ChatGPTのCode Interpreterを使って競馬のデータを解析してみる
ChatGPTのCode Interpreterを使って競馬データの解析をしてみる。使用するデータセットは以下を使ってみた。
ダウンロードしたアーカイブをアップロードして解析をお願いしてみる。

zipを展開して中身を読み込んでくれる。

"Show work"をクリックするとPythonのコードも表示される。

データセットのサイズが大きすぎるとだめみたいだけど、自分で解決策を提案してきた。
ざっくり中身を教えてくれる。

pandasのデータフレームとして読み込まれているのがわかる。

手始めに、各競馬場の各条件ごとのラップタイムの平均をグラフにするというのをやってみる。

競馬場ごとにラップタイムを出すにはちゃんと複数のデータフレームを結合して算出しないといけないということを理解している。そのうえで、データのサニタイズとか、データサイズを踏まえてサンプルで始める、などいろいろ考えて進めてくれる。失敗した場合やわからない場合なども推測したりトライ&エラーしつつ進めてくれる。

結果。

ちなみに、中京ダート1000mというのは、恐らく以前の中京競馬場コース改修工事以前に施工されてた距離じゃないかな?最近は多分ないと思う。恐らく古いデータが含まれているのではないだろうか。
とりあえずデータ量が多いとつまづきそうなので、東京競馬場に限定して聞いてみた。

そうではない。もう少しきちんと指示を出すべきだった。
やりなおし。

どうも途中でコケてしまう様子。2回ほどやってみたけど失敗する。もしかすると処理内容が重すぎるのかな。
ということで、東京芝1600mに限定してステップバイステップで進めてみることにする。
うむ、ではグラフに。
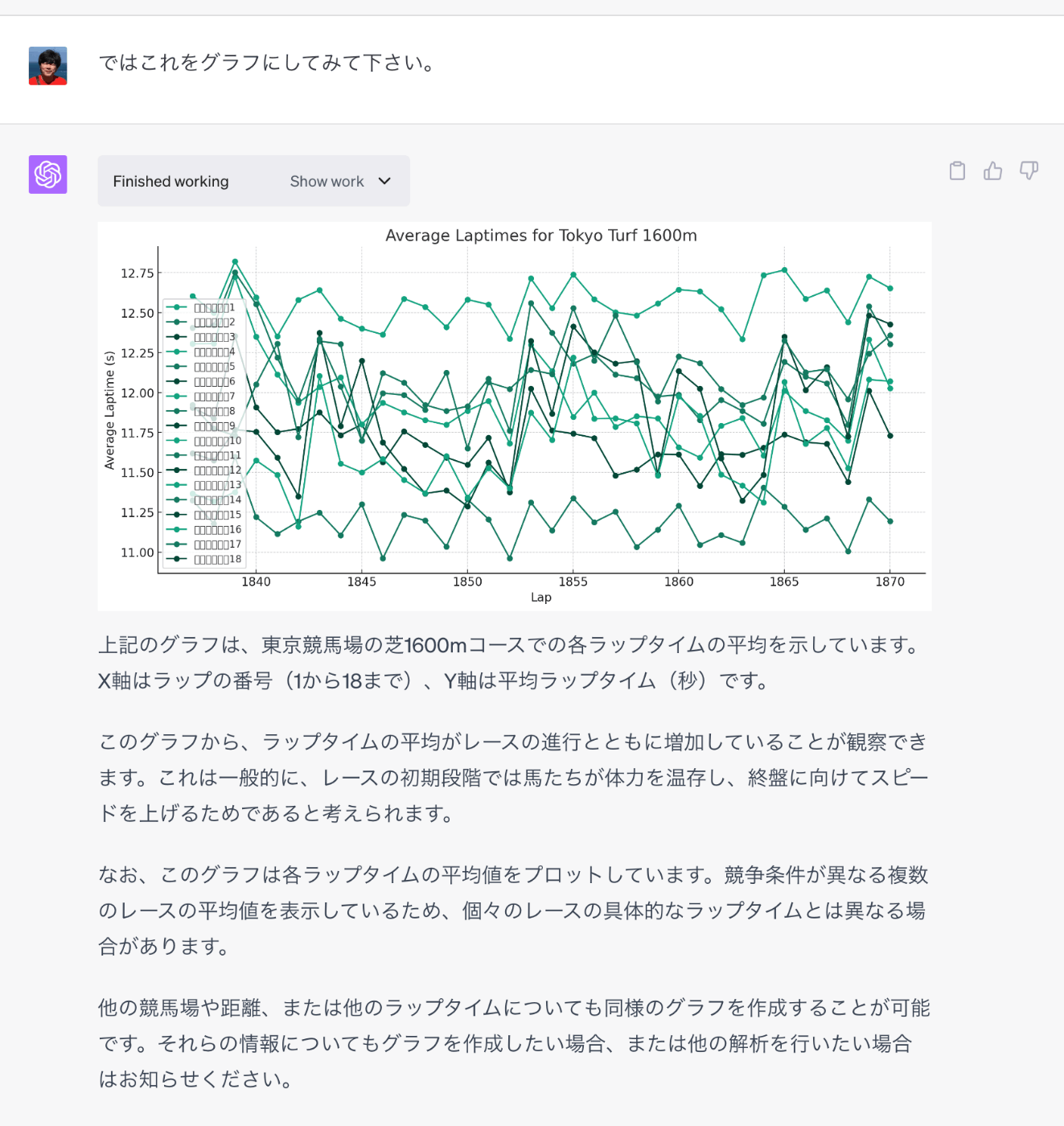
だいぶ近づいてきたけど、ちょっと違う。ラップタイムの各列は1F(200m)ごとに出力されているので、1600mの場合は8個の列だけが必要になる。x軸の個数が明らかに多すぎる、
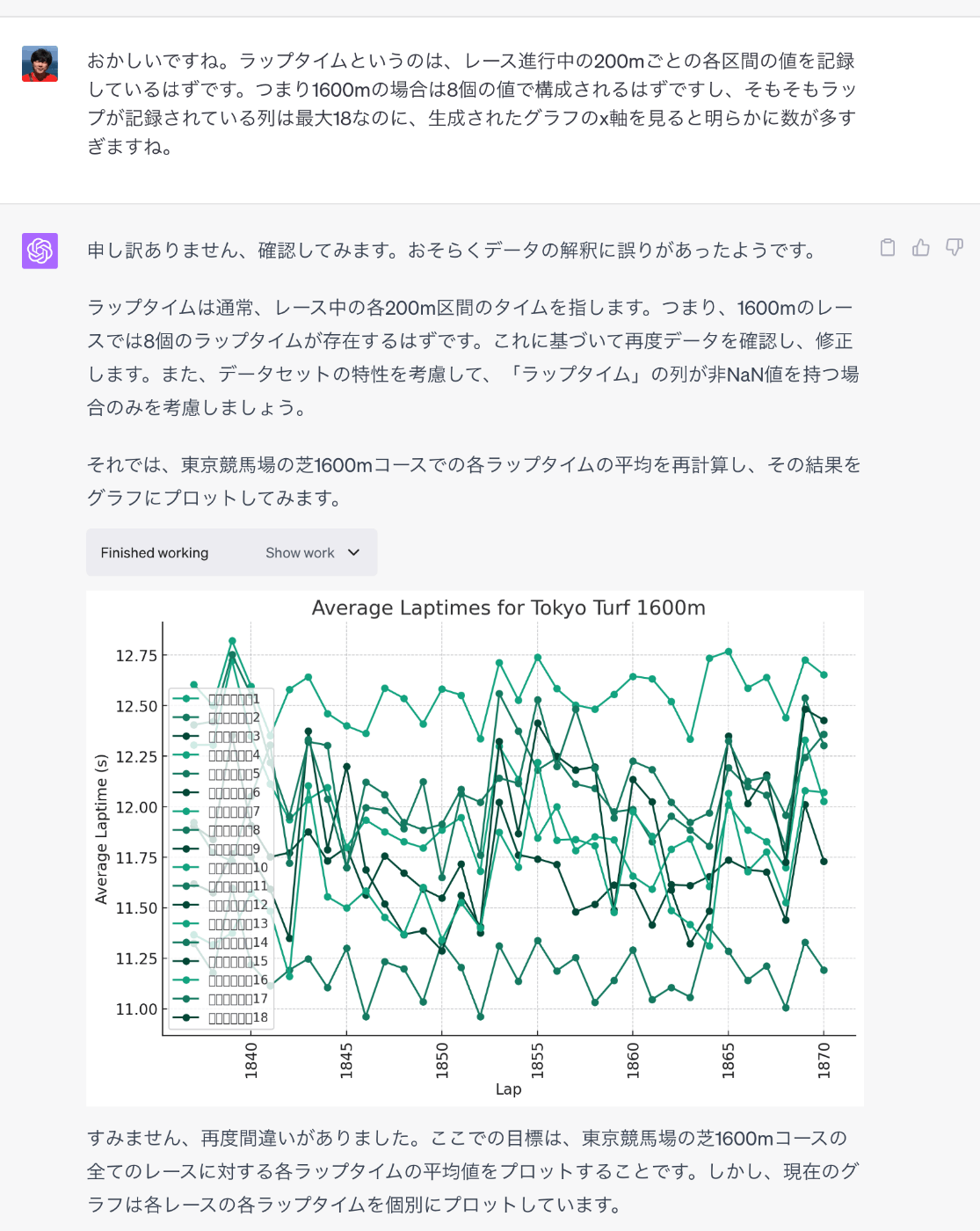
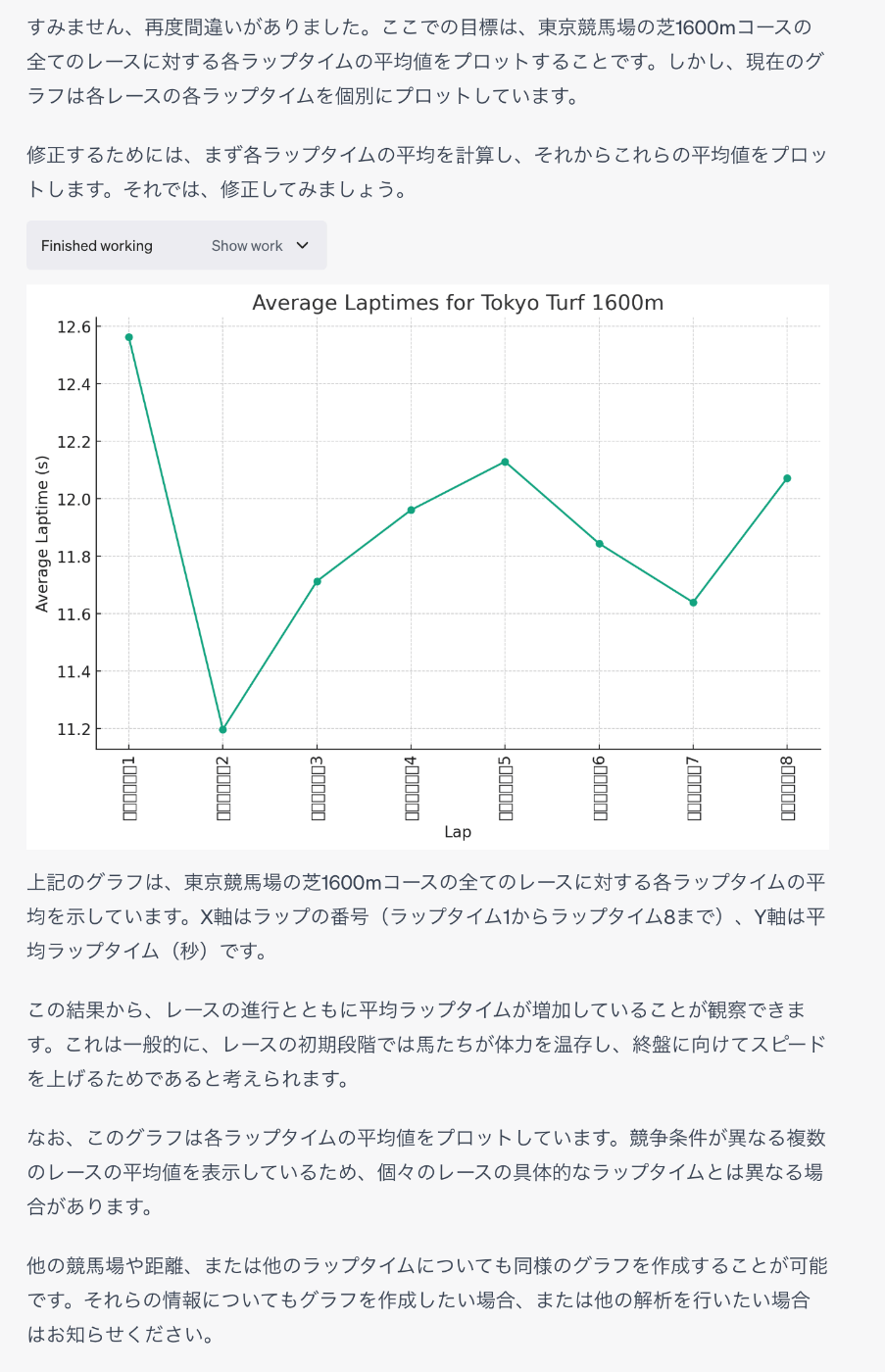
なんか途中ちょっと飛躍しているけれどもそれっぽいものが出力されている様子。もう少しツッコんでみる。
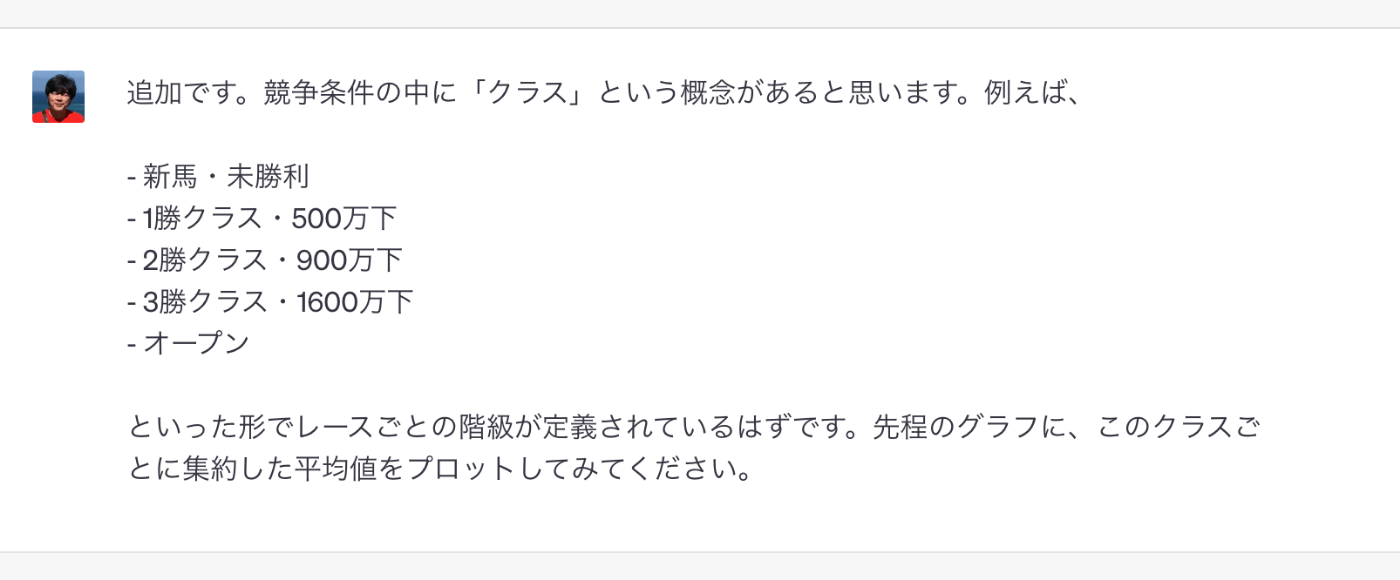
だいぶ近づいてきた。
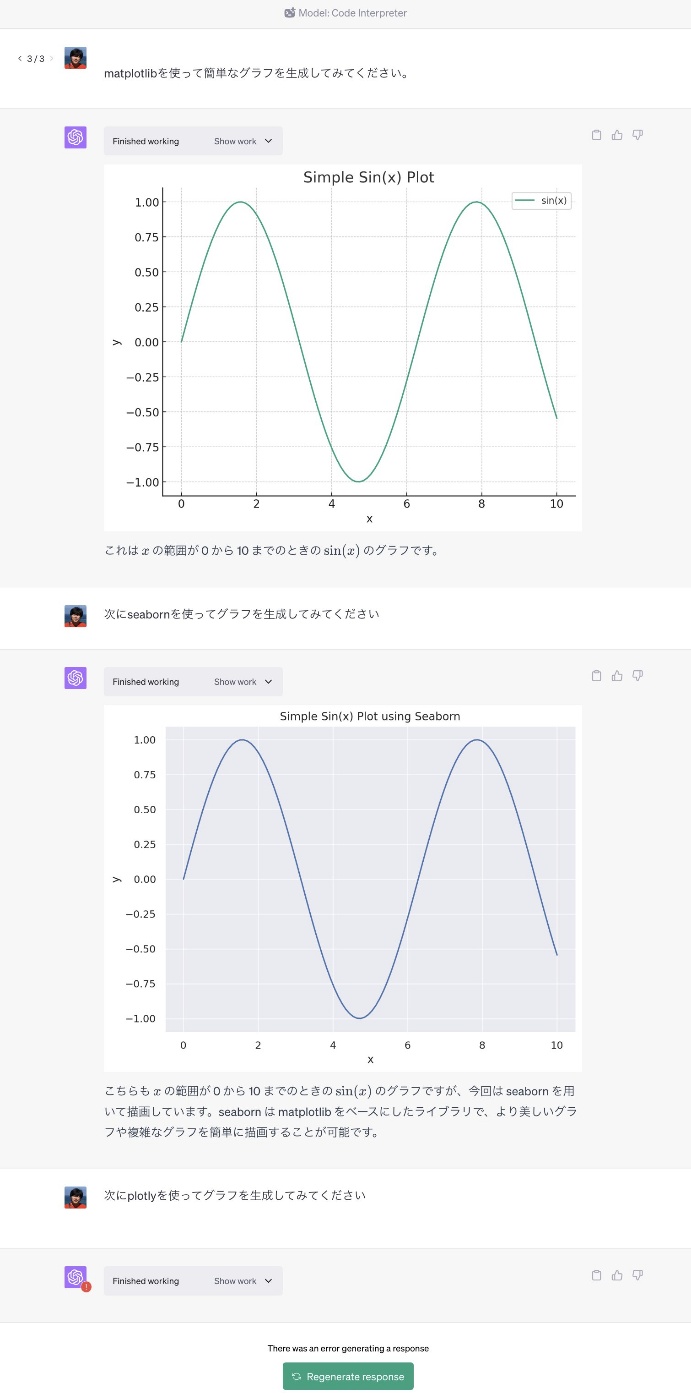
何度かやってみたけど、どうもPlotlyは使えない模様。というか、一応ライブラリはインストールされているらしいのだけど、シンプルな例でもエラーになる。
所感
- イメージ的にはAgentっぽい感じ。ある程度自分で考えて進めてくれるのはすごい。
- ライブラリもいろいろ入っている。特にデータ解析系のライブラリは一通り揃っているようなので、データセットさえ与えれば、データ解析環境ができあがる。
- 実行時のPythonコードが生成されるのは良い。再現性が確保できるし、活用もできる。
- 実行時に出力されたグラフ等は保存されるわけではなく、あとから履歴を開いても表示されない。再度必要な処理を実行する必要がある
なるほど、HTMLで出力させればいいと。