🔍
【要約】LLMにおける知識注入の比較(RAG vs fine-turning)
はじめに
- OpenaiをはじめとするLLMを業務に適応する際にボトルネックとしてしばしば登場するLLMの知識に関する論文です。
- 執筆がMicroSoftであり、信ぴょう性も高いことから読みました。
- 翻訳+段落分け+要約してみたので気になる方は是非ご確認ください。
- なお、時間のない方はこちらの方の記事が参考になるかと思います。
- 誤訳、間違いなどがありましたらコメントしていただけると幸いです🙇♂️
~以下要約~
1. 【本研究テーマの現状】はじめに
LLMの知識獲得における限界
- 静的で時間と共に更新されない(知識の時系列関係を理解できない)
- 非特異的(知識同士の優劣がない?)
上記の問題点の解決策として考えられているもの
①fine-turning
- モデルの訓練プロセスを継続し、タスク固有のデータを使って適応すること
- モデルを特定の知識ベースにさらすことで、モデルの重みがそれに応じて適応することが期待できる
- ターゲットとするアプリケーションのためにモデルを最適化することを意図しており、専門的なドメインにおける性能と文脈状の関連性を向上させる
②コンテキスト内学習(ICL)
- モデルの重みを変更することなく、モデルへの入力クエリを変呼応することにより、新しいタスクで事前に訓練されたLLMのパフォーマンスを向上させることができる
- ICLの1つの形態としてRAG(検索拡張生成)がある。
- RAGは情報検索技術を利用して、LLMが情報源から 関連技術を取得し、生成されたテキストに組み込むことができる
※本研究の目的は、知識注入能力を評価すること。
2. 【本研究を行う上で知っていて欲しいこと】背景
- 知識注入とは何か評価するためには、LLMにとって知識とは何かを理解する必要がある
LLMにとっての知識を持っていることの定義(本研究上での定義)
- その知識についての質問に正確かつ一貫して回答できる
- その知識に関する真偽を確実に区別できる
- 上記の定義を単一の知識だけでなく、知識ベース全体に拡張できる
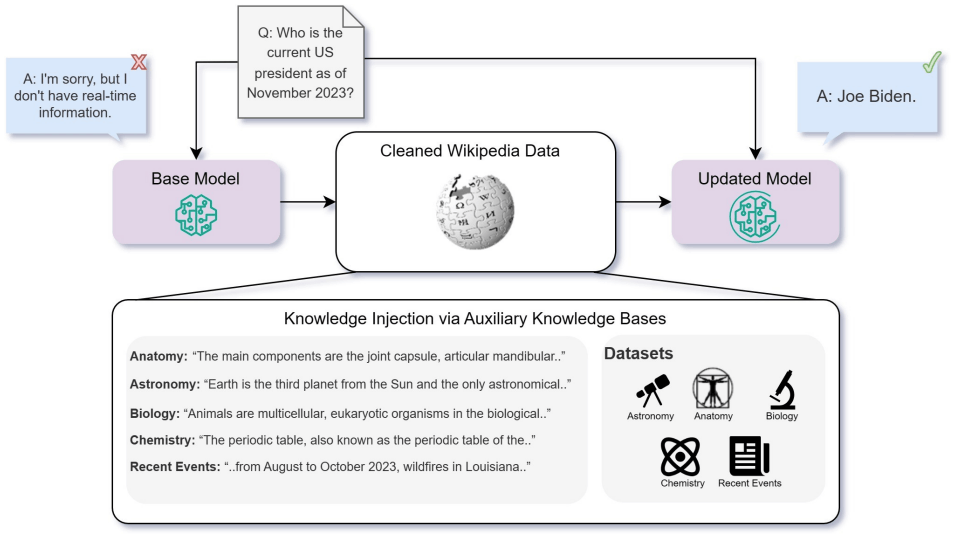
→本研究上での知識注入の目標はモデルに全く新しい知識を教えることではなく、特定のドメインへのバイアスを誘導することによって、モデルの記憶を「リフレッシュ(更新、塗り替え)」すること
LLMがハルシネーションを発生させる原因
- ドメイン知識の不足
- 特定ドメインの包括的な専門知識が欠けている場合発生することがある
- 学習した類似した知識の影響
- 事前学習中にモデルが以前接した事のある知識と、全く新しい知識の区別ができていない場合発生することがある
- 事前学習以後の知識についてのタスク
- モデルの事前学習以後の情報は間違いなくモデルが知識として持っていることはないので、回答ができない。
- 非記憶化
- モデルが学習過程で知識に触れていても、それを保持できないことがある。特に学習データにわずかしか登場しない知識の場合発生しやすい
- 忘却
- 追加学習によって、以前の知識を失うことがある。
- 推論の失敗
- 知識は持っているが、その知識を適切に利用出来ないこと。
- 特に複雑な多段階推論課題(Chain of Thought)や、同じ知識について異なる質問を投げかけられた場合に結果がバラバラになるなどが発生する。
3. 【比較するそれぞれの手法の解説】言語モデルへの知識注入(P5~8)
⚪︎fine-turningについて
そもそもfine-turningって何?
- 事前に訓練されたモデルを特定のデータセットやタスク上で調整し、その特定のドメインにおける性能を向上させるプロセスのこと。
fine-turningの種類について
- 教師付きfine-turning(SFT)
- ラベル付けされた入出力のペアのセットを使用する
- 最も一般的なものにインストラクションチューニングがある。
- インストラクションチューニングは、モデル全体の質を向上させるのに非常に効果的
- 特にゼロショットと推論能力に重点が置かれている
- ただし、モデルに新しい知識を教えるとは限らない(この手法だけでは知識の注入問題の解決にはならない)
- 強化学習
- 人間府フィードバックからの強化学習(RLHF)や直接選好最適化(DPO)、近接政策最適化(PPO)がある。
- インストラクションチューニングと併用した場合に非常に有効
- この方法はインストラクションチューニングと同様に応答の全体的な品質とその期待される行動を重視するものであり、必ずしもモデルの知識の幅を重視するものではない
- 教師なしfine-turning
- 一般的な教師なしFT手法の1つは継続的な事前学習または、非構造化FTと呼ばれるものがある
- この手法は、モデルの継続学習とみなすこともできる
- 元のモデルの保存されたチェックポイントから開始し、因果的な自動回帰式で訓練をする。
- 事前学習との違い
- 学習率(壊滅的な忘却を避けるため、学習率をかなり低くする必要があること)
- LLMに知識を注入するために理にかなっている
- 一般的な教師なしFT手法の1つは継続的な事前学習または、非構造化FTと呼ばれるものがある
⚪︎RAGについて
そもそもRAGって何?
- 外部リソースを利用することでLLMの能力を拡張する手法のこと
- 補助的な知識ベースと入力クエリが与えられた時にRAGアーキテクチャを使って、知識ベースの中から入力クエリににた文章を見つけるというもの。これらの文章を入力クエリに追加することで、クエリの主題に関する更なるコンテキストをモデルに与えることができる。
4. 【本実験を行う前準備とその理由】ナレッジベースの作成(P8~11)
タスクの選択と理由
- タスク:MMLUベンチマーク
- タスクのジャンル:解剖学、天文学、大学生物学、大学化学、先史学、人文学
- 事実知識に重点を置き、推論への依存が最小限であることに基づいて選択した。
- ヒューリスティックで問題が短く、文脈を問わないものを選んだ
- 時事問題:LLMの能力をさらに分離するため
- 新しい知識を卓周するために、時事問題について多肢選択問題からなるタスクを作成
- アメリカの「時事問題」に焦点を当てて作成
- 理由:知識集約型タスクにおけるLLMの能力を適切に評価するため
- このアプローチは、LLMの推論プロセスと切り離し、情報を理解し操作する能力をテストすることを目的にしているため
データの収集と前処理
- データ収集:Wikipediaをスクレイピング
- 理由:関連トピックが豊富、群衆によって検証されているため
- 前処理:HTMLやURL削除
時事問題タスクの作成
-
GPT4で多肢選択(4つ)問題データセット作成
- その質問が文脈をさしているのか知らなくても回答でき、曖昧さを最小限にするように調整
手作業による評価と検証(合計で910問を作成した)
- その質問が文脈をさしているのか知らなくても回答でき、曖昧さを最小限にするように調整
-
パラフレーズ作成
- 単語の言い換えをGPTで作成(fine-turning時に使用するため)

- 単語の言い換えをGPTで作成(fine-turning時に使用するため)
5. 実験と結果(P11~14)
モデルの選択
- LLama2-7b, Mistral-7b, Orca2-7b
- 最も一般的なオープンソースのベースモデルであり、様々なベースライン能力にわたってインストラクションチューニングされたモデルを代表するものであるため
- RAGコンポーネントの埋め込みモデル:bge-large-en
- ベクトルストア:FAISS
- HuggingFace MTEBのリーダーボードの現在オープンソースエンべディングモデルのSOTAであるため
コンフィギュレーションのバリエーション
- ※複数のコンフィギュレーションを含み、それらをグリット検索
- 包括的なベンチマークを可能にするため
比較手法
- ベースラインモデル
- fine-turning
- RAG
- コンテキストに追加するテキストチャンクの最適な数:5つ
- 上記の3つにfew-shot(5つ)を追加で検証
トレーニングのセットアップ
- 教師なし学習で対応
- 各データセットについては元のチャンクの長さに基づいて連結または分割し、256サイズの等しいチャンクに分割
- また、文章の構造を保持するため、<BOS>と<EOS>といいう2つの特別なトークンを追加し、元のチャンクの始まりと終わりを区切った
- モデルは1e6 ~ 5e5のハイパーパラメータ検索で求めた学習率で学習を実施
- 全てのモデルは4つのNVIDIA A-100GPUで最大5エポック、バッチサイズ64で学習した
評価方法
- 全ての評価は質問に対する多肢選択式の各選択肢を保留しその連結をモデルに通して選択肢ごとの対数確率スコアを得ることによって行った
- 最も高いスコア=モデルの選択と解釈し精度の計算に使用した
MMLUの結果
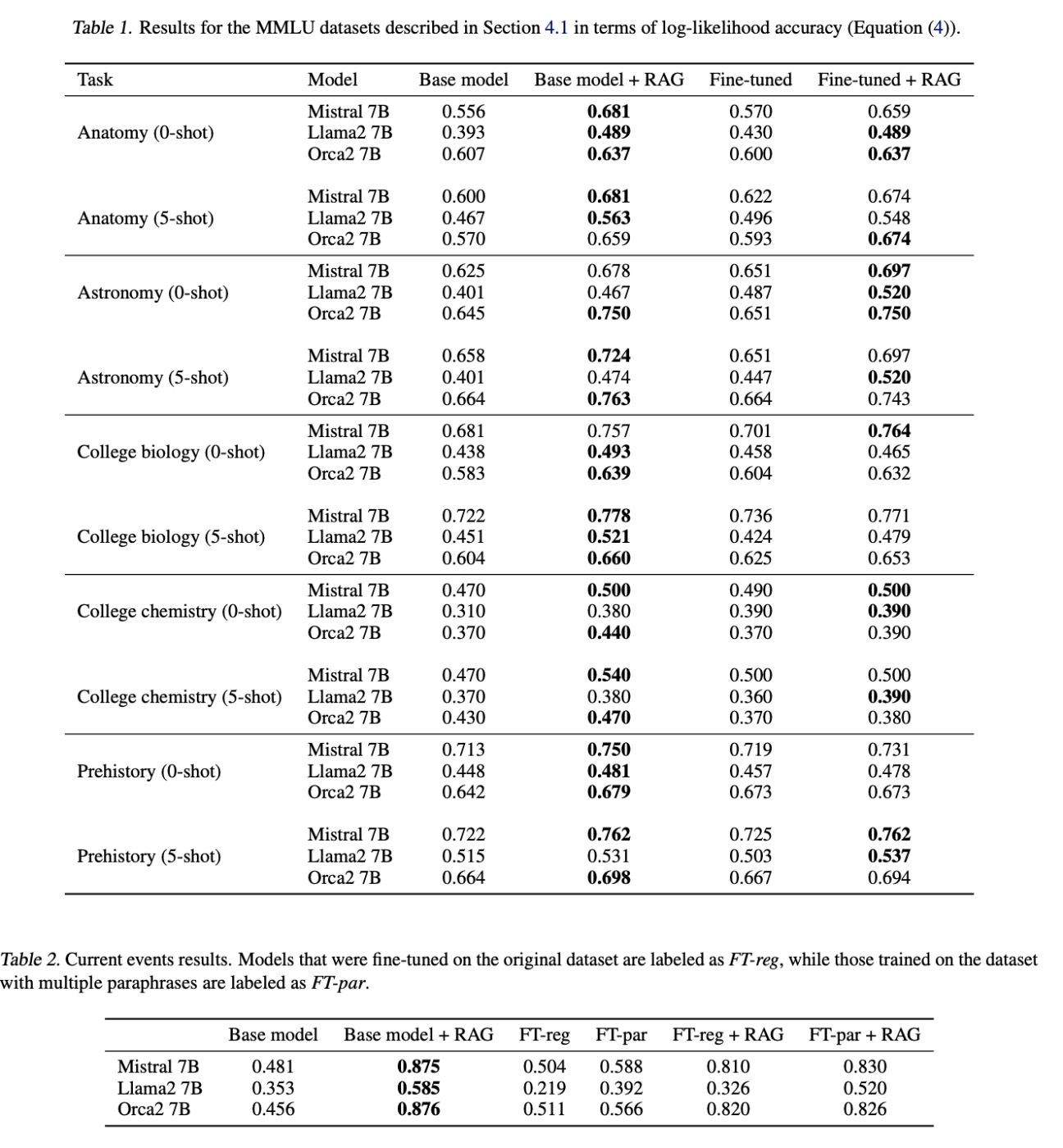
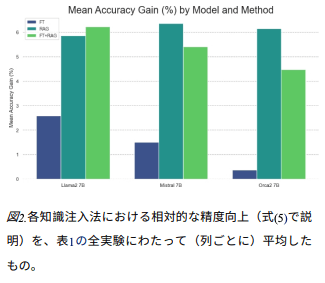
- 全てにおいてRAGはベースモデルと比較して有意な結果だった。
- ベースモデルをジェネレーターとしてRAGを使用することはfine-turningのみよりも一貫して優れていた。
- いくつかのケースでは、RAGパイプラインのジェネレーターとしてベースモデルの代わりにfine-turningされたモデルを使用することで結果がさらに向上したが、これには一貫性がみられず、不安定な結果だった。
- さらにfew-shot(5つ)では、ほとんどのケースでわずかな差で結果が向上し、同様の傾向が全ての異なるアプローチで観測された。
- fine-turningを加えたRAGはRAG単独と比較して劣る性能だった
- また、注目すべきは、質問はモデルがトレーニング中に触れていない情報に基づいているにも関わらず、ベースモデルの結果が0.25ポイント上回っている点にある
-
これは、過去の情報から独立していない質問を答えるとき、モデルが推論や既存の知識を使用することによって部分的に説明することができていることを意味する

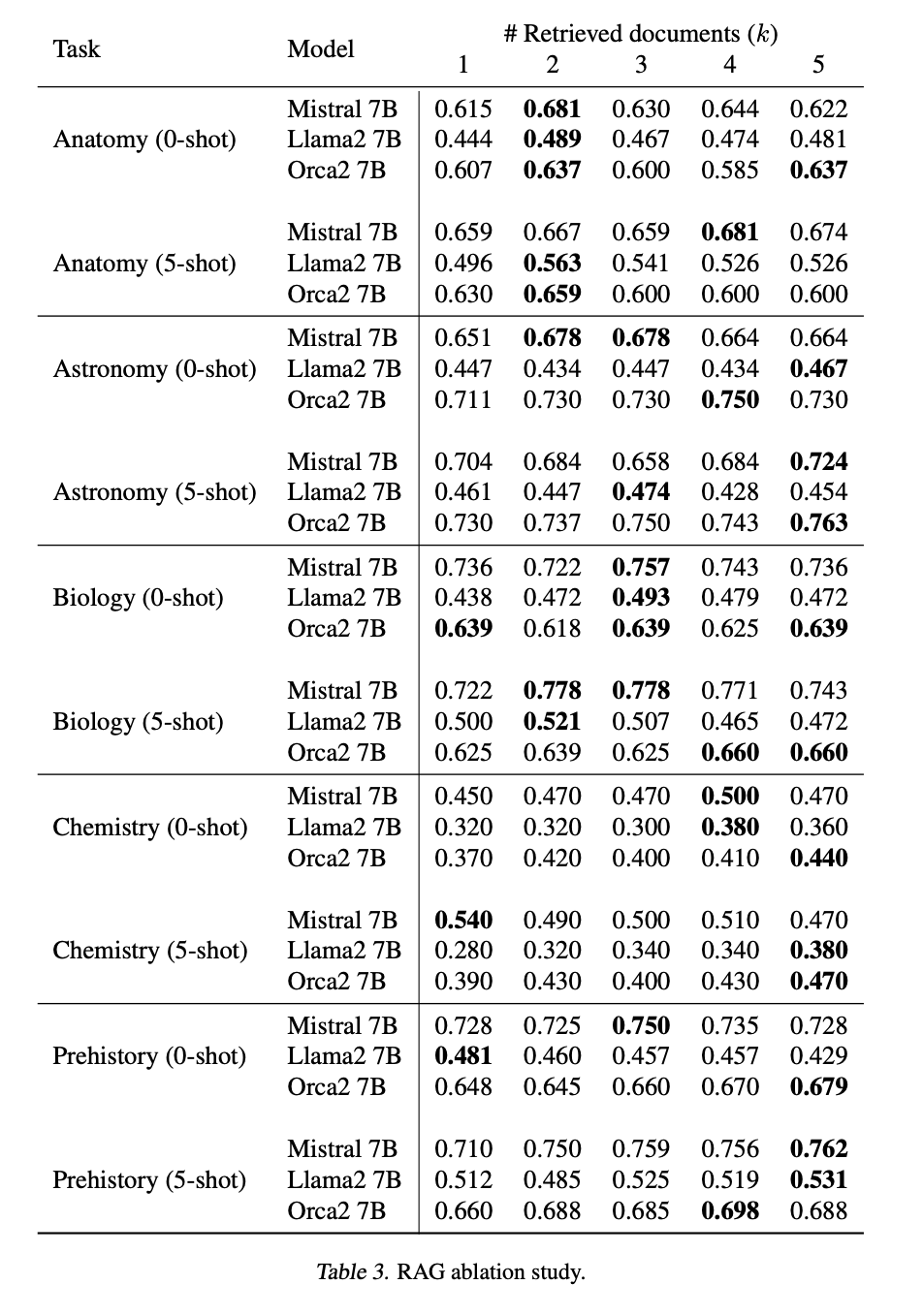
-
ファインチューニングとRAGの比較
- MMLUと時事問題の両タスクの結果では、RAGに優位性があった
- 要因として考えられるもの
- RAGはモデルに知識を追加するだけでなく、質問に関するコンテキストも取り込むことができるため
- fine-turningでは、壊滅的な忘却の程度によって、モデルのたの能力に影響を与えた可能性があるため
- 教師なしでfine-turningされたモデルはスーパーアライメントを通じてさらにアライメントをおこなうことで恩恵を受ける可能性がある
- 要因として考えられるもの
時事問題の結果
- RAGは質問と補助データセットが1対1に対応しているため、特に効果的であった
- fine-turningはRAGには叶わなかったが、複数の言い換えを使ったfine-turningはベースモデルよりも有意な改善をもたらしていた。
6. 繰り返しの重要性(P14~16)
- 他のタスクとは異なり、モデルは事前学習のトピックに関する側面に晒されている。この場合、標準的な通常のfine-turningではモデルの性能の向上しないばかりか、著しく低下した。そのため以下の手法を検討した
データ補強
- 言い換えを使ったデータの補強は以下のようなもの

単調改善
- 上記のデータ補強アプローチによって結果は顕著に改善された。
-
利用された言い換えの数と修正の精度の間に直接的な相関関係があることが示された。
-
この結果は、限られたデータから新しい知識を理解し一般化するモデルの能力に、情報の反復をもたらす言い換えの増加がプラスの影響を与えることを強く示唆している。
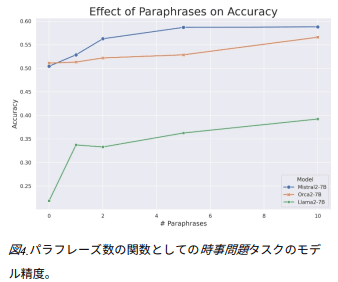
-
さらに、各エポック、つまりデータセット全体に対する反復学習を行うことで、学習損失が大幅に減少した。
- これはLLMga学習中にデータを記憶し、オーバーフィットしていると推測される。
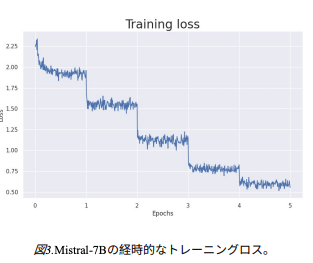
- これはLLMga学習中にデータを記憶し、オーバーフィットしていると推測される。
-
以上から、推測される仮説
-
事前に訓練されたLLMに新しい知識を教えるには、知識を何度も繰り返さなければならない
- これは事前学習でよく知られているが、様々な形式で情報をLLMに提供することで文の様々な関係性から文を理解することに繋がっている
- また、同時にバークランドらの「逆転の呪い」を改善できる可能性があると考えている(ただし、この結果には更なる研究が必要)
7. 結論と今後の課題(P16)
- LLMへの新しい知識(専門的なもの、全くみたことのないもの)注入という観点ではfine-turningよりRAGの方がより信頼性の高い選択である
必要な追加の研究
- インストラクションチューニングや強化学習ベースの手法を蜘蛛居合わせた場合の精度の比較
- 様々な補助知識ベースと様々なテクニックを組み合わせることで、より良い結果が得られるかもしれないため
- LLMにおける知識の表現の問題(特に倫理的な観点)
- LLMにおける知識の計測する方法
- 本研究では経験的アプローチを採用したが、知識に関する他の定義や視点も探究し、この研究を発展させることが重要であるため
8. 制限事項(P16)
- ハイパーパラメーターの選択の制約
- 結果に大きく依存するため
- 検証対象のLLMモデル数の制約
- 今回は代表的なオープンモデルを3種類しか検証していない
- そのため、他のLLMへの一般化は徹底的にテストされるべき
- 例えばGPT-4など(MMLUタスクでほぼ完璧な精度を達成している)
- 知識ベースの制約
- 今回は知識ベースとしてWikipediaを選択しているが、その他のデータセットや検索APIでは結果が異なる可能性がある。
Discussion