💡
LangChainマスターへの道
はじめに
- LangChainのモジュールを解剖していきたいと思います。
- 今後、1ヶ月くらいかけて解説を行っていきたいと思います。
📃 Model I/O:
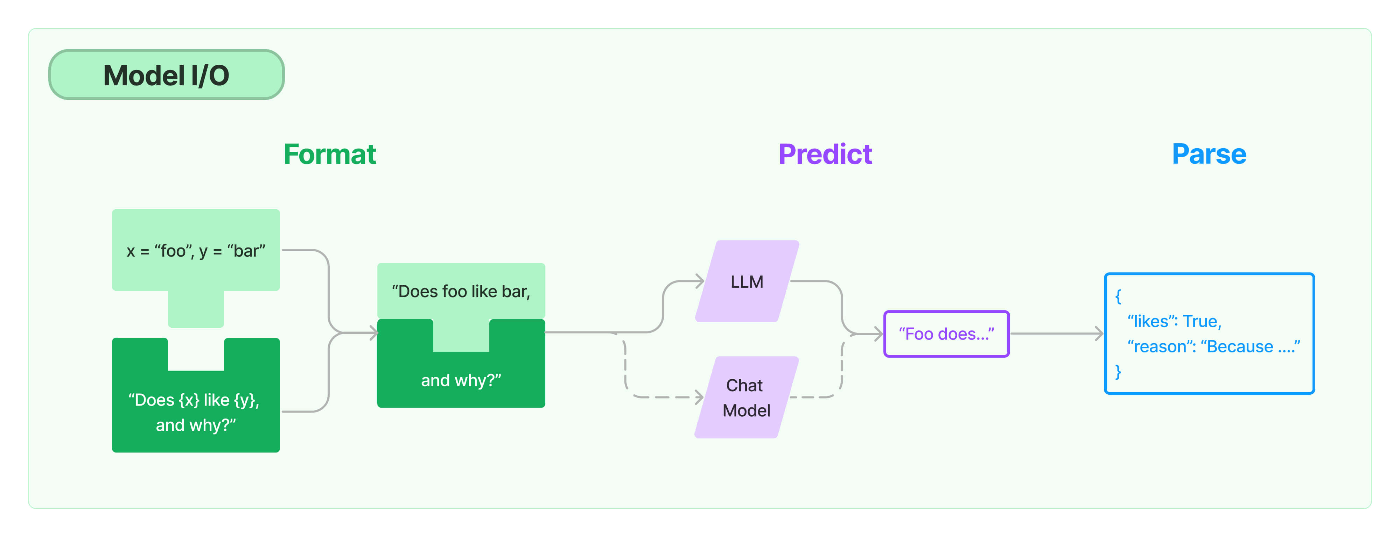
Prompts
- 言語モデルのプロンプトは、モデルの応答をガイドするためにユーザーによって提供される一連の指示または入力であり、モデルがコンテキストを理解し、質問に答える、文章を完成させる、または対話に参加するなど、関連性のある一貫した言語ベースの出力を生成するの際に役立ちます。
ChatModels
- チャット モデルは、LangChain のコア コンポーネントです。
- チャット モデルは、(プレーン テキストを使用するのではなく) チャット メッセージを入力として使用し、出力としてチャット メッセージを返す言語モデルです。
- LangChain は多くのモデル プロバイダー (OpenAI、Cohere、Hugging Face など) と統合されており、これらのモデルすべてと対話するための標準インターフェイスを公開しています。
LLMs
- 大規模言語モデル (LLM) は、LangChain のコア コンポーネントです。
- LangChain は独自の LLM を提供せず、多くの異なる LLM と対話するための標準インターフェイスを提供します。
- 具体的には、このインターフェイスは文字列を入力として受け取り、文字列を返すインターフェイスです。
Output Parsers
- 出力パーサーは、LLM の出力を取得し、それをより適切な形式に変換する役割を果たします。
- これは、LLM を使用してあらゆる形式の構造化データを生成する場合に非常に便利です。
📚 Retrieval
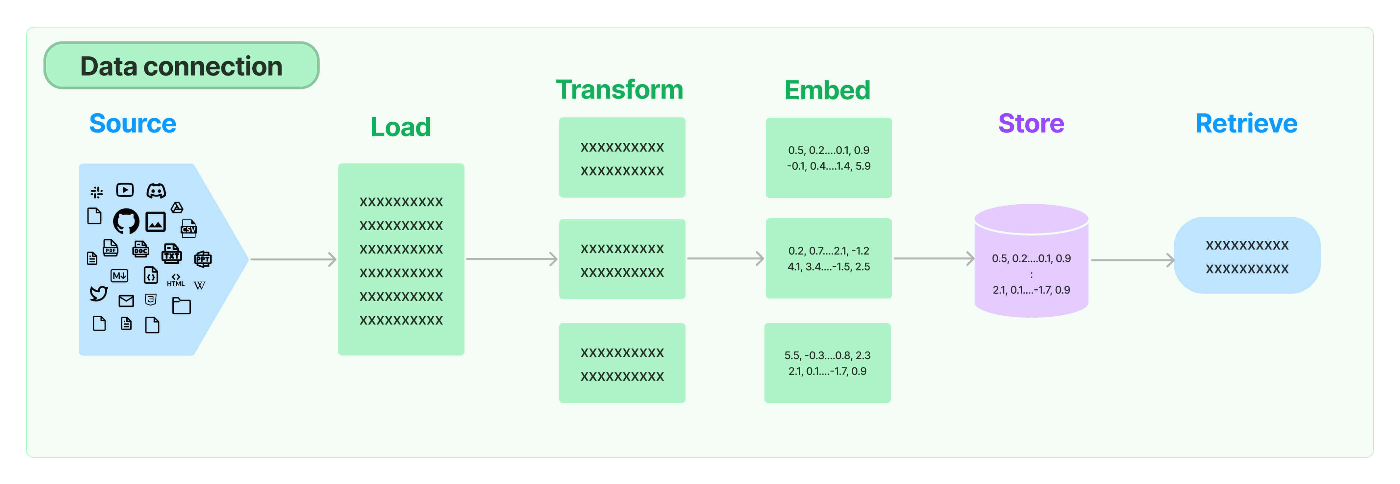
Document loaders
- さまざまなソースからドキュメントをロードします。
- LangChain は、100 を超える異なるドキュメント ローダーを提供するだけでなく、AirByte や Unstructed など、この分野の他の主要プロバイダーとの統合も提供します。
- LangChain は、あらゆる種類の場所 (プライベート S3 バケット、パブリック Web サイト) からあらゆる種類のドキュメント (HTML、PDF、コード) をロードするための統合を提供します。
Text Splitting
- 検索の重要な部分は、ドキュメントの関連部分のみを取得することです。
- これには、文書を取得できるように準備するためのいくつかの変換ステップが含まれます。
- ここでの主な処理の 1 つは、大きなドキュメントを小さなチャンクに分割 (またはチャンク化) することです。
- LangChain は、これを行うためのいくつかの変換アルゴリズムと、特定のドキュメント タイプ (コード、マークダウンなど) に最適化されたロジックを提供します。
Text embedding models
- 検索のもう 1 つの重要な部分は、ドキュメントの埋め込みを作成することです。
- 埋め込みはテキストの意味論的な意味を捉え、類似したテキストの他の部分を迅速かつ効率的に見つけることができます。
- LangChain は、オープンソースから独自の API まで、25 を超える異なる埋め込みプロバイダーおよびメソッドとの統合を提供し、ニーズに最適なものを選択できるようにします。
- LangChain は標準インターフェイスを提供し、モデル間を簡単に交換できます。
Vector stores
- エンベディングの増加に伴い、これらのエンベディングの効率的な保存と検索をサポートするデータベースの必要性が生じています。
- LangChain は、オープンソースのローカルなものからクラウドでホストされている独自のものまで、50 を超える異なるベクトルストアとの統合を提供し、ニーズに最適なものを選択できるようにします。
- LangChain は標準インターフェイスを公開しているため、ベクター ストア間を簡単に切り替えることができます。
Retrievers
- データがデータベースに保存された後は、それを取得する必要があります。LangChain はさまざまな検索アルゴリズムをサポートしており、最も価値を付加できる場所の 1 つです。LangChain は、簡単に開始できる基本的な方法、つまり単純なセマンティック検索をサポートしています。ただし、パフォーマンスを向上させるために、これにアルゴリズムのコレクションも追加しました。これらには次のものが含まれます。
- Parent Document Retriever
- これにより、親ドキュメントごとに複数の埋め込みを作成できるようになり、より小さなチャンクを検索して、より大きなコンテキストを返すことができます。
- Self Query Retriever
- ユーザーの質問には、単なるセマンティックではなく、メタデータ フィルターとして最もよく表現できるロジックを表現するものへの参照が含まれることがよくあります。セルフクエリを使用すると、クエリ内に存在する他のメタデータ フィルターからクエリのセマンティック部分を解析できます。
- Ensemble Retriever
- 複数の異なるソースから、または複数の異なるアルゴリズムを使用してドキュメントを取得したい場合があります。アンサンブル・レトリーバーを使用すると、これを簡単に行うことができます。
- もっと!
Indexing
- LangChain Indexing API は、あらゆるソースからのデータをベクター ストアに同期し、次のことを支援します。
- 重複したコンテンツをベクター ストアに書き込まないようにする
- 変更されていないコンテンツの再書き込みを避ける
- 変更されていないコンテンツに対する埋め込みの再計算を避ける
🤖 Agents
Agent Types
- エージェントにはさまざまな種類があります。さまざまなタイプの概要とそれらをいつ使用するかについて
Tools
- エージェントの能力は、彼らが持っているツールによって決まります。ツールに関する包括的なガイド
🔗Chain
- チェーンとは、LLM、ツール、またはデータ前処理ステップなどの呼び出しのシーケンスを指します。
Memory(beta)
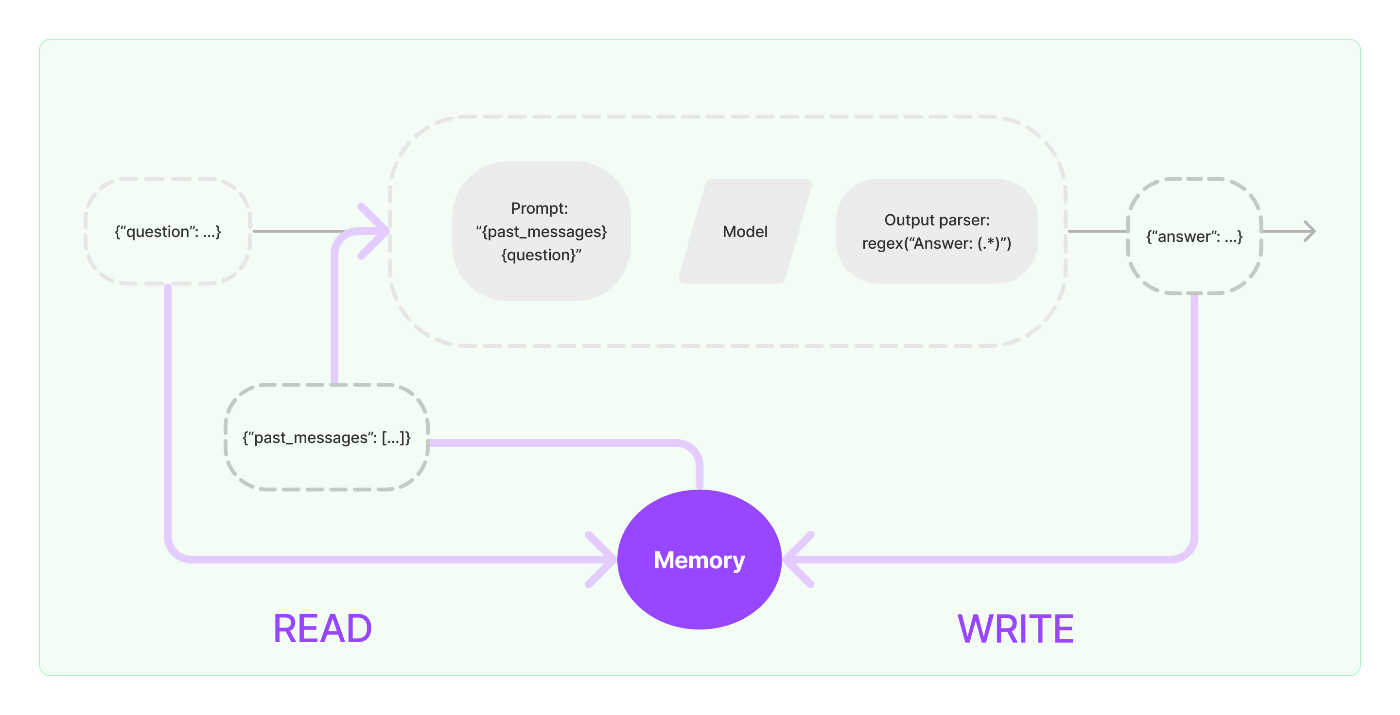
- 過去のやり取りに関する情報を保存するこの能力を「Memory」と呼びます。LangChain は、システムにメモリを追加するためのユーティリティを多数提供します。これらのユーティリティは、単独で使用することも、チェーンにシームレスに組み込むこともできます。
Callbacks
- これは、ログ記録、監視、ストリーミング、その他のタスクに役立ちます。
Discussion