データサイエンス100本ノック(構造化データ加工編)やってみる~SQL編~
リポジトリ:
Install
git clone git@github.com:The-Japan-DataScientist-Society/100knocks-preprocess.git
cd 100knocks-preprocess
docker compose up -d --build --wait
早速こける
[+] Building 10.3s (6/6) FINISHED
=> [dss-postgres internal] load build definition from Dockerfile 0.0s
=> => transferring dockerfile: 392B 0.0s
=> [dss-notebook internal] load build definition from Dockerfile 0.0s
=> => transferring dockerfile: 1.80kB 0.0s
=> [dss-postgres internal] load .dockerignore 0.0s
=> => transferring context: 2B 0.0s
=> [dss-notebook internal] load .dockerignore 0.0s
=> => transferring context: 2B 0.0s
=> ERROR [dss-postgres internal] load metadata for docker.io/library/postgres:15.1-bullseye 10.2s
=> ERROR [dss-notebook internal] load metadata for docker.io/jupyter/datascience-notebook:python-3.10.8 10.1s
------
> [dss-postgres internal] load metadata for docker.io/library/postgres:15.1-bullseye:
------
------
> [dss-notebook internal] load metadata for docker.io/jupyter/datascience-notebook:python-3.10.8:
------
failed to solve: rpc error: code = Unknown desc = failed to solve with frontend dockerfile.v0: failed to create LLB definition: failed to authorize: rpc error: code = Unknown desc = failed to fetch anonymous token: Get "https://auth.docker.io/token?scope=repository%3Ajupyter%2Fdatascience-notebook%3Apull&service=registry.docker.io": dial tcp: lookup auth.docker.io on 192.168.0.1:53: server misbehaving
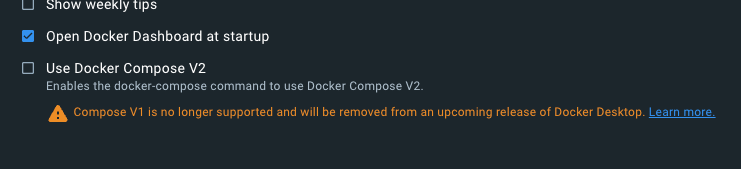
Dockerの「Use Docker Compose V2」のチェックを外したらうまくいった
おお、すごい。こんな感じか。
Postgreってシングルクォーテーションじゃないとだめなんだっけか
select sales_ymd as sales_ymdsales_date, customer_id, product_cd, amount from receipt where customer_id = 'CS018205000001' limit 10;
select sales_ymd as sales_ymdsales_date, customer_id, product_cd, amount from receipt where customer_id = "CS018205000001" limit 10;
〜以上〜以下は between だった
select
sales_ymd,
customer_id,
product_cd,
amount
from
receipt
where
customer_id = 'CS018205000001'
and amount between 1000 and 2000
limit 10;
以外は普通に product_cd != 'P071401019'
〜で始まる・終わる系は % をつけるんだった
// S-010: 店舗データ(store)から、店舗コード(store_cd)が"S14"で始まるものだけ全項目抽出し、10件表示せよ。
select * from store where store_cd like 'S14%' limit 10;
含むは % で囲う
select * from store where address like '%横浜市%';
正規表現でも可
// S-013: 顧客データ(customer)から、ステータスコード(status_cd)の先頭がアルファベットのA〜Fで始まるデータを全項目抽出し、10件表示せよ。
select * from customer where status_cd ~ '^[A-F]' limit 10;
~ はPostgre特有のPOSIX正規表現。
// S-015: 顧客データ(customer)から、ステータスコード(status_cd)の先頭がアルファベットのA〜Fで始まり、末尾が数字の1〜9で終わるデータを全項目抽出し、10件表示せよ。
select * from customer where status_cd ~ '^[A-F].*[1-9]$' limit 10;
S-016: 店舗データ(store)から、電話番号(tel_no)が3桁-3桁-4桁のデータを全項目表示せよ。
select * from store where tel_no ~ '[0-9]{3}-[0-9]{3}-[0-9]{4}$';
RANK functionなんてあったっけか。
S-019: レシート明細データ(receipt)に対し、1件あたりの売上金額(amount)が高い順にランクを付与し、先頭から10件表示せよ。項目は顧客ID(customer_id)、売上金額(amount)、付与したランクを表示させること。なお、売上金額(amount)が等しい場合は同一順位を付与するものとする。
SELECT
customer_id,
amount,
RANK() OVER(ORDER BY amount DESC) AS ranking
FROM receipt
LIMIT 10
;
同一順位のものに別の順位をつけたい場合は、 ROW_NUMBER() を使用する。
S-020: レシート明細データ(receipt)に対し、1件あたりの売上金額(amount)が高い順にランクを付与し、先頭から10件表示せよ。項目は顧客ID(customer_id)、売上金額(amount)、付与したランクを表示させること。なお、売上金額(amount)が等しい場合でも別順位を付与すること。
%%sql
select customer_id, amount, ROW_NUMBER() OVER(order by amount DESC) as ranking from receipt limit 10;
count(1)とcount(*)の結果は同じ
ごとに集計
S-023: レシート明細データ(receipt)に対し、店舗コード(store_cd)ごとに売上金額(amount)と売上数量(quantity)を合計せよ。
select store_cd, sum(amount), SUM(quantity) from receipt group by store_cd;
HAVINGとWHERE
WHERE
条件で抽出した結果をGROUP BYでグループ化します
WHERE→GROUP BY の順番
HAVING
GROUP BYでグループ化したあとにHAVINGの条件で抽出します
GROUP BY→HAVING の順番
中央値
S-028: レシート明細データ(receipt)に対し、店舗コード(store_cd)ごとに売上金額(amount)の中央値を計算し、降順でTOP5を表示せよ。
SELECT
store_cd,
PERCENTILE_CONT(0.5) WITHIN GROUP(ORDER BY amount) AS amount_50per
FROM receipt
GROUP BY store_cd
ORDER BY amount_50per DESC
LIMIT 5
;
postgreは以下のようにやるらしい
PERCENTILE_CONT(percent) WITHIN GROUP(ORDER BY sorted_args [ASC|DESC])
percentには0〜1の値
最頻値
S-029: レシート明細データ(receipt)に対し、店舗コード(store_cd)ごとに商品コード(product_cd)の最頻値を求め、10件表示させよ。
WITH product_cnt AS (
SELECT
store_cd,
product_cd,
COUNT(1) AS mode_cnt
FROM receipt
GROUP BY
store_cd,
product_cd
),
product_mode AS (
SELECT
store_cd,
product_cd,
mode_cnt,
RANK() OVER(PARTITION BY store_cd ORDER BY mode_cnt DESC) AS rnk
FROM product_cnt
)
SELECT
store_cd,
product_cd,
mode_cnt
FROM product_mode
WHERE
rnk = 1
ORDER BY
store_cd,
product_cd
LIMIT 10
;
WITH文
サブクエリ内で利用する一時的なテーブルを定義する構文です。一般的に、複数のクエリで同じ部分クエリを使用する場合や、複雑なクエリを分割する場合に利用される。
WITH
サブクエリ名1 AS (
サブクエリ1
),
サブクエリ名2 AS (
サブクエリ2
),
...
SELECT
カラム1,
カラム2,
...
FROM
メインテーブル
JOIN サブクエリ名1 ON 条件1
JOIN サブクエリ名2 ON 条件2
...
サブクエリ名:一時的なテーブルに付ける名前です。この名前を使用して、SELECT文のJOIN句でサブクエリを参照します。
サブクエリ:一時的なテーブルを作成するためのSQL文です。
PARTITION BY
OVER()は、ウィンドウ関数の演算範囲を指定するために使用されます。OVER()に指定された範囲内のレコードを取得し、集計関数やランキング関数などを適用することができます。この範囲を指定するために、PARTITION BY句を使用することができます。
OVER(PARTITION BY customer_name ORDER BY order_date)によって、顧客名でグループ化しているわけではないが、注文日順に累計金額を計算するために、顧客名でデータを分割している。
以下でも同じような結果になるが、最頻値が複数の場合は一つだけ選ばれる
select store_cd, MODE() WITHIN GROUP(ORDER BY product_cd) from receipt GROUP BY store_cd ORDER BY store_cd limit 10;
MODE() WITHIN GROUP(ORDER BY product_cd)は、商品コード(product_cd)を昇順に並べ替えた上で、最も頻度の高い商品コードを求める集計関数。この集計関数を、店舗コードごとにグループ化して計算することで、各店舗の最頻値を求めている。
分散
分散を求めるときは VAR_POP() (Variance of the population)を使用する。
S-030: レシート明細データ(receipt)に対し、店舗コード(store_cd)ごとに売上金額(amount)の分散を計算し、降順で5件表示せよ。
SELECT store_cd, VAR_POP(amount) as vars_amount from receipt GROUP BY store_cd ORDER BY vars_amount DESC limit 5;
標準偏差
STDDEV_POP(): Standard Deviation of the Population
S-031: レシート明細データ(receipt)に対し、店舗コード(store_cd)ごとに売上金額(amount)の標準偏差を計算し、降順で5件表示せよ。
select store_cd, STDDEV_POP(amount) as stddev_amount from receipt group by store_cd ORDER BY stddev_amount DESC limit 5;
何%刻み
S-032: レシート明細データ(receipt)の売上金額(amount)について、25%刻みでパーセンタイル値を求めよ。
select
PERCENTILE_CONT(0.25) WITHIN GROUP(ORDER BY amount) as amount_25per,
PERCENTILE_CONT(0.50) WITHIN GROUP(ORDER BY amount) as amount_50per,
PERCENTILE_CONT(0.75) WITHIN GROUP(ORDER BY amount) as amount_75per,
PERCENTILE_CONT(1.0) WITHIN GROUP(ORDER BY amount) as amount_100per
from receipt;
なんで名前つけたのにだめなんだろうか。
>> select store_cd, AVG(amount) AS avg_amount from receipt GROUP BY store_cd HAVING avg_amount >= 330 limit 10;
(psycopg2.errors.UndefinedColumn) 列"avg_amount"は存在しません
LINE 1: ... avg_amount from receipt GROUP BY store_cd HAVING avg_amount...
^
HAVING句では、集計関数(例えばAVGやSUMなど)で集計された値や、GROUP BY句で指定された列を条件式で参照することができるが、列名(AS hoge)による参照はできないらしい。
S-034: レシート明細データ(receipt)に対し、顧客ID(customer_id)ごとに売上金額(amount)を合計して全顧客の平均を求めよ。ただし、顧客IDが"Z"から始まるものは非会員を表すため、除外して計算すること。
with customer_amount AS(select customer_id, SUM(amount) as sum_amount from receipt WHERE customer_id not like 'Z%' GROUP BY customer_id) select AVG(sum_amount) from customer_amount;
S-035: レシート明細データ(receipt)に対し、顧客ID(customer_id)ごとに売上金額(amount)を合計して全顧客の平均を求め、平均以上に買い物をしている顧客を抽出し、10件表示せよ。ただし、顧客IDが"Z"から始まるものは非会員を表すため、除外して計算すること。
WITH customer_amount AS (
SELECT
customer_id,
SUM(amount) AS sum_amount
FROM receipt
WHERE
customer_id NOT LIKE 'Z%'
GROUP BY customer_id
)
SELECT
customer_id,
sum_amount
FROM customer_amount
WHERE
sum_amount >= (
SELECT
AVG(sum_amount)
FROM customer_amount
)
LIMIT 10
;
直積(すべての組み合わせ)
cross join知らなかった。
SELECT
COUNT(1)
FROM store
CROSS JOIN product
;
変換
to_char
S-045: 顧客データ(customer)の生年月日(birth_day)は日付型でデータを保有している。これをYYYYMMDD形式の文字列に変換し、顧客ID(customer_id)とともに10件表示せよ。
select
customer_id,
TO_CHAR(birth_day, 'YYYYMMDD') AS birth_day
from customer
limit 10;
TO_DATE
S-046: 顧客データ(customer)の申し込み日(application_date)はYYYYMMDD形式の文字列型でデータを保有している。これを日付型に変換し、顧客ID(customer_id)とともに10件表示せよ。
SELECT
customer_id,
TO_DATE(application_date, 'YYYYMMDD') AS application_date
FROM customer
LIMIT 10
;
CAST
S-047: レシート明細データ(receipt)の売上日(sales_ymd)はYYYYMMDD形式の数値型でデータを保有している。これを日付型に変換し、レシート番号(receipt_no)、レシートサブ番号(receipt_sub_no)とともに10件表示せよ。
SELECT
receipt_no,
receipt_sub_no,
TO_DATE(CAST(sales_ymd AS VARCHAR), 'YYYYMMDD') AS sales_ymd
FROM receipt
LIMIT 10
;
UNIX秒を日付に
S-048: レシート明細データ(receipt)の売上エポック秒(sales_epoch)は数値型のUNIX秒でデータを保有している。これを日付型に変換し、レシート番号(receipt_no)、レシートサブ番号(receipt_sub_no)とともに10件表示せよ。
SELECT
receipt_no,
receipt_sub_no,
CAST(TO_TIMESTAMP(sales_epoch) AS DATE) AS sales_ymd
FROM receipt
LIMIT 10
;
S-049: レシート明細データ(receipt)の売上エポック秒(sales_epoch)を日付型に変換し、「年」だけ取り出してレシート番号(receipt_no)、レシートサブ番号(receipt_sub_no)とともに10件表示せよ。
SELECT
receipt_no,
receipt_sub_no,
EXTRACT(YEAR FROM TO_TIMESTAMP(sales_epoch)) AS sales_year
FROM receipt
LIMIT 10
;
EXTRACT関数は、日付や時刻型のデータから指定した時間要素(年、月、日、時、分、秒)を抽出するSQLの関数。
EXTRACT(field FROM source)
0埋め
S-050: レシート明細データ(receipt)の売上エポック秒(sales_epoch)を日付型に変換し、「月」だけ取り出してレシート番号(receipt_no)、レシートサブ番号(receipt_sub_no)とともに10件表示せよ。なお、「月」は0埋め2桁で取り出すこと。
SELECT
receipt_no,
receipt_sub_no,
TO_CHAR(
EXTRACT(MONTH FROM TO_TIMESTAMP(sales_epoch)),
'FM00'
) AS sales_month
FROM receipt
LIMIT 10
;
条件分岐
二値化という言葉を初めて聞いた。
S-052: レシート明細データ(receipt)の売上金額(amount)を顧客ID(customer_id)ごとに合計の上、売上金額合計に対して2,000円以下を0、2,000円より大きい金額を1に二値化し、顧客ID、売上金額合計とともに10件表示せよ。ただし、顧客IDが"Z"から始まるのものは非会員を表すため、除外して計算すること。
SELECT
customer_id,
SUM(amount) AS sum_amount,
CASE
WHEN SUM(amount) > 2000 THEN 1
ELSE 0
END AS sales_flg
FROM receipt
WHERE customer_id NOT LIKE 'Z%'
GROUP BY customer_id
LIMIT 10
;