データベース

RDS (Relational Database Service)
RDSは、マネージドリレーショナルデータベースサービスの一つで、元々データベースの管理が大変だった問題を解決します。以下はRDSのメリットと機能の要点です:
メリット:
-
エンジンの選択:
RDSではさまざまなデータベースエンジンを選択できます。一般的な選択肢にはMySQL、PostgreSQL、Oracle、SQL Serverなどがあります。また、AuroraというAWS独自のエンジンも利用可能で、高性能や耐久性に優れています。 -
エンドポイント通信:
RDSはエンドポイント通信を提供し、名前解決を通じて通信できます。これは障害発生時に便利であり、エンドポイントは冗長化構成を簡単に構築できます。 -
負荷分散:
リードレプリカを使用して、読み取りと書き込み用の負荷を分散できます。これによりパフォーマンスが向上し、スケーリングが容易になります。 -
自動スナップショット:
RDSは自動的にスナップショットを取得し、データのバックアップを提供します。これはデータの保護と復元に役立ちます。 -
自動パッチ適用:
RDSは自動的にセキュリティパッチを適用し、データベースを保護します。 -
GUIベースのパラメーター設定:
RDSはGUIを提供し、パラメーター設定を簡単に行えます。
M-S (メイン-スタンバイ) 構成
RDSでは、メイン-スタンバイ構成を簡単に設定でき、AWSがレプリケーションを管理します。エンドポイント通信は名前解決に基づいており、冗長化構成を容易に構築できます。
※ IPアドレスとエンドポイントが紐づいているがAWSが裏で調整している

リードレプリカ
RDSでは、リードレプリカ(Read Replica)を使用してデータベースの負荷を管理し、読み取りおよび書き込みの処理を役割ごとに分けることができます。以下はリードレプリカの主な特徴とメリットです:
負荷分散
リードレプリカは主要なデータベース(マスターデータベース)からデータを複製することで、読み取り負荷を分散します。これにより、アプリケーションが高負荷の読み取り操作を行う際に、性能が向上します。
耐障害性
リードレプリカはマスターデータベースのデータを非同期的に複製するため、障害時にマスターから切り離されて独立して動作できます。これは高可用性と耐障害性を提供します。
データの一貫性
リードレプリカはマスターデータベースのデータを複製するため、リードレプリカ上での読み取り操作は一貫性が保たれます。ただし、リードレプリカはマスターデータベースと同期が取れない場合があるため、最新のデータを保証するわけではありません。
読み取りスケーリング
リードレプリカを使用することで、読み取り負荷を追加のリソースを割り当てることなしにスケーリングできます。これにより、高トラフィックのアプリケーションにおいても高パフォーマンスを維持できます。

https://dev.classmethod.jp/articles/cm-advent-calendar-2015-aws-re-entering-rds/
スナップショット
RDSでは、データベースのスナップショットを定期的に取得したり、手動で作成したりできます。スナップショットはデータベースのバックアップを作成し、以下のような用途に使用されます:
データのバックアップ
スナップショットはデータベースの状態を特定の時点で保存し、データの復元や回復に使用できます。データの損失を防ぐために重要です。
複製の作成
スナップショットを使用して新しいデータベースインスタンスを作成できます。これにより、テスト環境や開発環境の構築が簡略化されます。
パッチ適用
RDSでは、データベースエンジンのセキュリティパッチ適用を管理するためのメンテナンスウィンドウを設定できます。以下はパッチ適用に関する詳細です:
メンテナンスウィンドウ
メンテナンスウィンドウは、データベースエンジンのセキュリティパッチやアップデートを適用するための時間帯です。通常、アプリケーションの負荷が低い時間帯に設定されます。
自動パッチ適用
RDSは自動的にセキュリティパッチを適用する設定を提供しており、これによりデータベースのセキュリティが維持されます。
SSHアクセス
RDSへの直接SSHアクセスはサポートされていません。代わりに、RDSインスタンスへのアクセスは通常、データベースエンジンに関連するクライアントツールやAPIを介して行われます。セキュリティを確保するため、RDSへのアクセスは制御された方法で行われます。
Aurora
Auroraは、Amazon RDSの一部であり、高性能なリレーショナルデータベースサービスです。
複数のエンジン:
AuroraはMySQLとPostgreSQLという人気のあるデータベースエンジンに対応しています。MySQLの場合、最大でMySQLの5倍、PostgreSQLの場合、3倍のパフォーマンスを提供します。
プライマリとレプリカ:
Auroraはプライマリデータベースと複数の読み取り専用のレプリカをサポートしています。これにより、読み取り処理を分散させ、高いパフォーマンスを実珸できます。
クラスターボリューム:
Auroraはデータを10GB単位で3つの異なるアベイラビリティーゾーン(AZ)にコピーするクラスターボリュームを使用します。これにより、データは高可用性を持ちながら連続的にS3にバックアップされます。
オートスケーリング:
Auroraのレプリカは自動スケーリングが可能で、必要に応じてレプリカの数が増減します。障害が発生した場合、レプリカがプライマリに昇格することで高可用性が確保されます。
エンドポイント
クラスターエンドポイント: プライマリデータベースへの接続に使用されます。
リーダーエンドポイント: 読み取り専用のDNSエンドポイントで、読み取りトラフィックを分散させます。PostgreSQLの場合、最大15個まで作成できます。
カスタムエンドポイント: 選択したAuroraレプリカ間でリクエストを分散するためのカスタムエンドポイントを作成できます。

https://docs.aws.amazon.com/ja_jp/AmazonRDS/latest/AuroraUserGuide/Aurora.Overview.html
リージョン間のレプリケーション
Auroraは物理レプリケーションと論理レプリケーションの2つのオプションを提供し、他のリージョンにレプリカを作成して高可用性と耐障害性を向上させることができます。
物理レプリケーション(グローバルデータベース)
非同期レプリケーション:
Auroraの物理レプリケーションは非同期で行われます。これは、プライマリデータベースからレプリカデータベースにデータのコピーが即座に行われないことを意味します。そのため、レプリケーションは即座に完了せず、遅延が発生する可能性があります。
パフォーマンスへの影響が少ない:
物理レプリケーションはパフォーマンスにほとんど影響を与えません。データのコピーは非同期でバックグラウンドで行われ、通常のデータベース操作に影響を与えません。
障害時の自動フェールオーバ:
物理レプリケーションにより、プライマリデータベースに障害が発生した場合、自動的にレプリカがプライマリに昇格することができます。これにより、高可用性が確保され、サービスの中断を最小限に抑えることができます。
論理レプリケーション(クロスリージョンレプリケーション)
個々のエンジンのネイティブな設定を利用: 論理レプリケーションでは、異なるエンジン(例: MySQLとPostgreSQL)間でデータをレプリケートするために、各エンジンのネイティブな設定を利用します。

https://dev.classmethod.jp/articles/amazon-aurora-global-database-failover-between-region/
マルチマスター(MySQLのみ)
Aurora MySQLでは、複数のプライマリデータベースを設定できます。これにより、読み取りと書き込みを異なるデータベースインスタンスで実行できます。
障害時の昇格までに時間がかかる
マルチマスター構成では、障害が発生したプライマリデータベースから別のデータベースがプライマリに昇格するまで、時間がかかることがあります。これは、データの整合性を確保するために必要な手順が複雑であるためです。
全てプライマリとしておくことができる
マルチマスター構成では、すべてのデータベースインスタンスがプライマリとして機能できます。これにより、読み取りと書き込みを異なるデータベースインスタンスで実行できます。このアクティブ/アクティブ構成は、高いスケーラビリティを提供します。
アクティブ/アクティブ
マルチマスター構成では、すべてのデータベースインスタンスが同時に読み取りと書き込みを処理できます。これにより、負荷の分散と高いスループットが実現できます。アプリケーションが同時に大量のリクエストを処理する必要がある場合に適しています。
アクティブ/パッシブ
マルチマスター構成では、1つのデータベースインスタンスがアクティブで、他のインスタンスはパッシブで待機します。アクティブ/パッシブ構成は、特定の読み取りおよび書き込み要求を特定のデータベースに制御的にルーティングする必要がある場合に適しています。
Aurora Serverless
Aurora Serverlessはサーバーレスアーキテクチャを採用し、ACU(Aurora Capacity Unit)とACUクラスターボリュームを使用して費用効率の高いオートスケーリングを実現します。
ACUクラスターボリューム:
Aurora Serverlessは、データベースのストレージ容量をACUクラスターボリュームを通じて提供します。このクラスターボリュームは、データの保存と通信に使用され、データベースの容量に応じて自動的にスケーリングされます。
ACU (Aurora Capacity Unit):
Aurora Serverlessは、ACUという単位を使用して処理能力を計測します。ACUは、データベースのリソース使用量を示し、読み取り/書き込みキャパシティに対応します。アプリケーションの負荷に合わせてACUが動的に割り当てられ、必要に応じてスケーリングされます。
※ 1ACU=2メモリ
Proxy Fleet
AuroraへのアクセスはProxy Fleetを介して行われ、データベースのアクセスが管理されます。

https://aws.amazon.com/jp/blogs/news/in-the-works-amazon-aurora-serverless/
DynamoDB
DynamoDBはNoSQLデータベースサービスで、高速な処理、柔軟なデータ格納形式、オブジェクト指向のAPIを提供します。以下はDynamoDBの特徴とメリットの要点です:
メリット:
-
サーバー管理不要:
DynamoDBはマネージドサービスであり、データベースの管理に関する負担が軽減されます。 -
高速な処理:
DynamoDBは高速な読み取りおよび書き込み処理を提供し、スケーラビリティが高いです。 -
ストレージ無制限:
ストレージ容量に制限がなく、データを無制限に格納できます。 -
キーバリュー型:
データはキーと値のペアとして格納され、JSON形式をサポートします。SQL互換のクエリも提供されています。
ユースケース
ユーザーセッションの利用
DynamoDBは、ユーザーセッション管理にも適しています。セッションデータを保存し、ユーザーがウェブアプリケーションなどにログインしている間、そのセッション情報を安全に保持できます。

https://dev.classmethod.jp/articles/amazon-dynamodb-tomcat-session-management/
キーバリュー型
DynamoDBは、キーバリュー型のNoSQLデータベースであり、以下の特徴があります:
KeyとValueでペアで保存される
データはキー(プライマリーキーまたはソートキー)と値(データ)のペアとして格納されます。キーはデータを一意に識別し、値は実際のデータを表します。
JSON形式がある
値はJSON形式で格納できます。JSONは柔軟なデータ構造をサポートし、多様なデータタイプを表現できます。
APIを利用してデータを取得、保存する
DynamoDBにはAPIが提供されており、アプリケーションからデータの読み取りと書き込みが行えます。APIを使用することで、アプリケーションはDynamoDBと連携し、データベースへのアクセスが可能となります。
料金
データの転送料
異なるAWSリージョン間でのデータ転送にかかる料金が発生します。データの送受信において、リージョン間のトラフィックが含まれます。
データの保管料
DynamoDBはデータの保管容量に対して課金されます。データベース内に格納されているデータの量に応じて料金が発生します。
キャパシティモード:
DynamoDBでは、読み取りおよび書き込み容量を管理するキャパシティモードがあります。
性能単位を「ユニット」と呼びます。
- 読み取りユニットをRCU (最大4KBを2回読み込む/秒)
- 書き込みユニットをWCU (最大1KBを1回書き込む/秒)
オンデマンドキャパシティモード:
キャパシティが予測できない場合に使用され、クラウドライクな柔軟性を提供します。
プロビジョニングキャパシティモード:
キャパシティが予測可能な場合に使用され、事前にキャパシティを設定する必要があります。キャパシティを超えると500エラーが発生するため、注意が必要です。
テーブルクラス:
DynamoDBは2つのテーブルクラスを提供します。
- **Standard: **標準テーブルクラスで、一般的なデータの格納に使用されます。
- **IAテーブルクラス: **低頻度のアクセスに適したアーカイブタイプのテーブルクラスです。
キーとインデックス:
DynamoDBのデータモデルには以下の要素があります。
プライマリーキー(パーティションキー):
パーティションキーはデータをパーティションごとに分割し、パーティション内で一意のIDを提供します。これにより効率的なデータ検索が可能です。
ソートキー:
ソートキーはパーティション内でデータを更に細かくソートするためのキーで、補助キーとして機能します。

インデックス:
DynamoDBはセカンダリインデックスを提供し、さらにデータを絞るための検索条件を提供します。ローカルセカンダリインデックス(LSI)とグローバルセカンダリインデックス(GSI)の2つのタイプがあります。
復号プライマリーキー:
ソートキーと主キーを組み合わせて、復号プライマリーキーを形成します。これにより、より細かい検索が可能になります。復号プライマリーキーを使用して、特定の条件に合致するデータを検索できます。
インデックス(索引、目次)
⇨ DynamoDBではよりデータを絞るためのこと
⇨ 復号プライマリーキーではまだ検索するには足りない場合、それ以外の検索条件(キー)第2のキーとして「セカンダリインデックス」がある
ローカルセカンダリインデックす(LSI)
同一パーティション内で追加でインデックス
テーブル作成時にしか作成できないので設計段階で考慮が必要
ソートキーの無いテーブルには利用できない
グローバルセカンダリインデックス(GSI)
テーブル作成後でも追加や削除が可能なセカンダリインデックスのこと
デフォルトで20コまで利用できる
グローバルテーブル
複数リージョンにまたがるようにDynamoDBのデータを保存する仕組みのこと
デフォルトの使い方では、複数AZに保存される仕組みになっている
展開=複製のこと 変更内容を共有すること
整合性
デフォルトの設定では、複数AZにデータが保存される仕組みになっている
ただし、必ずしも全てのAZに置かれているデータの整合性があっているとは限らない。
DynamoDBでは、整合性の問題に対処するために以下の2つのオプションがあります。
結果整合性
デフォルトの設定で、データはすぐに更新されないことがあるため、古いデータが含まれることがあります。再度データを読み込むと、最終的に整合性が取れる状態になります。
強力な結果整合性
データをすぐに反映することができ、常に最新のデータを提供します。ただし、これによりレイテンシーが増加し、ネットワークの状況に依存することがあります。高いユニット数が必要で、プロビジョニングモードでは適切なキャパシティを確保する必要があります。
※ グローバルセカンダリインデックス(GSI)では利用することができない
DynamoDBセキュリティ管理
セキュリティ管理に関して、DynamoDBでは以下の要素が重要です。
アクセス制御
アクセスはAWS Identity and Access Management (IAM) ポリシーによって制御されます。IAMを使用して、ユーザーやアプリケーションがDynamoDBへのアクセスを管理できます。アクセスログはAWS CloudTrailとCloudWatch Logsで監査とログ管理が行われます。
暗号化
DynamoDBはAES256暗号化を使用し、データを保護します。暗号化キーはAWS Key Management Service (KMS)を使用できます。
通信経路
DynamoDBはHTTPS通信を使用してデータの送受信を暗号化します。ただし、DynamoDB Accelerator (DAX)はHTTPS通信を除外しています。
DynamoDB Accelerator(DAX)
DynamoDB Accelerator (DAX) は、DynamoDBのパフォーマンスを向上させるためのインメモリキャッシュサービスです。
AZに配置
DAXクラスターは複数のアベイラビリティーゾーン(AZ)に配置され、高可用性を提供します。データベースへのアクセスが障害の影響を受けにくくなります。
高速なパフォーマンス
DAXはミリ秒またはマイクロ秒単位のレスポンスタイムを提供し、DynamoDBからデータを高速に読み込むことができます。これにより、アプリケーションのパフォーマンスが向上します。
読み込みと書き込みのキャッシュ
DAXは読み込み操作だけでなく、書き込み操作もキャッシュできます。これにより、データベースからの読み取りと書き込みの両方に対するパフォーマンスの向上が実珸ています。
API互換性
DAXはDynamoDB APIと互換性があり、アプリケーションのコードの変更は必要ありません。既存のアプリケーションはDAXを導入するだけで、高速化を実現できます。
DAXクラスターを作成する
DAXはDAXクラスターと呼ばれるリソースで構成されます。クラスターは複数のノード(インスタンス)から構成され、高可用性を提供します。各ノードは同じインスタンスタイプを持ち、ユーザーはクラスターのインスタンスタイプを指定する必要があります。

https://qiita.com/miyuki_samitani/items/ef2e3ce224162c37085e
プライマリとリードレプリカ
DAXクラスターは通常、プライマリノードと複数のリードレプリカノードから構成されます。障害が発生した場合、リードレプリカノードがプライマリに昇格できるため、高可用性が確保されます。
DAXの配置
DAXはDynamoDBとアプリケーションの間に配置されます。アプリケーションはDAXに対してクエリを送信し、DAXはキャッシュされたデータを提供します。DAXはDynamoDBへのアクセスを透過的に高速化します。
IAMロールの付与
DAXを使用する際、DynamoDBとEC2インスタンスに対して適切なIAMロールを付与する必要があります。これにより、DAXがDynamoDBにアクセスするための権限を持つことができます。
ElastiCacheとの比較
DAXはDynamoDBに特化しており、DynamoDBのパフォーマンス向上を目的としています。ElastiCacheは一般的なキャッシュサービスで、より多くのデータストアをサポートしています。アプリケーションがDynamoDBを利用している場合、DAXが適していますが、他のデータストアに対してはElastiCacheが選択肢として考えられます。
ElastiCache
ElastiCacheはインメモリ型のデータベースで、主にキーバリューストアとして使用されます。AWSが提供するElastiCacheは、RedisとMemcachedという二つのオープンソースデータベースエンジンに対応しています。
キャッシュの役割
キャッシュは、データベースに対する読み込みと書き込みの負荷を軽減するために利用されます。データをElastiCacheに一度保存することで、RDS(Relational Database Service)などのデータベースが読み取りリクエストに応じる際、高速にデータを提供できます。これにより、データベースは書き込みに専念できるようになります。

キャッシュ戦略
キャッシュの有効期限(TTL)を設定
データをElastiCacheに保存する際に、TTL(Time To Live)を設定します。TTLが有効な期間内では、ElastiCacheがデータの読み取りを担当します。これにより、データの過度なストレージ占有を防ぎつつ、高速な読み取りを実現できます。
Lazy Loading(Redisの場合)
Lazy Loading戦略では、まずElastiCacheにデータが存在するかどうかを確認します。データがない場合、RDSからデータを取得してElastiCacheに保存します。この戦略により、必要なデータだけがキャッシュに保存され、キャッシュの効率が向上します。

https://dev.to/kelvinskell/an-overview-of-elasticache-caching-strategies-3h3d
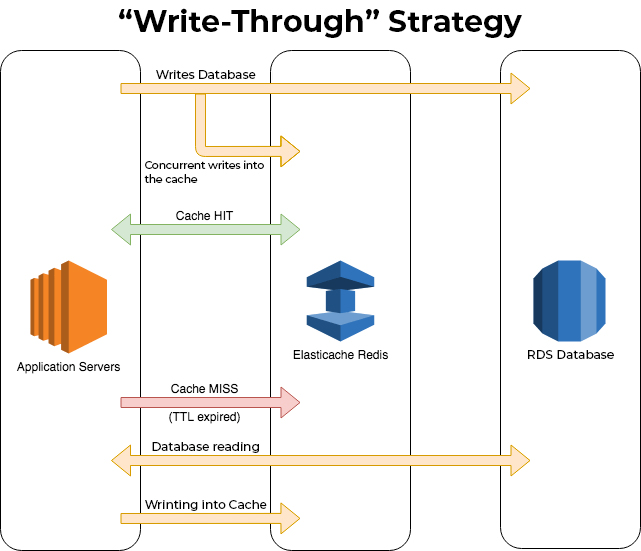
Write-Through(Redisの場合)
Write-Through戦略では、書き込み操作が行われたとき、データを同時にRDSとElastiCacheの両方に書き込みます。読み取りリクエストがElastiCacheにあれば、データを読み取り専用で返すことができます。この戦略はウェブサーバーの負荷を軽減し、高速な読み取りを実現できます。ただし、キャッシュサイズが小さい場合には効果が限定されることに留意する必要があります。
RedisとMemcached
Redis:
Redisはシングルスレッドモデルを採用していますが、複雑な操作や多くのデータタイプ(ハッシュ、リストなど)をサポートし、データの整理やソート、Pub/Sub(Publish/Subscribe)など多彩な機能を提供します。永続性を持ち、データがメモリに保存されるため再起動してもデータは失われません。
Memcached:
Memcachedはマルチスレッドモデルを採用しており、シンプルなキャッシュ機能に特化しています。一方で、Redisほど多彩なデータ操作や永続性を提供しません。
デプロイモデル
シングルノード:
単一のノードで構成され、スケールアップが垂直方向のみで可能です。
シャードなし(単一シャード):
クラスター内に1つのプライマリと複数のレプリカが含まれます。シャードの概念は適用されず、単一のデータセットを操作します。
クラスターモード有効:
複数のシャードを設定し、クラスター全体でデータの読み書きを行うことができます。これにより、水平スケーリングが実現され、高い性能を得ることができます。

https://aws.amazon.com/jp/blogs/news/work-with-cluster-mode-on-amazon-elasticache-for-redis/
Discussion