Scrapy理解したい
リクエスト・レスポンス関連
その他非公式ドキュメント
プロジェクト開始と構成
$ scrapy startproject {プロジェクト名}
$ tree
.
├── __init__.py
├── items.py
├── middlewares.py
├── pipelines.py
├── settings.py
└── spiders
└── __init__.py
1 directory, 6 files
scrapy.cfg
spiderの作成やデプロイ等の設定?
items.py
scrapyで取得したデータの入れ物(Item)、dictで代用もできるっぽい
フィールドを持っている
class ZennItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
pass
middlewares.py
リクエストとレスポンス、ダウンロードに関連する追加処理を書く。
HogeSpiderMiddlewareでリクエストとレスポンスの拡張。
HogeDownloaderMiddlewareでダウンロード処理の拡張。
pipelines.py
Webサイトから取得したデータのチェックやクレンジング、更新処理など
settings.py
設定ファイル
Scrapyでの開発の流れ:基本
ヨドバシ.com - デスクトップパソコン 通販【全品無料配達】
1. 取りたい箇所を開発者ツールなどで特定。それらをまとめ上げている親の要素を取得方法検討
相対XPathなどを使用
//div[contains(@class, "productListTile")]
div.productListTile
//div[contains(@class, "pName")]/p/text()
//div[contains(@class, "pName")]/p[2]/text()
2. scrapy shellで確認
3. PJの作成・settings.pyの設定
$ scrapy genspider スパイダー名 URL
4. scrapy genspiderでspiderを作成、実装・実行
Spider作成
$ scrapy genspider [-t テンプレート名] スパイダー名 <domain or URL>
// 利用可能なテンプレート一覧(未指定ならbasic)
$ scrapy genspider -l
Available templates:
basic
crawl
csvfeed
xmlfeed
Even if an HTTPS URL is specified, the protocol used in start_urls is always HTTP. This is a known issue: issue 3553.
$ scrapy genspider zenn_trend zenn.dev
Created spider 'zenn_trend' using template 'basic'
zenn.spiders.zenn_trend
spidersディレクトリの中にファイルが作成される。
spiderの中でオーバーライド等して処理を目的に併せたものに変えていく
import scrapy
class ZennTrendSpider(scrapy.Spider):
name = 'qiita_trend_1d'
allowed_domains = ['zenn.dev']
// httpsに変更
start_urls = ['https://zenn.dev/']
def parse(self, response):
pass
allowed_domainsが意図したドメインのみスクレイピングするように設定しておくのが推奨されている。
Scrapy Shellを使う
スパイダーを実行することなく、非常に迅速にスクレイピングコードを試行およびデバッグできる対話型シェル
先にipythonをインストールしておく。
$ poetry add ipython@7.34
$ scrapy shell {URL}
//もしくは
$ scrapy shell
In [1]: fetch("{URL}")
取得
// xpath
$ category = response.xpath('//h2/a/text()')
$ category = response.xpath('//h2/a/text()').get()
$ category = response.xpath('//h2/a/text()').getall()
// css
category = response.css('h2 > a::text')
category = response.css('h2 > a::text').get()
category = response.css('h2 > a::text').getall()
TODO
response.xpath('//a[@href="/trend"]/text()') これなぜかとれない?
response.xpath('//a[contains(@href, "trend")]')変な結果に...?
=> response.xpath('//a[@class="st-NewHeader_mainNavigationItem is-active"]/text()').get() これはいける。hrefでの指定は難しいのか...?
設定
settings.py
FEED_EXPORT_ENCODING = 'utf-8'
DOWNLOAD_DELAY = 5
# Obey robots.txt rules
ROBOTSTXT_OBEY = True
DEFAULT_REQUEST_HEADERS = {
# 'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
'Accept-Language': 'ja',
}
htmlキャッシュ
トライアンドエラーで何度もページダウンロードすると時間かかる。なので2回目いこうは保存したキャッシュを使うようにさせる設定。
HTTPCACHE_ENABLEDを有効にするとデフォルトだとPJ配下の.scrapy/httpcacheディレクトリ下にキャッシュが作られる。またデフォルトではキャッシュの期限はない。
HTTPCACHE_ENABLED = True
# 保存先ディレクトリ
HTTPCACHE_DIR = 'httpcache'
# キャッシュの有効期限
HTTPCACHE_EXPIRATION_SECS = 86400 # 1日
Useragent
botでないように見せることが出来る。
USER_AGENT = 'User-Agent: Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/109.0.0.0 Safari/537.36'
robots.txt
User-agent:対象クローラーの指定
Disallow/Allow:ブロック・許可
User-agent:*
Disallow:/kuma-dir/
DEPTH_LIMIT:任意のサイトでクロールできる最大深度。
Spider実装と実行
yield
実装
def parse(self, response):
field1 = response.xpath('{XPath}')
field2 = response.css('{CSS}')
yield {
"field1": field1,
"field2": field2,
}
link = response.xpath('{XPath}').get()
yield response.follow(url=link)
実行
$ cd {scrapy.cfgのあるディレクトリ}
$ scrapy crawl {スパイダー名}
$ scrapy crawl {スパイダー名} -o {保存json名.json}
XPath(XML Path Language)
XML形式の文書から、特定の部分を指定して抽出するための簡潔な構文(言語)
htmlから順番に指定でなくいきなり指定するには//とつけてやる
要素[@属性=属性値]
//option[@selected="selected"]/text()
//h2/a/text()
//h2/a/@href
ロケーションパスは/ノードテスト/ノードテスト/ノードテスト
属性と取得
属性取得の時のロケーションパスは/ノードテスト[述語]/ノードテスト/ノードテストといった感じ
任意の属性がkumaのhrefが取りたい時
//a[@*="kuma"]@href
属性にある特定の値が含まれているかを見たい時
contains、not、and、or、starts-with、ends-with
//a[contains(@href, "hogehoge")]
//a[not(contains(@href, "hogehoge"))]
//a[not(contains(@href, "hogehoge")) and contains(@id, "link1")]
//a[not(contains(@href, "hogehoge")) or contains(@id, "link1")]
//a[starts-with(@href, "http:")]
//a[starts-with(@href, "http:")]
//a[ends-with(@href, "/fugafuga")]
テキストにある特定の値が入っているかを見たい時
テキストの検索(大文字/小文字も区別)
//a[contains(text(), "くまもと日記")]
リストの要素の取得
スクエアブラケット[]で数字を指定していく。プログラムと違い1から始まる。
position()を使うと複数指定も容易。比較演算子を使った指定も出来るように。
//ul[@class="book"]/li[1]
//ul[@class="book"]/li[position()=3]
//ul[@class="book"]/li[position()=2 or position()=3]
//ul[@class="book"]/li[position()=last()]
//ul[@class="book"]/li[position()>=2]
//ul[@class="book"]/li[position()>2]
親(先祖)・兄弟・子孫:軸
自分より「親」、自分から見て「孫」といった指定をやる方法。

参考:図解!XPathでスクレイピングを極めろ!(Python、containsでの属性・テキストの取得など) - AI-interのPython3入門より
Selectorオブジェクトに対してXPathを指定する際は最初にドット(.)を付けてやること。
products = response.xpath('//div[contains(@class, "productList")]')
for product in products:
maker = product.xpath('.//div[contains(@class, "makerName")]/p/text()')
- 親
(1)親タグが<p>だとわかっているとき
//a[@id="link2"]/parent::p
(2)親タグがわかっていないとき
//a[@id="link2"]/parent::node()
- 先祖(nodeをたどって一番上のRootまで)
(1)ご先祖様を辿る
//a[@id="link2"]/ancestor::node()
(2)自分も含める
//a[@id="link2"]/ancestor-or-self::node()
- 先祖を除く前
//a[@id="link2"]/preceding::node()
- 自分の属性値を取る
//a[@id="link2"]/attribute::node()
その他
normalize-spaceで余計な改行・空白をとる
CSS Selector TODO
要素[属性="属性値"]
[属性="属性値"]
option[selected="selected"]::text
h2 > a::text
h2 > a::attr(href)
リンクを辿る
ページネーションで分けられているサイトで複数ページを見る必要があるときなど。
scrapy.Request(URL, callback=コールバック関数)
URLは絶対URL
response.follow(URL/Selector, callback=コールバック関数)
URLは絶対・相対どちらでもOK
a要素のSelectorから自動でhref属性のリンクを取得してくれる(ちょっと注意が必要だけど)
# for文に組み込む
next_page = response.xpath('//a[@class="next"]/@href').get()
if next_page:
yield response.follow(url=next_page, callback=self.parse)
Scrapyのクロール結果をファイル出力させる
タイムスタンプ(%(time)s)、スパイダー名(%(name)s)
$ scrapy crawl スパイダー名 -o data.json
$ scrapy crawl スパイダー名 -o data.csv
$ scrapy crawl スパイダー名 -o data.xml
PJ配下にファイルが作成される。
UserAgent
「ネット利用者が使用しているOS・ブラウザ」のこと。アクセス解析に利用されることが多い。サイト側は、OSやブラウザバージョンによって表示を切り替えたりすることも可能だ。
ただしユーザーエージェント名は、ブラウザの利用者が任意に変更することも可能。
開発者コンソールのNetworkのHeaders内にUserAgentが確認出来るよ。
User-Agent: Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/109.0.0.0 Safari/537.36
ScrapyでのUserAgentの確認
response.request.headers['User-Agent']
> [scrapy.utils.log] INFO: Scrapy 2.7.1 started (bot: kuma)
UserAgentを変更する
settings.pyを変更
# Crawl responsibly by identifying yourself (and your website) on the user-agent
USER_AGENT = 'User-Agent: Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/109.0.0.0 Safari/537.36'
2023-01-27 20:54:39 [root] INFO: b'User-Agent: Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/109.0.0.0 Safari/537.36'
Books to Scrapeでの練習(basicテンプレート編) TODO
書籍タイトルとURLの取得
次ページへ
次ページでの取得
詳細ページの情報取得
BasicテンプレートからCrawlテンプレートへ
CrawlSpiderを使えばリンクをたどっていくのがよりやりやすく!
$ scrapy genspider -l
Available templates:
basic
crawl
csvfeed
xmlfeed
crawlテンプレートでの作成
$ scrapy genspider -t crawl スパイダー名 URL
spiderを確認するとbasicテンプレートを使用した時と違いrulesがタプルで定義されている。(複数付けることが出来る)
rules = (
Rule(LinkExtractor(allow=r'Items/'), callback='parse_item', follow=True),
)
LinkExtractor内でallowとdenyでそのリンク(正規表現)を辿るか指定出来る。
XPathやCSSセレクタも使える。restrict_xpaths=('//a[@class="kuma"]', '2つめのXPath')
(/@hrefはつけなくてOK)
callbackはresponseを処理する関数。(parse単体は予約語なので使わないこと)
followはレスポンス内のリンクを更に辿るかどうかの指定。
Scrapy Ruleオブジェクト
リンクを辿る各規則を記述。
-
LinkExtractor
クロールされた各ページからリンク抽出する方法を定義
正規表現ならallow、XPathならrestrict_xpathsを使う。 -
callback
リンク先のresponseを処理するコールバック関数 -
follow
さらにリンク先のリンクを踏むか
follow は, このルールで抽出された各レスポンスからリンクをたどるかどうかを指定する bool 値です. callback が None の場合, follow のデフォルトは True になります. それ以外の場合は False にデフォルト設定されます
Rule処理は繰り返される
Ruleでは1つ目、2つ目と、全てのRuleに全く該当するものが無くなるまで処理を繰り返す
例えば複数の商品が複数のページに渡ってあるようなECサイトがあるとき、
rules = (
# 1. 商品ページリンク
Rule(
LinkExtractor(restrict_xpaths='商品ページXPath'),
callback="parse_item",
follow=False,
),
# 2. ページ内の商品リンクを巡ったら、次へページを押して1の処理を。次ページがなくなるまで
# コールバックメソッドが不要なのは、2つ目のRuleでは、次のページへのリンクをたどるだけで、取得するデータが無いから
Rule(
LinkExtractor(restrict_xpaths='次へボタンのXPath'),
follow=True,
),
)
というrulesを定義したとき、1=>2=>1=>2....ときて2の処理が次ボタンがないページで止まることでこのrules全体の処理も止まるように出来ている。
ちなみに2つ目のルールでfollowにFalseを設定すると、最初のページの商品データを取得して処理は終了する。つまり、2週目の1つ目のルールは実行されずに終わる。
1つ目のルールでは「詳細ページのURLを取得し、コールバックメソッドでデータを取得する」設定で、2つ目のルールは「次のページも、これら2つのルールで処理する」設定。
デバッグもろもろ
外部ファイルからの呼び出し
ファイルの置き場所はconfigファイルと同じディレクトリにすること。
import scrapy
from scrapy.crawler import CrawlerProcess
from scrapy.utils.project import get_project_settings
if __name__ == "__main__":
# 外部スクリプトから実行するのに必要
process = CrawlerProcess(settings=get_project_settings())
# Spiderのnameの値で指定
process.crawl("スパイダーのname")
process.start()
LOGGING ログの出力
settings.pyにログの出力ファイルと出力ログレベルを設定。
LOG_FILE = 'log.txt'
LOG_LEVEL = 'INFO'
parseコマンド
メソッドレベルの実行が出来る。
scrapy parse --spider={スパイダー名} -c {parseメソッド名} {URL}
scrapy parse --spider={スパイダー名} -c {parseメソッド名} -d {階層レベル} -v {URL}
-c CALLBACK, --callback CALLBACK
use this callback for parsing, instead looking for a callback
--spider SPIDER use this spider without looking for one
scrapy shell
response確認。
from scrapy.shell import inspect_response
# parseのメソッド内に記述
inspect_response(response, self)
scrapy crawlを実行するとinspect_responseの実行箇所でshellが立ち上がる。
データ取得順を制御したい
ページに表示される順に取得されていると思いきや結構な頻度で違う順で入っていることが...
scrapyはrulesに記載されている順でなく効率的なデータ収集順になるように動いているのが原因?
LIFOで深さ優先でやっているみたい
settings.pyで下記のように設定
# scrapyが同時に処理するリクエストの数を1つに制限
CONCURRENT_REQUESTS = 1
# 低い階層のリクエストから順番に処理してくれるように
DEPTH_PRIORITY = 1
# 以下2つの設定変更でLIFOからFIFOに
SCHEDULER_DISK_QUEUE = 'scrapy.squeues.PickleFifoDiskQueue'
SCHEDULER_MEMORY_QUEUE = 'scrapy.squeues.FifoMemoryQueue'
Scrapyの構成

参考:データ収集の効率を圧倒的に高めるスクレイピングFW【Scrapy】 - ROXX開発者ブログより
Spider
どのようにスクレイピング・抽出するか。主にコーディングする箇所はここ。
Engine
全体の統御を行う
Scheduler
リクエストをQueueとして管理。リクエストの順番・スケジューリングを行う。
Downloader
リクエストで指定されたURLのウェブページをダウンロード
Item Pipeline
抽出したデータを処理(クレンジング・チェック・DBへの保存)
Feed Exporter
データをcsvやjsonなどのファイルに出力
Middleware
Spider MiddlewareとDownload Middleware
全体の流れ
1. starts_urlのurlをEngineにリクエスト
2. EngineはリクエストをSchedulerに転送
3. Schedulerはリクエストのスケジューリングをする、順番を決める
4. Scheduleはリクエストを再度Engineに転送
5. EngineはDownload Middlewareを経由してDownloaderに
6. DownloaderはHTMLなどをウェブページからダウンロード
7. DownloaderからレスポンスがEngineに
8. EngineはレスポンスをSpiderMiddlewareを経由してSpiderへ
9. Spiderではデータ抽出をXPathやCSSセレクタなどを用いて行ったりリクエストを行ったり
9-1. 別のリンクのURLを抽出し、リンクを辿っていく(この時はまたEngine=>Downloader...の流れ)
9-2. 必要なテキストのデータを抽出
10. csvやjsonに出力・保存する場合はItemPipelineの処理はパスしてFeedExporterへ
11.もしくは Itemに格納してEngine=>ItemPipelineで処理・DB保存
Scrapy-seleniumでDownloadMiddlewareを設定する。また別途Item Pipelineの設定をする。
Item、ItemLoader、ItemPipeline
-
Item
Webサイトから取得したデータの入れ物 -
ItemLoader
Itemへのデータの格納に利用、inputプロセッサとoutputプロセッサ -
ItemPipeline
格納したデータに一連の処理(チェック・クレンジング・DB保存)を行う
Item:Webサイトから取得したデータの入れ物
Fieldを持つのでデータ構造を保ってくれる。DBの1レコード=Item1つといった感じ。
items.pyにHogeItemを定義(フィールドを付けていく)。その後、それぞれのspiderのpythonファイルでimportを行う。
from hoge.items import HogeItem
from scrapy.loader import ItemLoader
spider側でfieldごとに詰め作業をして最後にload_itemをyieldする
loader = ItemLoader(item=HogeItem(), response=response)
loader.add_xpath(
"フィールド1",
'//XPath1',
)
loader.add_xpath(
"フィールド2",
'//XPath2',
)
yield loader.load_item()
※temのフィールド名誤るときっちりKeyErrorになってくれるので安心
ItemLoader:データの格納に利用
取得データをItemに格納する。
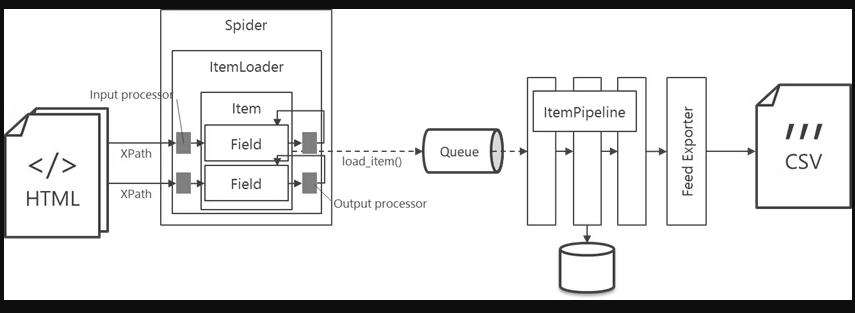
Input processor
値を Item Loader 経由で Item に格納するときに、その値を加工する仕組みです。Field 毎に一つ設定できます。
Output processor
Item Loader から Item インスタンスを取り出すときに、Field 情報を加工する仕組みです。Field 毎に一つ設定できます。
参考:ItemとItem Loaderを使ったScrapyの書き方 + 小ネタ集 - Qiita
いずれのprocessorの処理もitems.pyに記述することで複数のspiderで使い回し出来るようにしているみたい。
入力プロセッサでは空白除去など取得したデータに対する処理。出力プロセッサではリストからstrに直したりなどを入れたり...(ここらへんは結構ユーザーに委ねられている)
組み込み型のプロセッサをitems.pyにimport
from itemloaders.processors import TakeFirst, MapCompose, Join
-
TakeFirst
リストの最初を取る -
MapCompose
何か関数を実行したい時に使用 -
Join
リストの結合を行う
Item PipeLine:格納したデータに一連の処理を行う
Itemに保存されたデータのクレンジング・チェック・DBへの保存などを担当する
メソッドごとの処理のタイミング 🔥
-
from_crawler(cls, crawler)
クラスメソッド、Pipelineがインスタンス化される際に実行 -
open_spider(self, spider)
spiderの開始時に実行 -
process_item(self, item, spider)
全てのItem Pipelineに対して実行 -
closes_pider(self, spider)
spiderの終了時に実行
データチェック・クレンジング
例えばあるFieldの値がないItemは保存したくない・破棄した時
まずpipeline.pyに設定
from scrapy.exceptions import DropItem
class CheckItemPipeline:
def process_item(self, item, spider):
if not item.get('特定のFieldの値'):
raise DropItem('Missing ISBN')
return item
次にsettings.pyにpipelineの有効化設定
# 数字が小さいほど先に実行される
ITEM_PIPELINES = {
'hoge_pj.pipelines.CheckItemPipeline': 100,
}
DBへの保存
pipelines.pyに新規のPipelinクラスを追加。
def sample_geniter():
yield from [1, 2, 3, 4]
print('finished')
for num in sample_geniter():
print(num)
print('hello')
---
1
2
3
4
finished
hello
これは最もシンプルなスパイダーで, 他のすべてのスパイダーが継承しなければならないものです(Scrapyにバンドルされたスパイダー, あなた自身で作成したスパイダーを含む). 特別な機能は提供しません. start_urls 属性からリクエストを送信し, スパイダーの parse メソッドを, レスポンス結果ごとに呼び出す start_requests() メソッドの実装を提供するだけです.
robots.txt
robots.txt ファイルとは、検索エンジンのクローラに対して、サイトのどの URL にアクセスしてよいかを伝えるものです。 これは主に、サイトでのリクエストのオーバーロードを避けるために使用され、Google にウェブページが表示されないようにするためのメカニズムではありません。