【kaggle】 ベンガル語音声認識コンペの振り返り
2023/7/18-2023/10/18で、ベンガル語の音声認識(ASR)に関するコンペティション(Bengali.AI Speech Recognition)がKaggleで開催されていました。
解法をまとめるには遅すぎですが、最近コンペティションに参加する余裕がないのでせめて記事でも。。。という思いでコンペティションの解法をまとめてみました。
Audio系のコンペティションはそれほど多くないので参考になればと思います。
(書き終えた後に3rdの方の記事に気づきました。。。そちらも是非ご参考ください)
コンペの概要
タスク
音声を入力して、その発話テキストを出力するという、非常にシンプルな音声認識タスクです。
評価指標
音声認識タスクではデファクトなWER(Word Error Rate)です。[1]
WERは正解単語数に対して、置換や挿入、削除といった操作がどのくらい行われたかで計算されます。間違いがなければ0です。
データセット
データセットはCommoVoiceのベンガル語が利用されました。
CommoVoiceはクラウドソーシングで集めた文章を読み上げデータセットで、誰でも自由に参加することができます。
一部のデータに関しては品質の評価が行われており、ホストから検証データとして提供されました。 一方で訓練データとして提供された大半の音声は検証が行われておりません。
そのため、訓練データは、発話の前後にかなり長い無音がある、環境のノイズがひどいを多数含むデータセットになっています。最もひどい場合だと、音声データが破損しており、読み上げデータとして全く機能しないデータもありました。
提供されたデータは25GBほどです。今回のコンペティションでは、いかにしてこのデータセットからクリーンなラベルを利用して学習できたかで差がついた印象でした。
また、テストセットはYoutubeなどから採取した音声などで占められている点が特徴的でした。そのため、訓練セットのような読み上げ音声ではなく、自然発話や、音楽や効果音が含まれており、こういったOut Of Distributionなドメインで性能を発揮できるかどうかも課題でした。
これが理由で、検証データの性能が役に立たず、残念ながらCV/LBスレが立ちませんでした。
文字起こしテキストに含まれる記号
スコアはWERで計算されます。
WERは単語単位で計算するため、発話単語が正しくても、正解データに句読点が含まれている場合、それが一致しないとペナルティになります。
例えば
予測:「こんにちは 今日は 朝に スープを 飲みました」
正解:「こんにちは、今日は 朝に スープを 飲みました。」
最初と最後の単語で句読点が予測できていないので、WERが0.75となります(句読点を予測する必要がなければ、全単語正解でWER=0)。そのため記号を外すことは大きなペナルティとなります。
データセットにはいくつかの記号(, .!? etc...)を含んだテキストがある程度ありました。
通常のASRモデルでは発声しない記号などは予測できないため、これらをどのように扱うかは非常に重要な要素でした。[2]
解法のポイント
重要なポイントは2点でした
- ノイズが多い訓練データセットのフィルタリング
- 記号の予測
解法の詳細
主にスコアが異次元である1stと、金圏内でもスコアが頭一つ抜けている2ndと3rdを紹介したいと思います。
*順位が文脈で示されている部分以外は私の補足です
モデル
- Whisper (medium)
- 金圏上位では1st place のみが上手く機能させていました。スコアは2位以下をダントツで引き離しています。(1stのprivateスコアが0.372で2ndが0.412)
- ベンガル語に対する音声認識はイマイチなようで、コンペティション初期からこのモデルをFinetuningするnotebookが公開されておりました。しかし、主に計算リソースの問題で後述するwav2vecベースのモデルを使ったベースラインには遠く及ばすといった感じでした。
- 最後までwav2vecのベースラインを超えるWhisperノートブックが現れず、なぜ性能が悪いのかは参加者の関心事で、Discusstionも散見されました。
- 投稿者は普段からASRを仕事で行っているらしく、経験的にWhisperの特徴として、OODに強いこと、一方で欠点としてノイズに非常に敏感であることがsolutionで述べられています
- ちなみに8xA6000というとんでも計算リソースを利用したようです
- IndicWav2Vec
- 参加者のほとんどはIndicWav2Vecというwav2vecベースのモデルを使っています。(金圏では1stと10th以外)
- wav2vecは2020年頃に発表されたモデルで、大量の生の音声データから自己教師あり学習で事前学習を行い、音声表現を学んだ後、対象のドメインで微調整することで高い音声認識能力を得ます。
- ベンガル語を含むインド諸語で事前学習したIndicWav2Vecがパブリックに公開されており、このモデルを使ったノートブックがベースラインとなっていました。Whisperに比べると比較的軽量で扱いやすいモデルになっています
wav2vecのLanguage Model
- wav2vecは文字単位で予測を行います。Ngram Language Modelを使うと、LMが持つコーパス情報を使って、尤もらしい単語でデコードできるようになり、大幅にスコアが向上します。
- LMモデルにはKenLMというライブラリがよく利用されているようです。HuggingFaceの
Wav2Vec2ProcessorWithLMを使えば簡単にこのKenLMモデルを使ったデコードを挟むことができます。他にもflashlight-textなどがあるようですが、扱いやすさからほとんどがWav2Vec2ProcessorWithLMを使ってたと思います。
- ちなみに外部コーパスをすべて含めると40GBほどになり、その5gramを作成しようとすると200GBは普通に超えました。
- KenLMにはbin化やpruningなどのオプションがあり、それで圧縮すると大体の10~20GBの間になります(ほぼLLMでは?)
- 私の観測では、コーパスサイズを増やすだけで、ある程度までスコアを伸ばせますが、結局ASR側の性能が大切であり、そっちが伸びないとコーパスサイズ増によるLMによるデコードの恩恵は低減してた印象です。
データのクリーニング
- このコンペティションのキモです。クリーニングが行われていないデータで訓練を行うと、精度が上がらないことが述べられています(3rd)
- 上位3名の解法を見ると三者三様ですが、基本的にはモデルを一旦訓練して予測を行い、WERが高いものをしきい値を使って捨てるというシンプルなものです。
- 1stは外部データを使って段階的にモデルを訓練しています
- まずは比較的綺麗な外部読み上げデータセット(OpenSLR)とGoogleのText-to-Speechによる自動読み上げで作成した音声データを使って、1stステージモデルを訓練
- 1stステージのモデルで、訓練データと他の外部データセットに対して推論を行い、WER<15%のみのデータをサンプリング。それらを使い2ndステージの訓練を行う
- 2ndは外部データセットも含めて、すべてのデータで訓練した後で、WER<10%のみを保持するというシンプルな方法です。
- 3rdも段階的に訓練を行なっていますが、外部データは利用していません。
- 1stステージでは検証されたクリーンな訓練データであるvalidationサブセットを使って、モデルを訓練
- その後訓練セットを予測、WER<0.75のみのデータをサンプリングして、2ndステージの訓練を行う
データ増強
- 上位3チームでは1stと2ndのみ音声の増強が行われています。
- 訓練中の短い音声の結合。(1st、2nd)
- 16KHz → 8KHz →16KHzというサンプリングレートの操作による増強。 (1st)
- speedとpitchを変更するなど。(1st)
- バックグラウンドのノイズの追加。(2nd)
- ASRのデータセットには読み上げと自発的な発生の音声データの2種類で大きく分かれますが、読み上げにはよりハードな拡張を使ったとのこと。
擬似ラベル
- 1stに特徴的な解法としてYoutubeからスクレイピングした音声による擬似ラベル作成があります。
- 音声認識のラベルですが、音源と文字起こしはペアでなければなりません。読み上げなら必ずペアになりますが、長尺のYoutube音声からWhisperが学習可能な30秒のラベルを作成するとなると少し工夫が必要になります。
- この点について、まずVAD(Voice Activity Detection; 音源の中で発話されている区間を特定する手法)を使って、5-22秒ほどの発話区間を切り出し、それを疑似ラベルとしたようです。

疑似ラベル作成のイメージ
記号予測モデル
- このコンペの2つの目のキモですが、手法は単純で、ベンガル語は英語のように単語と単語の間に空白をもつので、そこに記号が入るかを予測するToken Classificationタスクを解いています。
- 利用されたモデル
- google/muril-base-cased (1st)
- インド諸語で事前学習されたBERT
- ai4bharat/IndicBERTv2-MLM-Sam-TLM(2nd)
- xlm-roberta(3rd)
- google/muril-base-cased (1st)
- T5のようなEncoder-Decoderモデルは機能しなかったようです。(3rd)
- ちなみに私は句読点モデルの作成はサボって、wav2vecの辞書に記号を含めて、LMのデコーディングの際に記号の予測を任せるという感じにしました。
その他
- Tokenizerの改良(1st)
- WhisperはTransformerを使って自己回帰的に文字をデコードする関係で非常に推論が遅いです。
- そのため、tokenizerをベンガル語に学習しなおして、過剰にトークンが分割されるのを避けて推論を高速化させるという手法が含まれていました。[3]
- Demucsを使った音源分離(3rd)
- Demucsは楽曲からヴォーカルなどを分離するモデルです。テストセットにはバックグラウンドミュージックを含む音源も含まれているので、そういった音声には有効だったのかもしれません。
- ただし、特に必要のない音源に対してこのような処理を行うと、処理前よりスコアが悪化するケースも存在します。
- 公開されていないテストセットではそのような音源を機械的に判別するのは難しいので、未処理、処理済みでそれぞれ予測して、予測トークンの数を比べるという手法で対応がなされています。
- アンサンブル
- whisper、wav2vecどちらも使っても可変長のテキストを出力することから、logistを平均するような単純なアンサンブルは利用できません。
- 5thは音声表現のEmbeddingをconcatして、それを入力としたTransformerを構築しています。
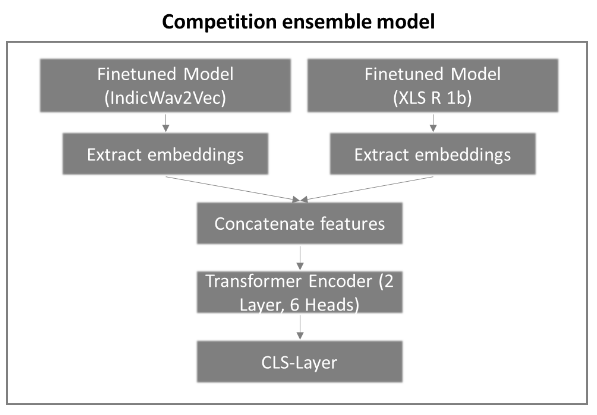
5thのソリューションより引用
感想
英語以外+音声ドメインということからか?そこまで大きな盛り上がりとはなりませんでしたが、データセットに関する論文[4]があったり、ホストが積極的に参加者とコミュニケーションを取っており、非常に良いコンペだったと思います。
-
テストセットはサンプルが採取された分野でタグ付けされていたので、正確にはタグ毎のWERの平均。ただし参加者はタグにアクセスできない ↩︎
-
参加者から削除するほうが本質的に音声を認識しているかどうか測れるのでは?という議論もありましたが。ホスト曰く、句読点があることは実際のアプリケーションにおいて重要であると考えて、句読点を含めたとのことでした。 ↩︎
-
こういった試み、マルチリンガルで学習した大規模モデルをモノリンガルに適用させるのに結構有用だと思うんですが、研究とかってされてるんでしょうか。詳しい人いたら教えてください。 ↩︎
-
OOD-Speech: A Large Bengali Speech Recognition Dataset for Out-of-Distribution Benchmarking ↩︎
Discussion