docker(任意だが推奨): Docker Engine & Docker Compose v2+推奨
- 🧠 Ollama(任意): Docker外で使う場合は別途インストールし、モデルをプル。DockerセットアップにはOllamaサービス含む
- 🔑 OpenAI API Key(任意): OpenAIバックエンド利用時は
OPENAI_API_KEY環境変数を設定(.envやDocker経由)
構成の詳細 🔧
AIの声質、思考、聞き方を調整したい?
codeディレクトリ内Pythonファイルを編集:
- TTSエンジン & Voice(
server.py,audio_module.py):
START_ENGINEを"coqui"、"kokoro"、"orpheus"に変更- CoquiモデルパスやOrpheusのspeaker ID、速度など設定可能
- LLMバックエンド & Model(
server.py,llm_module.py):
LLM_START_PROVIDER("ollama"or"openai")、LLM_START_MODELを指定- Docker使用時はモデルプルを忘れずに
system_prompt.txtでAIの性格をカスタマイズ可能- STT設定(
transcribe.py):
DEFAULT_RECORDER_CONFIGでWhisperモデル、言語、無音閾値など調整- ターン検出感度(
turndetect.py):
TurnDetector.update_settings内のポーズ時間定数を変更- SSL/HTTPS(
server.py):
USE_SSL = Trueに設定し、証明書・鍵へのパスを指定- Dockerなら
docker-compose.ymlにSSLポートマッピング&ボリュームを追加- ローカルSSL証明書生成(Windows例・mkcert使用)
- Chocolateyをインストール
choco install mkcertでmkcert導入- 管理者権限でコマンドプロンプト起動
mkcert localhost 127.0.0.1 ::1 your.local.ipで証明書生成- 生成された
.pemファイルをserver.pyのSSL_CERT_PATH/SSL_KEY_PATHに設定
ライセンス 📜
コアコードはMIT Licenseの下で公開(詳細はLICENSE参照)。
本プロジェクトはCoqui XTTSv2などの外部TTSエンジンやLLMプロバイダのライセンスを遵守してください。
ざっと見た感じ、
- 基本的にローカルモデルを使用する前提に見える
- STTはFaster-Whisper(デフォルトは
base.en) - TTSは Coqui / kokoro(デフォルト) / Orpheus
- LLMはOllama(デフォルトはMistral-Smallのファインチューニング版。ただしOpenAIも使える)
- STTはFaster-Whisper(デフォルトは
ように見えるので、そのまま動かすとネットワーク的なレイテンシーは小さくなりそう。デモを見るにあたってはこれらの可能性は認識しておいたほうが良さそう。
あと、興味深いのは
- 独自のターン検出モデルを使っている
- 日本語向けに学習はされているのだろうか???
- 高速なやり取りや「割り込み」を実現するためにWebSocketを使っている様子
あたり。
あと高速化のための工夫っぽいコードがチラホラありそうなので、 「RealtimeSTT」「RealtimeTTS」を単純にLLMと組み合わせて単純にパイプライン化した、というわけではなさそう。そのあたりちょっと追いかけてみる。
日本語で動かす場合
- Faster-Whisperのモデルを日本語にする
- TTSはCoqui または Kokoro(Orpheusはまだ日本語対応していないと思う)
- Ollamaで日本語に対応したモデルを使用する
あたりになるかな。
STT・TTSについては「RealtimeSTT」「RealtimeTTS」を使っているので、それらが対応しているモデルであれば置き換えることはできそうだけど、多少の修正は必要になりそう。
インストール
ローカルモデルを使うのが良さそうなので、今回はUbuntu−22.04サーバ(RTX4090)で、Dockerでインストールしてみる。
レポジトリクローン
git clone https://github.com/KoljaB/RealtimeVoiceChat && cd RealtimeVoiceChat
ここから日本語で使えるように修正していくのだが、ドキュメントにある変更すべき箇所だけでは足りず、色々修正が必要だった。以下はその過程での試行錯誤の結果であり、不必要な変更も含まれる可能性がある点に留意。
今回は以下を使用することとする。
- STT: Faster-Whisper(
medium)- デフォルトの
base.enは日本語非対応 -
baseにしても日本語を認識してくれなかった。とりあえずmediumなら認識できた。
- デフォルトの
- TTS: Kokoro TTS
- LLM: Ollama Google Gemma3-4b
まず、code/server.py。TTS_START_ENGINEで"kokoro"を選択、LLM_START_MODELでOllamaのモデルを指定。
(snip)
#TTS_START_ENGINE = "orpheus" # コメントアウト
TTS_START_ENGINE = "kokoro"
#TTS_START_ENGINE = "coqui" # コメントアウト
(snip)
LLM_START_PROVIDER = "ollama"
#LLM_START_MODEL = "qwen3:30b-a3b"
#LLM_START_MODEL = "hf.co/bartowski/huihui-ai_Mistral-Small-24B-Instruct-2501-abliterated-GGUF:Q4_K_M" # コメントアウト
LLM_START_MODEL = "gemma3:4b" # 追加
(snip)
あと、言語の設定があるので変更。
(snip)
LANGUAGE = "ja" # 変更
(snip)
さらに、DEFAULT_RECORDER_CONFIGのmodel、language、realtime_model_typeを変更。languageは上の言語設定で上書きされるので、あまり関係なさそうではある。
(snip)
DEFAULT_RECORDER_CONFIG: Dict[str, Any] = {
"use_microphone": False,
"spinner": False,
"model": "medium", # `medium`に変更。
"realtime_model_type": "medium",
"use_main_model_for_realtime": False,
"language": "ja", # `ja`に変更
"silero_sensitivity": 0.05,
"webrtc_sensitivity": 3,
"post_speech_silence_duration": 0.7,
"min_length_of_recording": 0.5,
"min_gap_between_recordings": 0,
"enable_realtime_transcription": True,
"realtime_processing_pause": 0.03,
"silero_use_onnx": True,
"silero_deactivity_detection": True,
"early_transcription_on_silence": 0,
"beam_size": 3,
"beam_size_realtime": 3,
"no_log_file": True,
"wake_words": "jarvis",
"wakeword_backend": "pvporcupine",
"allowed_latency_limit": 500,
"debug_mode": True,
"initial_prompt_realtime": "The sky is blue. When the sky... She walked home. Because he... Today is sunny. If only I...",
"faster_whisper_vad_filter": False,
}
(snip)
code/audio_module.pyのAudioProcessorクラスのコンストラクタ(__init__)のKokoroの設定箇所で、voiceを変更。日本語の場合は、以下のどれかを選択。
jf_alphajf_gongitsunejf_nezumijf_tebukurojm_kumo
(snip)
class AudioProcessor:
(snip)
def __init__(
(snip)
elif engine == "kokoro":
self.engine = KokoroEngine(
voice="jf_alpha", # 変更
default_speed=1.26,
trim_silence=True,
silence_threshold=0.01,
extra_start_ms=25,
extra_end_ms=15,
fade_in_ms=15,
fade_out_ms=10,
)
(snip)
最後にdocker-compose.yml。多分修正しなくても行けると思うけど、自分はローカルにOllamaがもうインストールされているので、以下を変更した(単純に気分の問題)。
services:
app:
build: .
image: realtime-voice-chat:latest
container_name: realtime-voice-chat-app
ports:
- "8000:8000"
# extra_hostsを追加
extra_hosts:
- "host.docker.internal:host-gateway"
environment:
- OLLAMA_BASE_URL=http://host.docker.internal:11434 # host.docker.internalを参照
(snip)
# コメントアウト
#depends_on:
#- ollama
(snip)
# ollamaの設定はすべてコメントアウト
#ollama:
# image: ollama/ollama:latest
# container_name: realtime-voice-chat-ollama
# command: ["ollama", "serve"] # Usually the default command/entrypoint
(snip)
で、おそらくKokoro TTSで日本語を使う場合にはライブラリが足りないので、以下をrequirements.txtに追加
(snip)
misaki[ja]
辞書をダウンロードするようにDockerfileを修正。SileroVADのダウンロードをしている箇所の下ぐらいでいいと思う。
# <<<--- Silero VAD Pre-download --->>>
RUN echo "Preloading Silero VAD model..." && \
(snip)
RUN python -m unidic download
(snip)
あと、Whisperのモデルを事前ダウンロードしている箇所を修正。
(snip)
# <<<--- faster-whisper Pre-download --->>>
ARG WHISPER_MODEL=medium # `medium` に変更
ENV WHISPER_MODEL=${WHISPER_MODEL}
(snip)
ではコンテナをビルド。結構時間がかかる。現時点では、設定を外に切り出せていないように思えるので、何かしら設定を変更するたびにビルドし直しが必要になる模様・・・非常に辛い・・・
docker compose build
起動
docker compose up
以下が表示されれば起動完了
realtime-voice-chat-app | INFO: Application startup complete.
realtime-voice-chat-app | INFO: Uvicorn running on http://0.0.0.0:8000 (Press CTRL+C to quit)
ブラウザで8000版ポートにアクセスするのだが、自分の環境の場合、RealtimeVoiceChatが動作しているのはLAN内の別サーバで、多分Chromeのセキュリティ設定でマイクが有効にできない。

Ubuntuのデスクトップからアクセスすると一応動くのだが、音声認識後にLLMに送信されない。ターン検出モデルが日本語対応していないのか?と思って無効にしてみたけども、変わらず。
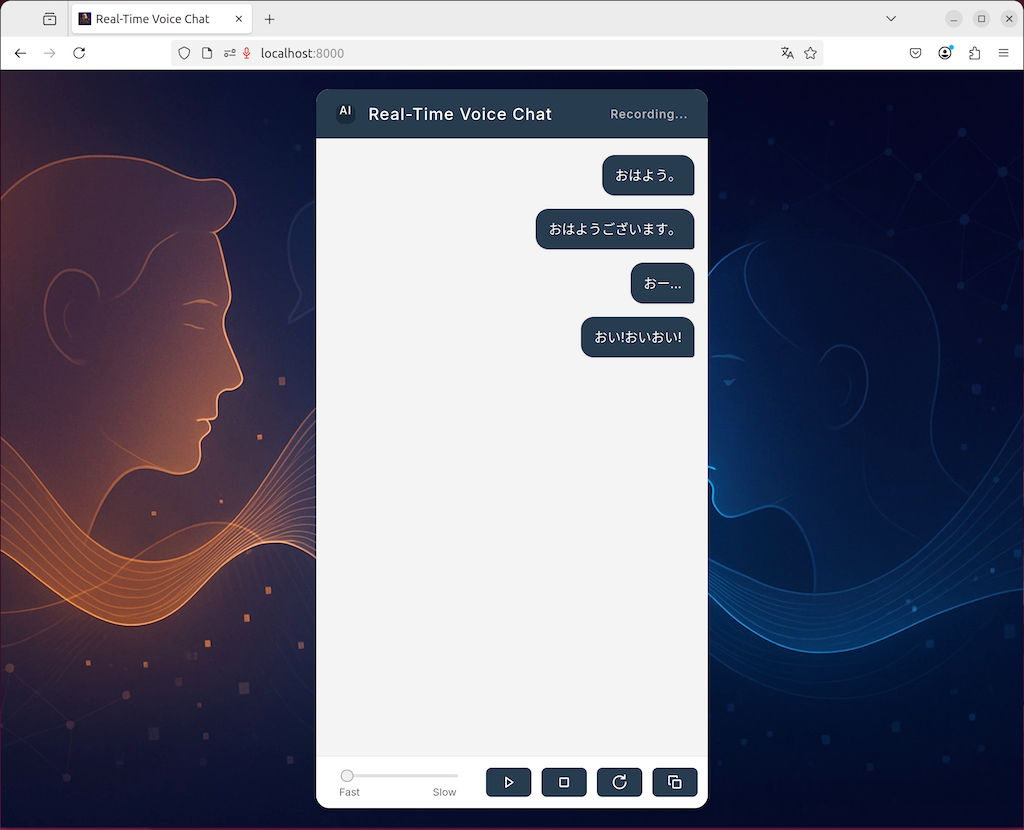
とりあえずいろいろ試行錯誤してみたけども、設定変更するたびにビルドして長時間の待ちが発生するのが辛すぎて、ここで一旦離脱・・・
英語ならデフォルトで動くので、多分英語以外の言語でしようする場合の差異に対する考慮がどこかで抜けてるのではないかと推測してる。
Dockerでやるからビルド待ちになる。動くまではPython環境作ってやる方が良さそう(だが面倒)