✨
【論文メモ】Privacy-Preserving Portrait Matting
Human Matting について何か良い手法が最近出ていないかとこちらのリポジトリにあるソースコードをみていたところ、性能や使いやすさの観点から良さそうなものを見つけたのでそれについてのメモです。
github : https://github.com/JizhiziLi/P3M
paper : https://arxiv.org/pdf/2104.14222.pdf
まとめると
- 匿名化された巨大なデータセット : Privacy-Preseving Portrait Matting (P3M-10k) を提案した
- 機械学習において個人が特定できる情報の扱いについては関心が高まっているのにも関わらず、いままでそれを考慮してこないデータセットで各手法は発展してきた
- 高品質なアノテーションでかつ枚数も10000以上ある、匿名化をした初めてのデータセット
- P3M-10k を使った PPT-setting (train では顔にブラーをかけた画像で学習し、test は任意画像で行う) で既存手法を再評価し、顔にブラーがかかった状態での学習の影響を調査した
- P3M-10k を使い学習した trimap-free な手法 P3M-Net を提案した
提案されている P3M-Net で pexels の動画を推論してみました。提案モデルは動画用モデルではないのにも関わらず、かなり良い精度で推論ができています。
YouTubeのvideoIDが不正です
論文の概要
※以下、図は論文より引用
Background
- プライバシー保護の観点からは匿名化されたデータセットでの学習が求められるが、従来手法ではそのような配慮はされていない
- そのようなデータセットが存在しない
- 匿名化されたデータセットでの学習でよい性能が出るのか、についても活発に研究されていない
P3M-10k Dataset and impact on model
PPT Setting :
- privacy-preserving training
- 顔にブラーをかけるなどして、プライバシー保護がされたデータセットで train し、任意画像で test する設定
- train / test での domain gap が想定されるので、この状況下で学習するとどのような影響が出るかを知りたい
P3M-10k Dataset
- PPT Setting での評価を行うために、巨大なデータセットを構築した
- 10000 のライセンスフリーなデータを丁寧にアノテーション
- 従来のデータセットと一線を画している
- データセットの量、前景背景の多様さ、プライバシー保護
- 合成画像ではない
- 合成画像はモデルの汎化性能に影響を与える
How to generate blurred image

- landmark detector で顔の位置を取得し、blur をかける
- 頬とまゆげに沿って pixel-level mask を生成
- transition area を消去
- Gaussian blur をかける
- landmark がうまく検出できないケースでは手直し...
Imact of PPT
直感的にはモデルの性能が落ちることが見込まれる
- trimap based
- traditional methods
- 影響が無視できる程度
- transition area には blur がかかっていないので reasonable な結果
- deep learning methods
- 影響は少なめ、モデルは trimap を追加の入力として使い、transition region の推論に注力するため
- むしろ、blurred image で学習するほうが結果が良いケースがあった
- 汎化性能が上がったためと想定される
- traditional methods
- trimap-free methods
- 影響がかなり大きい
- domain gap があるため、reasonable ではある
- モデルによって影響度合いが異なる
- multi-task framework を採用している手法のほうが影響が小さい
- multistage のモデルでは性能劣化がみられたので、multi-task framework が domain gap を軽減してくれそう
- 検証によりこの仮説は実証されている
- train が blurred なら、test は normal / blurred は似たような性能だが、train が normal のとき test を blurred にすると性能が著しく落ちる
- 影響がかなり大きい
P3MNet
Architecture
- encoder * 1 + decoder * 2 の構成
- decoder はそれぞれ、segmentation, matting の task を解く
- multi-task learning にすることで性能が良くなる
- 既存の多くの手法が活用してきたように、decoder 内で encoder の特徴量を活用し性能を向上させるが、2つの decoder の間でもさらに特徴量を活用する
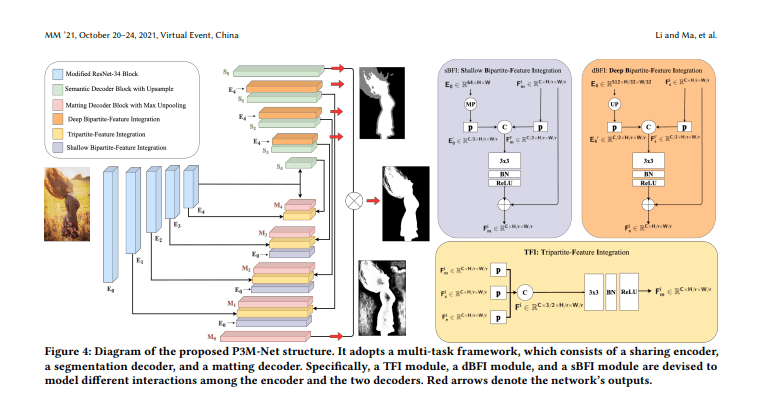
encoder
- ResNet-34 をベースに、max pooling を組み込んだものを使用する
- unpooling 時に活用するために、max pooling する際の最大値の位置を indices として保持しておく
- matting decoder で 詳細位置を復元するのに活用できる
decoder
- matting
- TFI : Tripartite-Feature Integration
- 同解像度の matting + segmentation + encoder を 1x1 conv で projection して concatenate → 3x3 conv → BN → ReLU
- encoder と2つの decoder の相互作用が狙い
- sBFI : Shallow Bipartite-Feature Integration
- encoder の最も浅い feature map + TFI を 1x1 conv で projection して concatenate → 3x3 conv → BN → ReLU したのち、residual に TFI と足し合わせる
- encoder の浅い層では、詳細な構造情報が含まれているので、matting にこれを活用するのが狙い
- TFI : Tripartite-Feature Integration
- segmentation
- dBFI : Deep Bipartite-Feature Integration
- encoder の最も深い feature map + segmentation を 1x1 conv で projection して concatenate → 3x3 conv → BN → ReLU したのち、residual に segmentation と足し合わせる
- encoder の深い層では、global semantics を encode しているので、segmentation にこれを活用するのが狙い
- dBFI : Deep Bipartite-Feature Integration
Loss Function
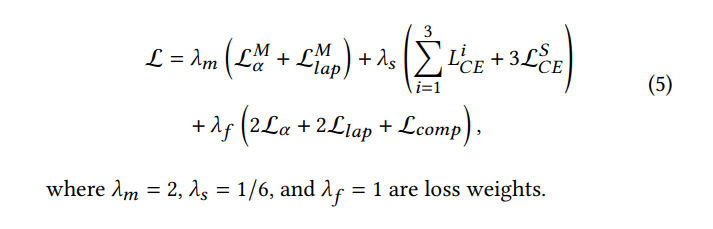
- segmentation (λ_s)
- corssentropy loss
- ground truth は trimap
- 学習の過程を安定化かつ向上させるために、segmentation の各出力(dBFI blocks の output である feature map) を用いる
- 3x3 conv と upsample を用いて、入力解像度にそろえる
- matting (λ_m)
- alpha loss + Laplacian loss
- segmentation decoder と matting decoder の出力をかけあわせたものを最終出力とする
- final output (λ_f)
- alpha loss + Laplacian loss + composition loss
loss についての補足
- alpha loss :
-
Bridging Composite and Real: Towards End-to-end Deep
Image Matting に記載あり - trimap の unknown region について、grond truth との absolute difference
-
Bridging Composite and Real: Towards End-to-end Deep
- Laplacian loss
-
Bridging Composite and Real: Towards End-to-end Deep
Image Matting に記載あり - alpha の laplacian pyramid を計算し、それの l1 loss
-
Bridging Composite and Real: Towards End-to-end Deep
- compisition loss
- Deep Image Matting に記載あり
- alpha matte を input RGB にかけることで得られた foreground RGB 同士の sqrt
Training
- data augmentation (reference)
- 512x512, 768x768, 1024x1024 のいずれかの size の組み合わせからランダムに選んだもので patch を画像から切り出して、それを 512x512 に resize
- random flip
- settings
- learing rate : 1e-5
- 論文に記載はないが、実装によると optimizer は adam
- batchsize : 8
- epoch : 150
- machine : NVIDIA Tesla V100 GPU
- learing rate : 1e-5
感想
- Human Matting のデータで、ここまで高品質でありながらデータセットライセンスが使いやすいものを公開したのがとても偉大
- Background Matting v2 も使いやすいライセンスで高品質なデータセットを公開しているが、あちらは foreground & alpha のみなので、例えば background 画像から合成したものを活用して学習に使用すると semantics が崩れやすくなってしまう...
- 提案されているモデルも非常に強力で魅力的だが、それがアーキテクチャによるものなのか、データセットによるものなのかは議論の余地がありそう
- 例えば論文内では比較されていなかったが、MODNet などを同条件で学習させた際にどれくらいの差異がでるのかが気になる
- 今回の論文を下地にした Rethinking Portrait Matting with Privacy Preserving では MODNet との比較もされている
- 例えば論文内では比較されていなかったが、MODNet などを同条件で学習させた際にどれくらいの差異がでるのかが気になる
- official repository の著者さんは、今回の研究だけでなくたくさんの matting 関連のソースコードをアップしており本当にすごい
今回の論文および公開されたデータセットをベースにこれから発展していきそうで楽しみです。
Discussion
Rethinking Portrait Matting with Privacy Preserving との差分メモ
github : https://github.com/ViTAE-Transformer/ViTAE-Transformer-Matting