IOVST : Iterative Optimization Video Style Transfers の紹介
Video 向けの Iterative Optimization による StyleTransfer, IOVSTを公開しました!
- source code: https://github.com/hirokic5/IOVST
- youtube : https://youtu.be/iDNP2KfThEg
この記事では概要を紹介いたします。
実際にどのような動画ができるのかは youtube にアップした動画の後半をご覧ください。
IOVSTの特徴
- 通常の styletransfer および brushstroke styletransfer (CVPR2021) をサポート
- Iterative Optimization で styletransfer を行う
- 任意の content video, style image を対象にできる
- feed forward model ではなく、画像毎に最適化を行うため動画の生成に時間がかかる
- RAFT(ECCV 2020)で検出した optical flow を用いて、temporal consistency を保つ
- Artistic style transfer for videos で提案された multipass algorithm を採用することでより質の高い動画を生成する
以下、もう少し詳しく見ていきます
Brushstroke styletransfer
Rethinking Style Transfer: From Pixels to Parameterized Brushstrokes (CVPR 2021) で提案された styletransfer 手法です。
Styletransfer の分野ではそれまで画像を pixel ごとに更新することで styletransfer を行ってきましたが、この論文では brushstroke ごとに更新することを提案しています。
これにより、従来の styletrasnfer に比べてより「絵っぽさ」が出るようになります。
(図は論文より引用)
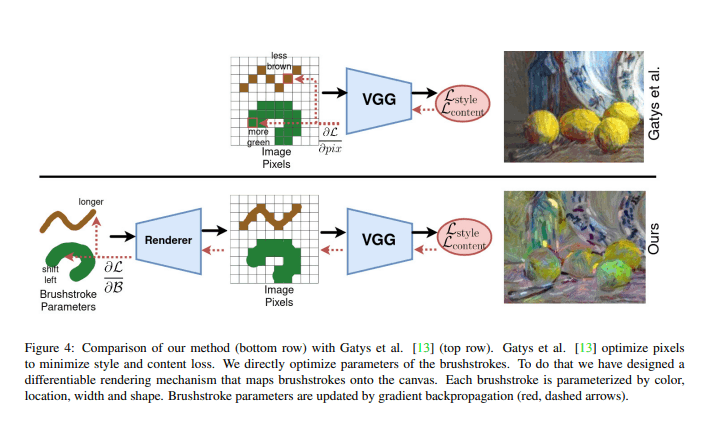
さらに、ユーザーからの入力をもとに brushstroke の方向などのコントロールもできます(が、IOVST ではその機能は実装しておりません)。
Reference
- official repository : https://github.com/CompVis/brushstroke-parameterized-style-transfer
- pytorch implementation : https://github.com/justanhduc/brushstroke-parameterized-style-transfer
Iterative optimization
Gatys らの styletransfer で提案されている、画像を更新対象として styletransfer を行う手法を指します。
Iterative optimization の特徴として以下が挙げられます。
- 任意の content, style を扱うことができる
- 画像ごとに最適化を行う関係で、大量の枚数を styletransfer するのに時間がかかる
Iterative optimization から始まった styletransfer ですが、画像の生成に時間がかかることから、その後は「feed forward model でいかに効率的な styletransfer を行うか」という方向に発展していきます。
一方で、「そもそも styletransfer の考え方はこれでよいのか?」という styletransfer の考え方へのアプローチをする研究は、Gatys らの研究との比較からか、Iterative optimization ベースで扱うことがあり、今回サポートしている brushstroke styletransfer でもそのようになっています。
Reference
- feed forward model で styletransfer を行う
- styletransfer 手法そのものに対してのアプローチ
Temporal consistency
Styletransfer に限らず、video のような連続する画像を入力にとり何かしらの変換操作を行うと、出力画像群にいわゆる「ちらつき」が発生することがままあります。Video を対象とした変換では時間軸で見たときの一貫性 = temporal concistency を保つことでこうした「ちらつき」を抑えることができるようになります。
Temporal consistency を保つ際にはフレームごとの pixel の動き = optical flow を推定し、それを活用することが多いです。Optical flow を用いて warping を行うことで、現在の出力画像と N frame 前の出力画像との差 = temporal loss を比較し、これを減らしていくことで temporal consistency が保たれた画像に近づけることできます。この際、いくつか注意点があります。
- optical flow の性能が遮蔽物等の関係で正確に計算できない場合があり、そのような領域は warping した結果と比較する際には取り除く必要がある
- N は複数種類、かつ、離れた値を使うと良い
- N が大きくなるほど optical flow は不正確になっていくため、N が小さい場合の結果を優先して使う
- N が小さい場合の領域と被っていない領域のみを活用する
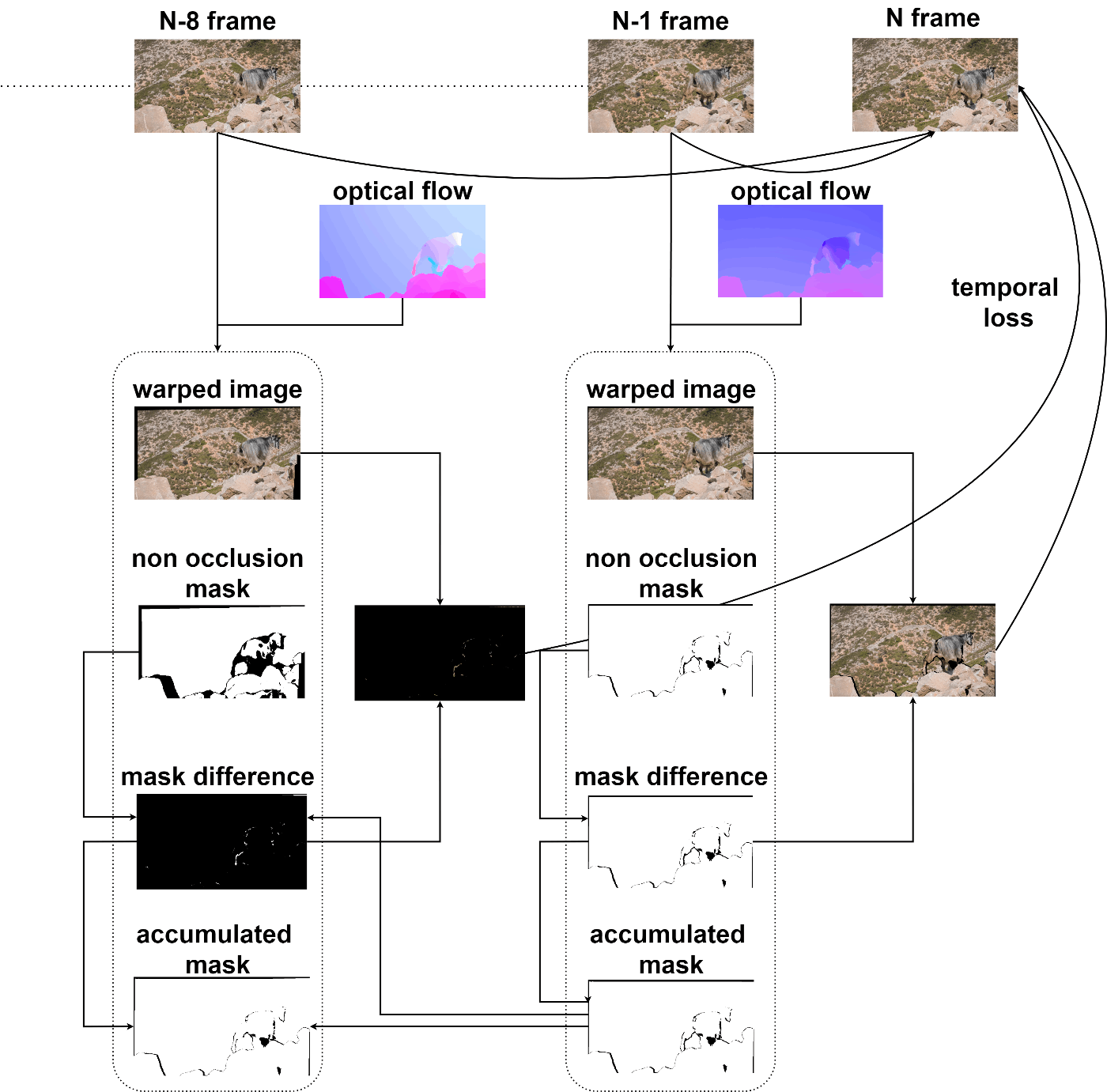
IOVSTではRAFTという手法を使い optical flow を推定しています。
Reference
- Artistic style transfer for videos (2016)
- ReCoNet: Real-time Coherent Video Style Transfer Network (2018)
- RAFT: Recurrent All-Pairs Field Transforms for Optical Flow (2020)
Multipass algorithm
Artistic style transfer for videos でも指摘されている通り、optical flow を用いて temporal consistency を保とうとしても、後ろのフレームに行くほど明らかに contrast が落ちていくという現象が起きてしまいます(実際には終盤のフレームで急に contrast が落ちるのではなく、1 frame 進むごとに少しずつ落ちているのですが、1 frame あたりでは微細な差であり目視ではあまりわかりません)。
これを解決するために、Artistic style transfer for videos で提案されている Multipass algorithm をIOVSTでは採用しています。
Multipass algorithm は以下のような特徴があります。
- temporal consistency を考慮しない styletransfer をまず全フレームに対して行う
- temporal consistency を考慮し、全フレームで改めて styletransfer を行う
- この時、N frame での初期値は N frame と optical flow warping した結果をブレンドする
- ブレンドすることで、contrast が落ちきることを防ぐ(が、ブレンドをする関係上1回では temporal consistency が保たれない)
- 2を繰り返し行う。繰り返し回数が多いほど、質が高い画像になる

Reference
Future Work
今回「brushstroke styletransfer を video に適用したい!」というモチベーションから始めたプロジェクトだったため、iterative optimization ベースでの実装となりました。
ある程度良い結果が出たかなと思っておりますが、やはり使い勝手の良さを考えると feed forward model には敵いません...。
今後は、今回の知見を活かして temporal consistency を保てるような feed forward model を開発していきたいです!
Discussion