Dataflow をやめて Pub/Sub BigQueryサブスクリプションを使うようにしたら、月100万円コストを削減できた話
はじめに
こんにちは。
本記事では、 Dataflow を使わずに Pub/Sub だけでシンプルなパイプラインを構築することで、約月100万円のコスト削減に成功した話を共有します。クラウドコスト最適化を目指す方の参考になれば幸いです。
背景
あるプロジェクトで、リアルタイムデータを効率的に処理し、分析基盤に反映するためのパイプラインが稼働していました。私は最初のパイプライン構築には携わっておらず、運用フェーズでコストが問題になっていることを知り、改善に取り組むことになりました。
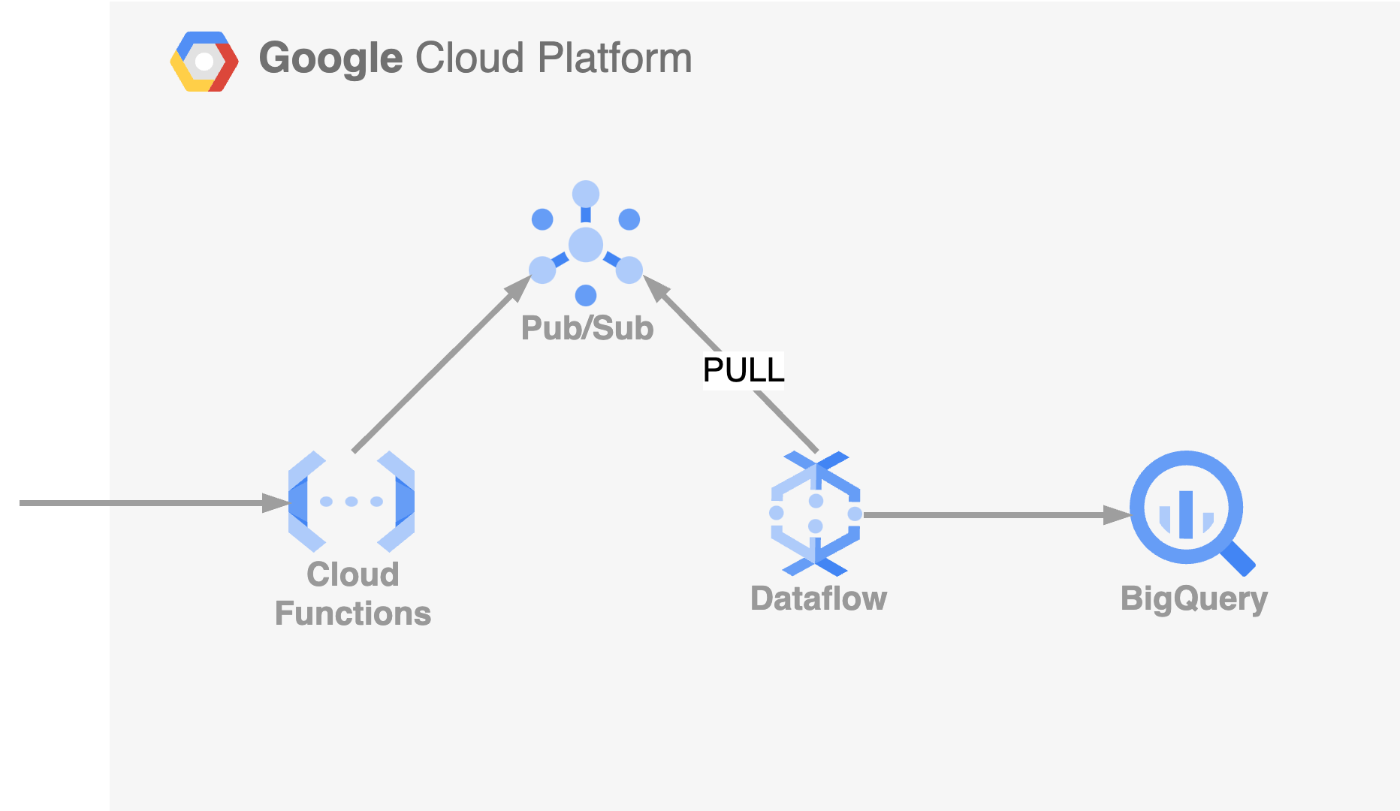
改善前のアーキテクチャ図
- Cloud Functions: データ受信および前処理を行い、処理済みデータを Pub/Sub トピックにメッセージとして発行
- Cloud Pub/Sub トピック: データの一時保管(バッファリング)およびデータ転送
- Cloud Pub/Sub PULL サブスクリプション: Dataflow がメッセージを Pull して受信
- Dataflow: 受け取ったデータの変換や整形処理をして BigQuery へ挿入
この構成では、大規模なデータ処理においてスケーラブルで高い可用性を持つものの、運用開始後にコストが予想以上に膨らんでしまう問題が発生しました。
コスト高騰の原因
運用開始から数ヶ月後、月々のコストが予想よりも高騰しており、特に Dataflow の利用料金が大部分を占めていることがわかりました。具体的には、月額 100 ~ 110 万円ほどのコストが発生しており、これは当初想定していたよりも大きな負担となっていました。
詳細に分析した結果、次のようなことが分かりました。
-
Dataflow のコスト高騰
- Pub/Sub から Pull サブスクリプションを通じて大量のメッセージが流れてくるため、Dataflow のワーカーが自動でスケールアウトしていた
- その結果、ワーカーの CPU やメモリの利用料金が大幅に増加していた
-
ウィンドウ処理が不要
- 時系列データの集計など複雑なタイムウィンドウ処理は必要なく、データは即座に BigQuery に保存するだけで良かった
-
変換処理が軽微
- データ整形は単純で、Dataflow のような高度なデータ処理フレームワークを使用する必要はなかった
コスト削減策
上記の課題を踏まえ、次のような構成へ変更を行いました。

改善後のアーキテクチャ図
- Cloud Functions: データ受信や前処理
- Cloud Pub/Sub トピック: データバッファリング
- Cloud Pub/Sub BigQuery サブスクリプション: Pub/Sub が直接 BigQuery にストリーミング挿入
具体的な変更ポイントは以下の通りです。
Pub/Sub の BigQuery サブスクリプションで直接 BigQuery に挿入
Dataflow を使わず、Pub/Sub の BigQuery サブスクリプション機能を活用してメッセージを直接 BigQuery に挿入するようにしました。
BigQuery サブスクリプションを利用することで、 Pub/Sub のメッセージを直接 BigQuery テーブルにストリーミング挿入することができます。メッセージが到達次第、サブスクリプションに設定された BigQuery のテーブルへ自動で挿入してくれます。
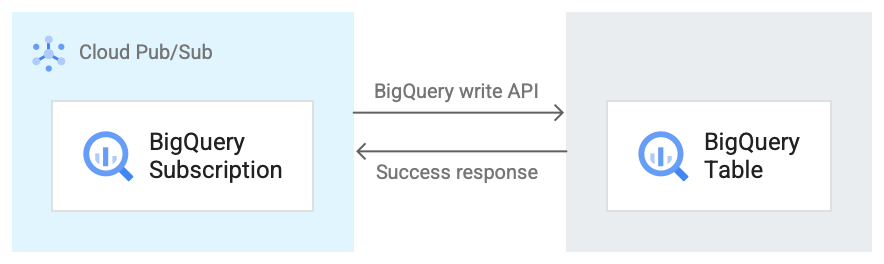
具体的な BigQuery サブスクリプションのワークフローは以下の通りです。(引用: BigQuery サブスクリプション ワークフロー)
BigQuery サブスクリプションのワークフロー
- Pub/Sub は、BigQuery Storage Write API を使用して BigQuery テーブルにデータを送信します。
- メッセージはバッチで BigQuery テーブルに送信されます。
- 書き込みオペレーションが正常に完了すると、API は OK レスポンスを返します。
- 書き込みオペレーション中にエラーが発生した場合、Pub/Sub メッセージ自体に否定応答が行われます。 その後、メッセージが再送信されます。メッセージが十分な回数失敗し、サブスクリプションにデッドレター トピックが構成されている場合、メッセージはデッドレター トピックに移動します。
変換処理の移行
軽微なデータ変換は Dataflow ではなく、Cloud Functions に移行しました。具体的には、フィールドの追加や型変換など単純な処理のみが必要だったため、Dataflow の高度な処理能力は不要と判断しました。
結果
上記の解決策を実施することで、以下の効果が得られました。
コスト削減
Dataflow の利用料金が完全になくなり、月額コストは以前の 約100万円 から 数万円 に大幅に削減されました。
改善前は Dataflow のワーカーの CPU やメモリの利用料金が高くなっていましたが、それがなくなりました。その分 Pub/Sub では利用料金が増えましたが増えたのは BigQuery サブスクリプションの料金ですが、こちらが予想以上にお安く利用できました。
Dataflow
- 100 ~ 110万円
+ 0円
Pub/Sub BigQueryサブスクリプション
- 0円
+ 3 ~ 5万円
パフォーマンス向上
Dataflow のスケールアウトやジョブ遅延が発生しなくなり、BigQuery へのデータ挿入がより安定し迅速になりました。
具体的にはサブスクリプションがサブスクライバーへメッセージを送信し確認応答が返ってくるまでの時間やメッセージキューに滞留するメッセージが減りました。
また 変換処理を全て Cloud Functions に移行したことによる Functions の実行時間は若干高まったものの、 Cloud Functions は自動スケールするため特にパフォーマンスへの影響はありませんでした。
運用負担軽減
今回の取り組みで次のような運用面の負担が軽減されました。
-
ジョブ管理の不要化
- Dataflow ジョブのエラー対応やパフォーマンス監視が不要になった
-
バージョン管理の負担軽減
- Dataflow は Apache Beam の実行環境を提供するサービスであり、サポートされる Apache Beam のバージョンが限られている
- セキュリティや機能改善のため定期的なバージョンアップが必要だったが、不要になった
BigQuery サブスクリプションを作るだけで発行されたメッセージがテーブルへ挿入されるようになるので、管理する対象が減ったのはとても良かったなと思います。
注意
今回使用した BigQuery サブスクリプションですが、リージョンごとの BigQuery サブスクリプションのスループットに制限があります。
東京リージョン(asia-northeast1)は以下の制限があります。導入する場合は必要に応じて割り当て値の引き上げをリクエストの検討をおすすめします。
1 分あたり 48,000,000 KB(800 MB/秒)
詳しくはこちらをご覧ください。
まとめ
今回の改善では、Dataflow の使用をやめ Pub/Sub の BigQuery サブスクリプションへの移行によって、シンプルかつ低コストなデータ処理パイプラインを実現しました。
この構成は本当に最適かと問い続ける姿勢が、より良いシステム作りにつながると実感しました。引き続き、効率的でシンプルなアーキテクチャ設計に取り組んでいきたいと思います。
参考
Discussion