pyparsingで競馬のコーナー通過順位をパース→Plotlyで可視化
概要
以下の記事、以前からほんと素晴らしいと思っていたのですが、最近Plotlyを知ったので可視化してみました。
ちなみに、pandas/pyparsing/plotlyはおろかpython自体そんなに使ったことがなかったので、よくわかってないところもあります。間違いがあれば指摘して下さい。
最初に結論
2022年の有馬記念です(イクイノックスが強すぎた・・・。)
| コーナー | 位置取り表記 |
|---|---|
| 1コーナー | 13-15(10,16)(14,7)2(12,9)8(4,6,11)(3,5)-1 |
| 2コーナー | 13-15(10,16)(14,7)(2,12)9,8(4,6,11)(3,5)-1 |
| 3コーナー | 13(15,16)(10,7)(14,9)(2,12,11)(8,4,6,5)(3,1) |
| 4コーナー | (*13,16)(7,9)10(2,14,3)(12,6)11(8,15,5)1,4 |
上記が以下のようになります。

1〜3着馬の位置取りはこうなっています。

実際のレース映像はこちら
コード
Google Colaboratoryのnotebookを以下で公開しています。
Colaboratoryでnotebookを開いたら上から順に実行していきます。
隊列の文字列はnetkeiba.comのレース結果画面からスクレイピングできるようにしてあります。途中のフォームにURLを入力します。

最初の例で挙げた2022年の有馬記念だと以下のURLになります。
https://race.netkeiba.com/race/result.html?race_id=202206050811&rf=race_list
URLを入力したら残りのブロックを実行していくと表示されます。
URLを変えて再度試す場合はURLを入力してそれ以降のブロックを実行すればよいです。上から全部再実行する必要はありません。
コードの説明
ここからはコードの中身について説明します。
内外の優劣
元々の記事では、先頭からの差(馬身)だけを出してありますが、コーナー通過順には内・外の概念があります。これを取れるように元のコードを修正します。
pandasのDataFrameに、内から何頭目かを表す列 side を追加します。
# DataFrame列名定義
columns = ['diff', 'horse_no', 'side']
ParsePassクラスで、横並びの馬群を処理する _group_action メソッドを修正して内から何番目か?を列 side に追加します。1頭だけの場合を処理する _horse_no_action メソッドについては、外に一頭もいないということになるので1(つまり最内)で固定しています。実際にはそうではない可能性もありますが、位置取り表記からはそれ以上読み解けないので妥協しています。
あとpandas-1.4.0以降ではpd.appendは非推奨になるということで、pd.concatに書き換えています。
def _horse_no_action(self, token):
df_append = pd.DataFrame(data=[[self._diff, token[0], 1]], columns=columns)
self._data = pd.concat([self._data, df_append], ignore_index=True, axis=0).drop_duplicates().reset_index(drop=True)
return
def _group_action(self, token):
for i, no in enumerate(token):
df_append = pd.DataFrame(data=[[self._diff, no, 1+i]], columns=columns)
self._data = pd.concat([self._data, df_append], ignore_index=True, axis=0).drop_duplicates().reset_index(drop=True)
self._diff += DIFF_GROUP
self._diff -= DIFF_GROUP
return
これだけです。単体で動かすとこんな感じになります。

Plotlyで可視化
次に隊列情報が入ったDataFrameを可視化します。先頭馬を起点としてそこから相対的な位置取りを表せばいいので、グラフは散布図(Scatter)を使っています。
最初はmatplotlibでやってみたのですが表現力に限界があると感じたので、Plotlyを使いました。Plotlyには2つの種類があります。
- Plotly express
- Plotly graph objects
最初はシンプルに書けるPlotly expressを使いました。最終的にはPlotly graph objectsに変えたのですが、一応Plotly expressでもやったことをまとめておきます。
Plotly expressの場合
Plotly expressで単純にscatterを書くならこうなります。
import plotly.express as px
fig = px.scatter(df, x="diff", y="side")
fig.show()

これだとちょっと味気ないので、装飾や調整を加えていくとこうなります。
import plotly.express as px
fig = px.scatter(df_final, x="diff", y="side", color="waku_no",
color_discrete_map={"1":"snow", "2":"black", "3":"red", "4":"blue","5":"yellow","6":"green","7":"orange","8":"pink"},
category_orders={"waku_no":["1","2","3","4","5","6","7","8"]},
width=800, height=400)
fig.update_traces(marker_size=25, marker_line_width=3)
fig.update_layout(
yaxis=dict(title="内 ←←←←← 内外 →→→→→ 外",range=[0,6], dtick=1, visible=True, showticklabels=True, zerolinecolor='LimeGreen', gridcolor='LimeGreen'),
xaxis=dict(title="前 ←←←←← 前後(馬身) ←←←←← 後", range=[-1, 20], visible=True, zerolinecolor='LightGreen', gridcolor='LightGreen', dtick=5, showticklabels=True),
plot_bgcolor="LimeGreen")
fig.show()

上記の中で特に便利なのは、Plotly expressの"discrete color"です。
デフォルトではプロットの色は1色で固定されますが、これを値に応じて変化させることが出来ます。競馬の場合は枠番ごとに色を分けて表示したいですよね。あらかじめDataFrameには枠番の列も追加しておきます。

colorで枠番の列を指定します。わかりやすいようにプロットされたマーカーのサイズも変えておきます。
import plotly.express as px
fig = px.scatter(df, x="diff", y="side", color="waku_no")
fig.update_traces(marker_size=25, marker_line_width=3)
fig.show()

色分けしたい列の値が「数値」の場合はこのように「段階的」に表示されます。つまり"1.5"とかの中間の値だとグラデーションっぽく色付けされるようになります。競馬の枠番は1〜8の整数のみなので「段階的」表示は不要です。色分けする列の値を「文字列」に変えてみます。
import plotly.express as px
df["waku_no"] = df["waku_no"].astype(str)
fig = px.scatter(df_final, x="diff", y="side", color="waku_no")
fig.update_traces(marker_size=25, marker_line_width=3)
fig.show()
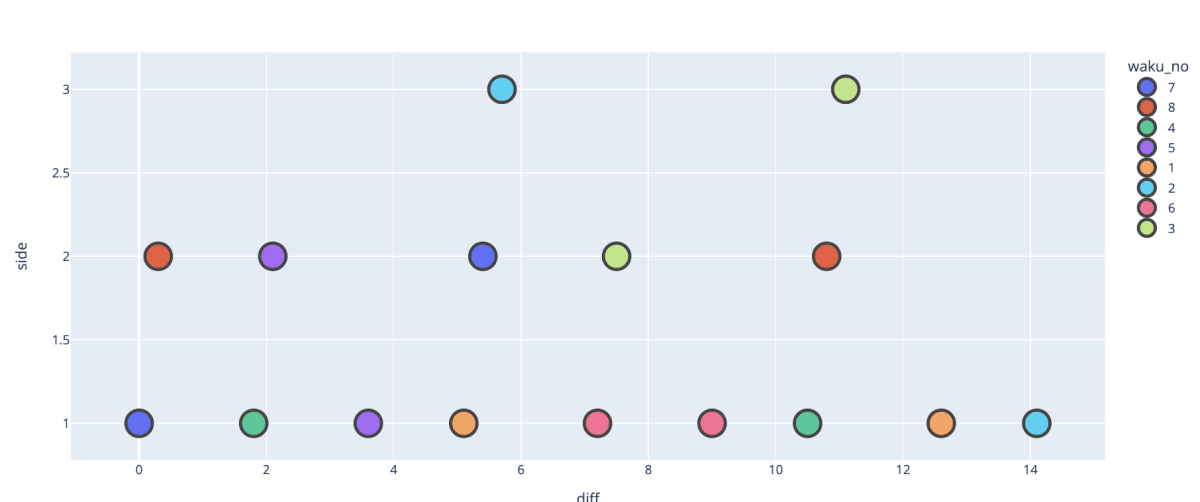
枠番ごとに色が「分離的・離散的」(discrete)に表示されました。枠番を「カテゴリー」として認識しているわけですね。
次にこの色パターンを設定します。色パターンは color_discrete_sequence を使う方法と、color_discrete_map を使う方法があります。
color_discrete_sequence の場合はこうなります。
import plotly.express as px
df["waku_no"] = df["waku_no"].astype(str)
fig = px.scatter(df, x="diff", y="side", color="waku_no",
color_discrete_sequence=["snow","black","red","blue","yellow","green","orange","pink"],
category_orders={"waku_no":["1","2","3","4","5","6","7","8"]},
)
fig.update_traces(marker_size=25, marker_line_width=3)
fig.show()
color_discrete_sequence で割り当てる色と順序を配列で指定します。ただし、1つ上のグラフの凡例を見るとわかりますが、順番はバラバラになります。これだけだと正しい枠番ごとの色に割り当てられないので、カテゴリーの順番を category_orders で明示的に指定します。
こうなります。

次に color_discrete_map の場合です。
import plotly.express as px
df["waku_no"] = df["waku_no"].astype(str)
fig = px.scatter(df, x="diff", y="side", color="waku_no",
color_discrete_map={"1":"snow", "2":"black", "3":"red", "4":"blue","5":"yellow","6":"green","7":"orange","8":"pink"},
)
fig.update_traces(marker_size=25, marker_line_width=3)
fig.show()
color_discrete_map の場合は、値と色の辞書を直接指定する形になります。個人的にはこちらのほうが直感的で好みです。ただし凡例では順番がバラバラのままで表示されるのでご注意ください。

Plotly graph objectsの場合
Plotly graph objectsでscatterを書く場合はこうなります。
import plotly.graph_objects as go
fig = go.Figure()
fig.add_trace(
go.Scatter(x = df["diff"], y = df["side"],
mode = 'markers',
marker = dict(size=25, line_width=3),
)
)
fig.show()

で、Plotly expressと同じように色のマッピングをしていきたいところですが、color_discreate_map みたいな便利なものがPlotly graph objectsには存在しないようです。いろいろ調べてみたところ、以下のように書いてみたらできました。
import plotly.graph_objects as go
color_map = {"1":"snow", "2":"black", "3":"red", "4":"blue","5":"yellow","6":"green","7":"orange","8":"pink"}
colors = [color_map[val] for val in df["waku_no"]]
fig = go.Figure()
fig.add_trace(
go.Scatter(x = df["diff"], y = df["side"],
mode = 'markers',
marker = dict(size=25, line_width=3, color=colors),
)
)
fig.show()
最初に色のマッピングを辞書で作り、次にDataFrameの枠番と照らし合わせて色名が入った配列を作成、それをマーカーに指定する、という感じになります。Plotly expressのdiscrete colorに比べると、ちょっとわかりにくいですね・・・。
色々調整して最終的にはこんな感じです。個人的に隊列は上向きで右側を内にしたかったので、x軸とy軸は入れ替えてます。グリッドも最小にしました。
import plotly.graph_objects as go
color_map = {1:"snow", 2:"black", 3:"red", 4:"blue",5:"yellow",6:"green",7:"orange",8:"pink"}
colors = [color_map[val] for val in df["waku_no"]]
fig = go.Figure()
fig.add_trace(
go.Scatter(y = df["diff"], x = df["side"],
mode = 'markers',
marker = dict(size=25, line_width=3, color=colors),
)
)
fig.update_xaxes(title = '外 <----- 内外 -----> 内', range=[6,0], dtick=1, visible=True, showticklabels=True, zerolinecolor='LimeGreen', gridcolor='LimeGreen')
fig.update_yaxes(title = '後 →→→→→ 前後(馬身) →→→→→ 前', range=[20, -1], zerolinecolor='LightGreen', gridcolor='LightGreen', dtick=5,showticklabels=True)
fig.update_layout(
title = 'コーナー通過順',
width=400, height=800,
plot_bgcolor="LimeGreen",
)
fig.show()

複数のグラフを横に並べる
コーナー通過順は通常各コーナーごとに記載されています(ただし、競馬場や距離によって、2つだったり4つだったりという違いはあります。)。各コーナーごとの推移がわかるとレース展開がわかりやすいですよね。
ということで、2022年の有馬記念の3コーナー、4コーナーの通過順位のグラフを横に並べてみます。
まずPlotlyに渡すDataFrameを作成します。
import pandas
url = "https://race.netkeiba.com/race/result.html?race_id=202206050811&rf=race_list"
dfs = pd.read_html(url)
df_race_result = dfs[0]
str_corner3 = dfs[3][1][2]
str_corner4 = dfs[3][1][3]
pass_parsing = ParsePass()
df_corner3 = pass_parsing.parse(str_corner3)
pass_parsing = ParsePass()
df_corner4 = pass_parsing.parse(str_corner4)
df_race_result["馬番"] = df_race_result["馬番"].astype(str)
df_merged3 = pd.merge(df_corner3, df_race_result, left_on="horse_no", right_on="馬番")
df_merged4 = pd.merge(df_corner4, df_race_result, left_on="horse_no", right_on="馬番")
pandasで便利なのは pd.read_html です。URLを指定するとそのページをスクレイプして、tableタグからDataFrameを生成してくれます。シンプルなものならBeautifulSoupとかSeleniumをわざわざ使う必要もなくてよいですね。tableタグが複数ある場合は配列になります。2022年有馬記念の結果ページだとこうなります。

コーナー通過順位はインデックス3のテーブルにありますので、ここから3コーナーと4コーナーの文字列を取得してParsePassクラスに渡して、それぞれのDataFrameを作成します。コーナー通過順位には枠番が含まれていないので、インデックス0のレース結果のテーブルもDataFrameにして、ParsePassクラスから生成したDataFrameとマージして枠番の情報を追加します。
こうなります。
display(df_merged3.head(10))
display(df_merged4.head(10))

枠番、馬番、先頭からの馬身差、内外の位置が全て入った状態になりました。
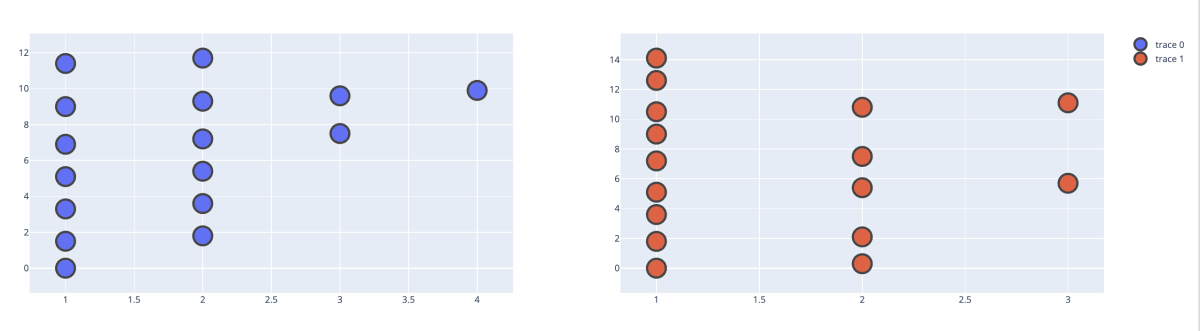
ではPlotlyで可視化します。複数のグラフを並べて表示するには make_subplot を使います。行と列の数を指定して複数のグラフの並びを設定します。今回の場合は横並びに2つ表示したいので以下になります。
import plotly.graph_objects as go
from plotly.subplots import make_subplots
fig = make_subplots(rows=1, cols=2)
次に add_trace で各DataFrameごとにグラフを追加します。ここでどのカラムに表示するかを指定します。
fig.add_trace(
go.Scatter(y = df_merged3["diff"], x = merged3["side"],
mode = 'markers',
marker = dict(size=25, line_width=3),
), row=1, col=1 # ここ
)
fig.add_trace(
go.Scatter(y = merged4["diff"], x = merged4["side"],
mode = 'markers',
marker = dict(size=25, line_width=3),
), row=1, col=2 # ここ
)
最後にグラフを表示します。
fig.show()
こうなります。
横並びが出来たので後は調整です。
import plotly.graph_objects as go
from plotly.subplots import make_subplots
import math
fig = make_subplots(rows=1, cols=2, subplot_titles=('3コーナー', '4コーナー'))
color_map = {1:"snow", 2:"black", 3:"red", 4:"blue",5:"yellow",6:"green",7:"orange",8:"pink"}
colors3 = [color_map[val] for val in df_merged3["枠"]]
colors4 = [color_map[val] for val in df_merged4["枠"]]
diff_max=0
for d in [df_merged3, df_merged4]:
if d["diff"].max() > diff_max:
diff_max=df["diff"].max()
diff_max = math.ceil(diff_max)
fig.add_trace(
go.Scatter(y = df_merged3["diff"], x = df_merged3["side"],
mode = 'markers',
marker = dict(size=25, line_width=3, color=colors3),
showlegend=False,
), row=1, col=1
)
fig.add_trace(
go.Scatter(y = df_merged4["diff"], x = df_merged4["side"],
mode = 'markers',
marker = dict(size=25, line_width=3, color=colors4),
showlegend=False,
), row=1, col=2
)
fig.update_xaxes(title = '外 <----- 内外 -----> 内', range=[6,0], dtick=1, visible=True, showticklabels=True, zerolinecolor='LimeGreen', gridcolor='LimeGreen' ,row=1,col=1)
fig.update_yaxes(title = '後 →→→→→ 前後(馬身) →→→→→ 前', range=[20, -1], zerolinecolor='LightGreen', gridcolor='LightGreen', dtick=5,showticklabels=True, row=1,col=1)
fig.update_xaxes(title = '外 <----- 内外 -----> 内', range=[6,0], dtick=1, visible=True, showticklabels=True, zerolinecolor='LimeGreen', gridcolor='LimeGreen' ,row=1,col=2)
fig.update_yaxes(title = '後 →→→→→ 前後(馬身) →→→→→ 前', range=[20, -1], zerolinecolor='LightGreen', gridcolor='LightGreen', dtick=5,showticklabels=True, row=1,col=2)
fig.update_layout(
title = 'コーナー通過順',
width=800, height=800,
plot_bgcolor="LimeGreen",
)
fig.show()
こんな感じになります。
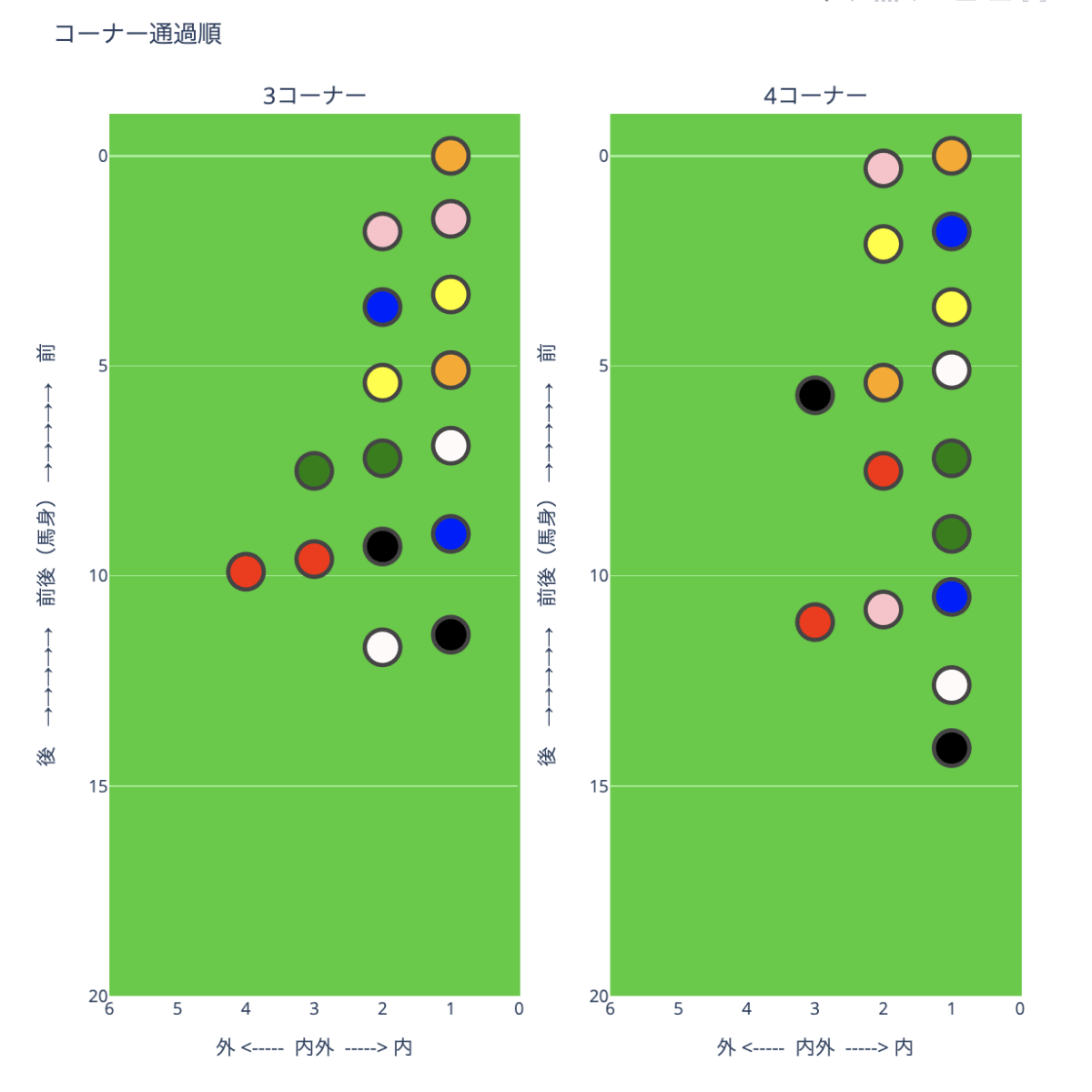
コードの詳細は割愛しますが、いくつか気になったポイントだけ記載しておきます。興味があれば色々いじってみて下さい。
- 内外がそれほど大きくなることはないと仮定してとりあえず最大6で固定していますが、馬身差はレースによってかなり変わってきます。Plotlyはプロットされたデータからレイアウトをある程度自動で生成しているようなので、このあたりが生成されるグラフの大きさに影響します。なるべくよしなになるように馬身差の最大値を元に調整するような処理を入れていますが、場合によってはいい感じに出力されない可能性があります(馬身差が終始詰まっているようなレースなど)。ここはもう少し調整が必要かなと思っています。
- 上記で生成したDataFrameには馬名などの付加情報も入っているので、
hovertemplateでそれを表示するようにするとインタラクティブでいいですね。Colaboratoryのコードでは馬名だけ表示するようにしてあります。 - Plotly graph objectsについて
- いろいろ細かく設定できていいのですが設定箇所が、graph object/update_layout/update_naxesなど、分散するのでわかりにくいです。パラメータが多くなるのは致し方ないとは思いながらも、ドキュメント探すのも結構大変。Plotly expressに比べるとサンプルコードも少ないようなので、もっとサンプルがほしいなと思いました。
- make_subplotを使った場合、xaxis/yaxisの設定もまるっとupdate_layoutでできるのかと思いきや、update_naxesなのは初見ではわかりませんでした。update_layoutでやると1つ目のグラフだけに適用されて???となりました。。。
まとめ
当初は競馬のデータ解析を「なるべくお手軽に」「コードを書かず」にやりたくて、BIツールをいろいろ試していました。ただ、私の目的ではどれもグラフの表現力で痒いところに手が届かず、自分で作ることを考え始めたところでPlotlyを見つけて試してみた結果、求めていたことはほぼ達成できたのでとても満足しています。
Pythonも普段使っている言語ではなくpandasもまだ見様見真似なのですが、Colaboratoryなどかんたんに試せる環境もそろっていて良いですね。Streamlit/Dashなどを使えばアプリとして公開もできるようだし、もっとインタラクティブにもできそうなので、いろいろ触ってみます。
そして、今年こそ有馬記念、当てたい!
Discussion
今年も有馬記念はハズレ。来年こそは忘れたものを取りにいけるように。。。。(ドウデュース本命なのにスターズオンアースの大外は厳しいと思ってしまった、やはり競馬は武豊とルメール。。。)
ちなみに今はStreamlitも組み合わせてこんな感じになっています。
毎週スクレイプして前処理回すだけで、全レースの結果を様々な観点で可視化してくれるので、良き。
今ならGPT-4-Vision使ってできないかなと思っている。
JRA公式がこういうことやってるんだけど、これがデータとして使えるようになるかどうかは今のところわからないし。
pyparsing作者の方から自分の個人ブログの方にコメントいいただいてしまった。ちょっと感激。
自分が主にやったのは可視化部分で、基本的なアイデアは以下の記事の方のものをベースにほんの少しだけ手を入れただけである。改めて以下の記事の方に感謝したい。