Electron+React+Google TextToSpeechで英語のシャドーイングを好きなだけ繰り返すアプリケーションを作ってみた




英語の上達、とくにスピーキングやリスニングにはシャドーイングという学習方法が有効だと聞いたことがあります。シャドーイングやパラレル・リーディングなどの学習方法をサポートするためのアプリケーションを開発しました。https://github.com/kubotama/splish-craで公開しています。
wikipedia のシャドーイングの項目によれば、学習する人のレベルにあわせた教材として、シャドーイングには音声、パラレル・リーディングには音声とテキストが必要です。
現実には、自分の興味のある分野で、自分のレベルにあった教材を入手することは、なかなか簡単ではありません。一方で英語のテキストは、インターネットに無数にあります。自分の興味のあるテキストから音声を合成できれば、教材を用意できることになります。
また、テキストと音声があれば十分というでもありません。一度聞いただけでは聞き取れない場合、聞き取ることができるようになるまで繰り返します。簡単に繰り返し聞けることが大事です。
そこで、Google の Text-to-Speech: 自然な音声合成を利用して、インターネット上に後悔されているテキストから音声を合成するアプリケーションを開発しました。Google の Text-to-Speech は、1 ヶ月に 100 万文字、あるいは 400 万文字までの無料枠があります。個人の学習目的であれば、かなりの文字数だと思います。また無料枠を越しても、標準音声であれば 100 万文字ごとに$4 です。詳しくは料金表で確認して下さい。
なお Text-to-Speech の英語の発音がどの程度まで正確なのかは私には判断できません。デモで日本語の発音を確認したところ、違和感がないわけではありませんが、目をつぶることにしました。
機能
以下の機能があります。
- 入力したテキストから音声を合成します。合成した音声はローカル環境に mp3 形式のファイルとして保存します。
- 合成した音声を再生します。再生するときにテキストの表示、非表示を切り替えられます。
テキストを表示した場合にはパラレル・リーディング、テキストを表示しない場合にはシャドーイングを想定しています。最初はテキストを表示しながら再生を聞いて、ある程度慣れたところでテキストを表示しないで再生を聞く、という使い方を想定しています。
アプリケーション開発
Electron ベースで開発しています。開発及び検証している環境は、Linux(Ubuntu 20.04)です。開発にあたってはCreate React App(typescript)をベースに electron 環境を構築するを参考にしました。
Electron のプロセス間通信
Electron はマルチプロセスアーキテクチャを採用していて、メインプロセスとレンダラープロセスで構成されます。メインプロセスではネイティブ API の利用、レンダラープロセスでは UI の提供を担当します。Electron ベースでアプリケーションを構築するためには、それぞれのプロセス間で通信するためのプロセス間通信が必要となります。以下のプロセス間通信を利用しています。
テキストから音声を合成
レンダラープロセスで入力したテキストを、メインプロセスで音声に合成して、カレントディレクトリのファイルに保存します。保存するファイル名は合成した日時をベース(yyyyMMddHHmmssSSS.mp3)とします。この処理に関係するプロセス間通信は textToSynthesize が担当します。string 型の引数は、音声を合成するテキストです。戻り値は音声を合成した日時、テキスト、保存したファイル名の配列です。
これまでに合成した音声に関するデータを保存するファイルの形式
テキストを音声に合成するタイミングで、カレントディレクトリの splish.json にこれまでに合成した音声に関するデータを保存します。保存するデータは以下の通りです。
- 音声を合成した日時。
- 音声を合成したテキスト。全文と一覧表で表示するための先頭 140 文字を保存します。
- 音声を合成したテキストの文字数。
- 合成した音声を保存するファイル名
export type SynthesizedRow = {
id: string;
synthesizedTime: string; // 音声を合成した日時。
synthesizedText: string; // 音声を合成したテキストの全文
synthesizedTruncatedText: string; // 音声を合成したテキストの先頭140文字
textCount: number; //音声を合成したテキストの文字数
filename: string; //合成した音声を保存するファイル名
};
上記のオブジェクトの配列を json 形式でファイルに保存します。
音声合成のオプション
音声を合成するときのオプションは、いまのところ以下のように設定しています。
| カテゴリ | オプション | 設定されている値 |
|---|---|---|
| voice | languageCode | en-US |
| voice | ssmlGender | NEUTRAL |
| voice | name | en-US-Standard-J |
| audioConfig | audioEncoding | MP3 |
| audioConfig | effectsProfileId | headphone-class-device |
オプションについては
TextToSpeech - Documentationがドキュメントのはずですが、具体的にどのような値を設定すればいいのか、があまり詳しく書かれていません。
audioConfig カテゴリは、Package google.cloud.texttospeech.v1 | Cloud Text-to-Speech Documentation | Google Cloudが参考になります。
Text-to-Speech: Lifelike Speech Synthesisのデモで、show JSON をクリックすると REST API に送信するデータを確認できます。こちらも参考になります。
合成した音声を再生
レンダラープロセスが指定したファイル名に保存されている音声をメインプロセスが読み込んで、レンダラープロセスに戻します。レンダラープロセスは、戻された音声を再生します。この処理に関係するプロセス間通信は、readAudioFile です。string 型の引数は、合成した音声を保存したファイル名です。戻り値は Buffer 型で、音声データです。レンダラープロセスは戻された音声データを再生します。
それまでに合成した音声データの読み込み
splish はそれまでに合成した音声のテキストと音声を保存したファイル名を、ファイル(splish.json)に保存します。splish の起動時に、メインプロセスで音声を合成した日時とテキスト、保存したファイル名を読み込んで、レンダラープロセスに戻します。
使い方
splish を利用するためには、
- Google API を利用するための設定
- アプリケーションのビルド
が必要です。以下の説明は linux 環境を前提としています。
Google API を利用するための準備
1. プロジェクトを作成します
Google Cloud のコンソールでプロジェクトを作成します。
2. Text-to-Speech の API を有効にします
作成したプロジェクトで Text-to-Speech の API を有効にします。
3. サービスアカウントとして認証します
サービス アカウントとして認証する | Google Cloudに書かれている手順に従って、サービスアカウントとサービスアカウントキーを作成します。
4. 環境変数を設定します
サービスアカウントキーをダウンロードしたファイルを環境変数(GOOGLE_APPLICATION_CREDENTIALS)に設定します。
ビルドの手順
リポジトリをクローンしてビルドします
$ git clone git@github.com:kubotama/splish-cra.git
$ cd splish-cra
$ yarn electron:build:portable
dist/linux-unpacked/splish-cra がビルドされます。
操作方法
1. splish を起動します
$ dist/linux-unpacked/splish-cra
splish の画面が表示されます。
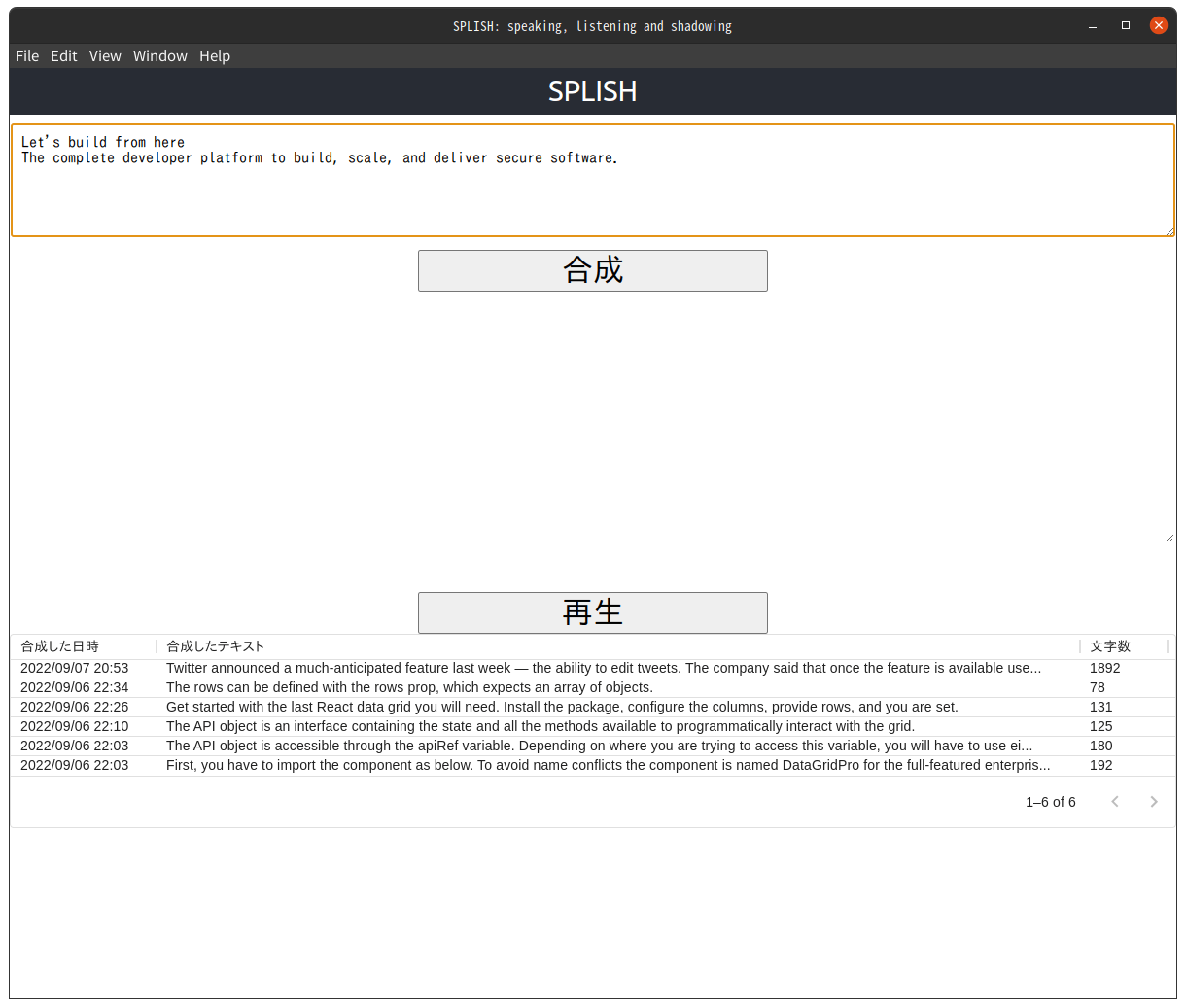
2. テキストの入力領域に音声を合成したいテキストを入力します
テキストの入力領域にテキストが入力されると、合成ボタンが有効になります。サンプルの英文には GitHub のAbout ページの先頭に書かれているテキストを利用しています。
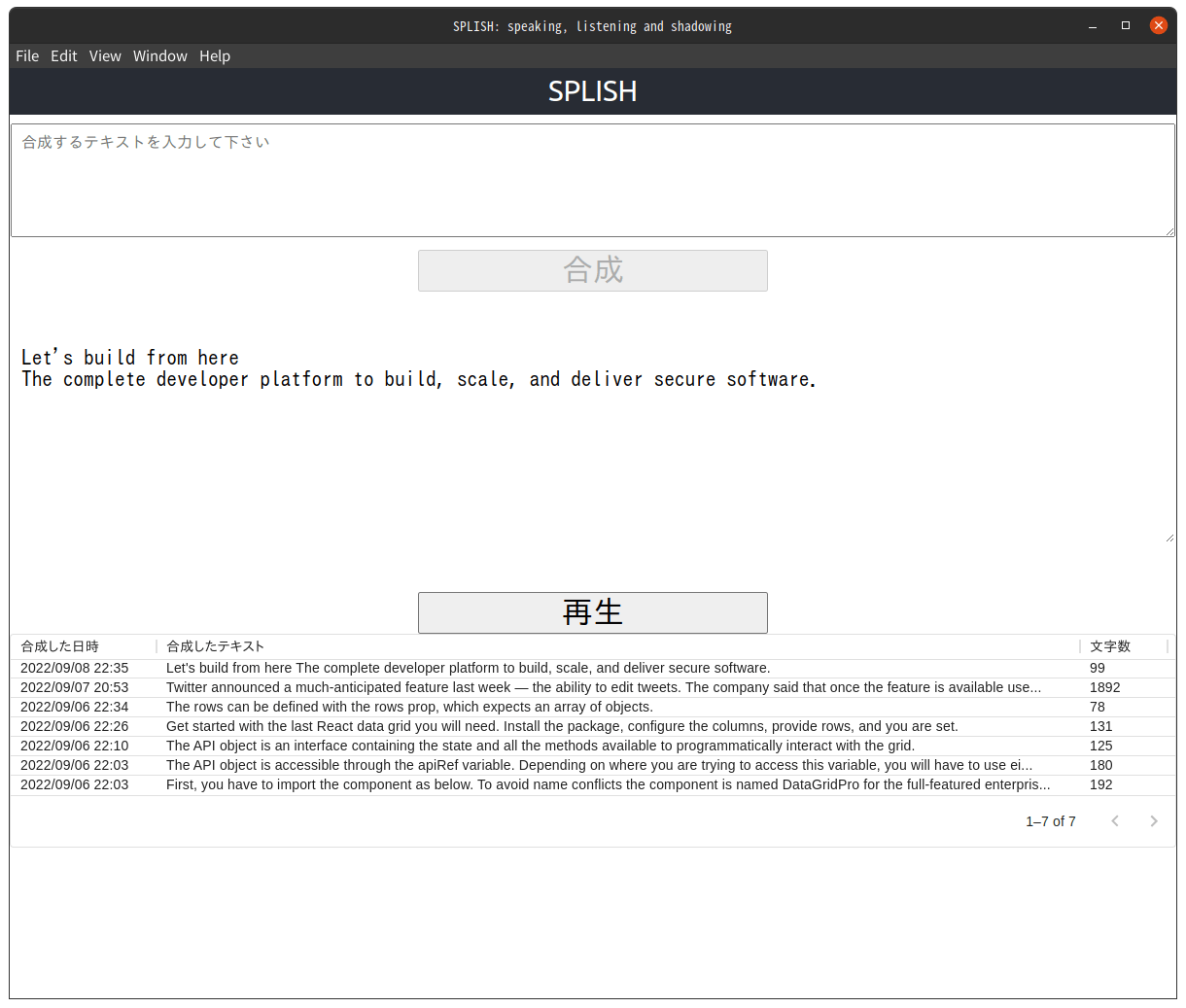
3. 合成ボタンをクリックして音声を合成します
合成ボタンをクリックすると音声を合成します。テキストの入力領域がクリアされて、代わりに「音声を再生するテキストを表示する領域」に表示されます。音声が合成されると再生ボタンが有効になります。テキストを合成した音声の一覧表の一番上の行に、いま合成したテキストが追加されています。
4. 合成した音声を再生する
再生ボタンをクリックすると「音声を再生するテキストを表示する領域」に表示されているテキストの音声を再生します。
5. 再生するテキストを選択する
テキストを合成した音声の一覧表をクリックすると、クリックしたテキストが、「音声を再生するテキストを表示する領域」に表示されます。

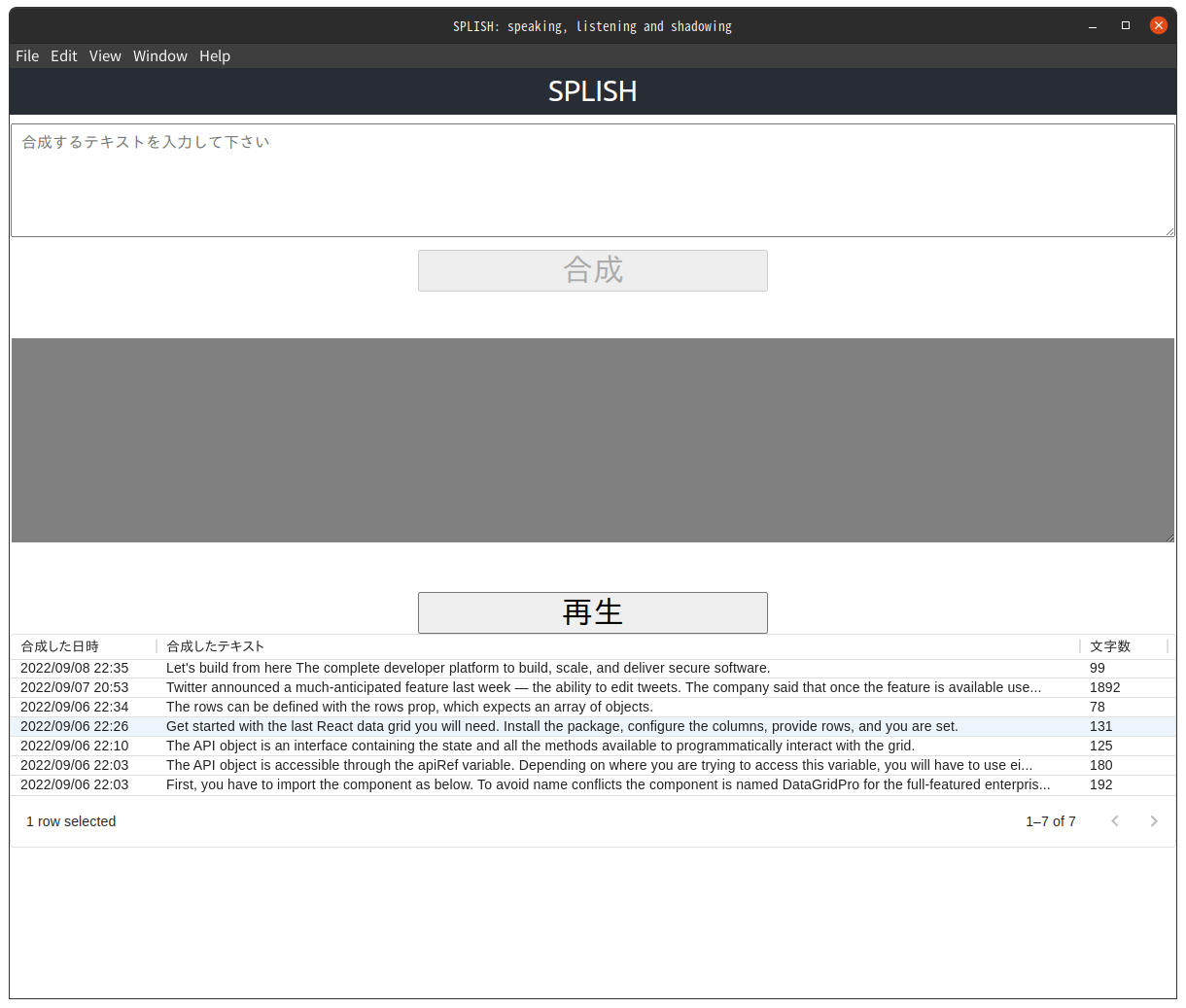
6. テキストを読めなくする
音声を合成したテキストを表示する領域をクリックすると、背景色が文字の色と同じになって、テキストが読めなくなります。もう一度クリックすると戻ります。
試した感想
音声は適度な長さが望ましいと思いました。かといって、適度な長さで分割して音声を合成するのは面倒なので、長い文章を文ごとに分割して音声に合成できると便利な気がしました。それと、再生が始まったら停止できないのは不便でした。あとは再生する速度を変えたいです。
ということで、今後の機能拡張の予定です。
- 音声を合成するときのオプションを設定する。
- 複数の文からなる文章を入力すると、文ごとに分割して音声を合成する。
- 音声の再生を停止するボタンを追加する。
- 音声を再生する速度を変更する。
よければ、ぜひ試してもらって、感想をコメントしてもらえると嬉しいです。
Discussion