【Nextjs ✖️ Amazon Rekognition 】顔分析アプリを作って遊んでみた
はじめに
今回、顔認証機能を実装するためにAmazon Rekognitionを使用する機会がありました。
当初は顔認証について記事を書こうと考えていましたが、コードや説明が長くなりそうだったため、内容をシンプルにして「顔分析」に焦点を当てることにしました。
Next.js 15(App Router)とAmazon Rekognitionを使って、サクッと顔分析アプリを作成します。
Amazon Rekognitionについて
Amazon Rekognitionは、AWSが提供する機械学習ベースの画像・動画分析サービスです。画像や動画から物体、人物、テキスト、シーン、アクティビティなどを検出し、高精度な分析結果を提供します。
主な機能
- 顔検出と分析(年齢、感情、表情などの推定)
- 顔認証(本人確認)
- 有名人の認識
- 不適切なコンテンツの検出
- テキスト検出(画像内の文字認識)
- 物体やシーンの検出
料金体系
- 画像分析:1,000枚あたり1ドル
- 顔のメタデータ保存:1,000個の顔メタデータあたり0.01ドル/月
- 動画分析:分析した動画の1分あたり0.10ドル
- 無料利用枠:最初の12か月間、月間5,000枚の画像処理が無料
料金は従量課金制で、使用した分だけ支払う仕組みになっています。また、リージョンによって料金が若干異なる場合があります。
プロジェクトの作成
まずは、以下のコマンドを実行して Next.js のプロジェクトを作成します。
npx create-next-app@latest
ライブラリのインストール
Amazon Rekognition で顔分析を行うために、必要なライブラリをインストールします。
npm i @aws-sdk/client-rekognition
また、顔画像を撮影するために、Webカメラを簡単に実装できるライブラリもインストールします。
npm i react-webcam
環境変数の設定
プロジェクトのルートディレクトリに .env.local ファイルを作成し、以下の内容を記述します。
AWS_REGION=ap-northeast-1
AWS_ACCESS_KEY_ID=your-access-key-id
AWS_SECRET_ACCESS_KEY=your-secret-access-key
Amazon Rekognition を使用するには、アクセスキー と シークレットアクセスキー が必要です。
これらのキーは、事前に AWS マネジメントコンソールから取得してください。
取得方法については、インターネット上に多くの解説記事がありますが、参考になりそうな記事を紹介しておきます。
リージョンは、とりあえず ap-northeast-1(東京リージョン) を指定していますが、用途に応じて適宜変更してください。
顔画像を撮影するためのページを作成
app/page.tsx に以下のコードを追加します。
// app/page.tsx
"use client";
import Image from "next/image";
import { useRef, useState } from "react";
import Webcam from "react-webcam";
export default function Home() {
const webcamRef = useRef<Webcam>(null);
const [image, setImage] = useState<string | null>(null);
const capture = () => {
const imageSrc = webcamRef.current?.getScreenshot();
if (imageSrc) {
setImage(imageSrc);
}
};
return (
<div className="max-w-100 mx-auto p-4 flex flex-col items-center gap-4">
<h1 className="text-2xl font-bold">顔分析</h1>
<Webcam
className="rounded-lg"
ref={webcamRef}
screenshotFormat="image/jpeg"
/>
<button
className="w-full bg-green-500 hover:bg-green-600 cursor-pointer text-white px-4 py-1.5 rounded-md"
onClick={capture}
>
写真を撮る
</button>
{image && (
<div>
<h3 className="mb-2 text-lg font-medium">撮影された写真</h3>
<Image
src={image}
alt="撮影された写真"
width={300}
height={200}
className="rounded-lg"
/>
</div>
)}
</div>
);
}
このコードでは、react-webcam ライブラリを使用して、Webカメラを表示し、写真を撮影できるようにしています。具体的には以下の手順を行っています:
-
Webカメラの表示
Webcamコンポーネントを使用して、Webカメラ映像をページに表示します。 -
写真撮影
capture関数で、Webカメラの現在の映像をキャプチャし、imageステートに保存します。 -
撮影した写真の表示
撮影した画像があれば、
<Image>コンポーネントを使って表示します。
これで、ブラウザ上で簡単に画像を撮影できるページが作成されました。
顔分析APIの実装
このセクションでは、Amazon Rekognition を使用して、画像から顔を検出するAPIを実装します。
画像内から顔を検出し分析する為に Amazon Rekognition の DetectFacesCommand を使用します。
app/api/analyze-face/route.tsに以下のコードを追加します。
// app/api/analyze-face/route.ts
import { NextRequest, NextResponse } from "next/server";
import {
RekognitionClient,
DetectFacesCommand,
} from "@aws-sdk/client-rekognition";
const rekognition = new RekognitionClient({
region: process.env.AWS_REGION || "ap-northeast-1",
credentials: {
accessKeyId: process.env.AWS_ACCESS_KEY_ID || "",
secretAccessKey: process.env.AWS_SECRET_ACCESS_KEY || "",
},
});
export async function POST(request: NextRequest) {
try {
// リクエストからJSONを取得
const body = await request.json();
const { imageData } = body;
if (!imageData) {
return NextResponse.json(
{ message: "画像データがありません" },
{ status: 400 }
);
}
// Base64データを取り出す
const base64Data = imageData.replace(/^data:image\/\w+;base64,/, "");
const buffer = Buffer.from(base64Data, "base64");
// Rekognitionで顔分析
const detectFacesResponse = await rekognition.send(
new DetectFacesCommand({
Image: {
Bytes: buffer,
},
Attributes: ["ALL"], // すべての属性を取得
})
);
// 顔が検出されなかった場合
if (
!detectFacesResponse.FaceDetails ||
detectFacesResponse.FaceDetails.length === 0
) {
return NextResponse.json({
success: false,
message: "顔が検出されませんでした",
});
}
// 検出結果を返す
return NextResponse.json({
success: true,
message: "顔分析に成功しました",
faceCount: detectFacesResponse.FaceDetails.length,
faceDetails: detectFacesResponse.FaceDetails,
});
} catch (error) {
console.error("エラー:", error);
return NextResponse.json(
{ message: "エラーが発生しました", error: String(error) },
{ status: 500 }
);
}
}
このコードは、画像データを受け取って顔分析を行い、結果を返すAPIエンドポイントを実装します。
-
Rekognitionクライアントの作成
RekognitionClientを使用して、Amazon Rekognitionサービスにアクセスするためのクライアントを作成します。リージョンや認証情報は環境変数から取得します。 -
Base64データの変換
受け取ったBase64エンコードされた画像データから、不要なプレフィックス(data:image/xxx;base64,)を削除し、Buffer形式に変換します。これにより、画像データをAmazon Rekognitionに送信できる形式にします。 -
顔分析の実行
DetectFacesCommandを使って、画像内の顔を分析します。Attributesパラメータで、顔の詳細情報(年齢、感情、表情など)を取得します。 -
結果の処理
顔が検出されなかった場合は、顔検出の失敗を示すメッセージを返します。顔が検出された場合は、顔の詳細情報(例えば年齢や感情)と顔の数を返します。
このAPIを使うことで、Webカメラから撮影した画像を送信し、顔の検出や分析を行うことができます。DetectFacesCommandによって取得される顔の属性を使って、さらに詳細な分析やカスタマイズが可能です。
レスポンスを取得して表示
app/page.tsx を以下ように編集します。
// app/page.tsx
"use client";
+import { FaceDetail } from "@aws-sdk/client-rekognition";
import Image from "next/image";
import { useRef, useState } from "react";
import Webcam from "react-webcam";
+interface FaceAnalysisResult {
+ success: boolean;
+ message: string;
+ faceCount?: number;
+ faceDetails?: FaceDetail[];
+}
+// 感情の英語名から日本語への変換関数
+const translateEmotion = (emotion?: string): string => {
+ if (!emotion) return "不明 ❓";
+
+ const emotionMap: Record<string, string> = {
+ HAPPY: "喜び 😄",
+ SAD: "悲しみ 😢",
+ ANGRY: "怒り 😠",
+ CONFUSED: "困惑 😕",
+ DISGUSTED: "嫌悪 🤢",
+ SURPRISED: "驚き 😲",
+ CALM: "平静 😌",
+ FEAR: "恐怖 😱",
+ UNKNOWN: "不明 ❓",
+ };
+
+ return emotionMap[emotion] || `${emotion} ❓`;
+};
export default function Home() {
const webcamRef = useRef<Webcam>(null);
const [image, setImage] = useState<string | null>(null);
+ const [isAnalyzing, setIsAnalyzing] = useState<boolean>(false);
+ const [faceAnalysisResult, setFaceAnalysisResult] = useState<FaceAnalysisResult | null>(null);
- const capture = () => {
- const imageSrc = webcamRef.current?.getScreenshot();
- if (imageSrc) {
- setImage(imageSrc);
- }
- };
+ const analyzeImage = async () => {
+ const imageSrc = webcamRef.current?.getScreenshot();
+ if (imageSrc) {
+ setImage(imageSrc);
+
+ try {
+ setIsAnalyzing(true);
+
+ const response = await fetch("/api/analyze-face", {
+ method: "POST",
+ body: JSON.stringify({ imageData: imageSrc }),
+ headers: { "Content-Type": "application/json" },
+ });
+
+ const result = await response.json();
+ setFaceAnalysisResult(result);
+ } catch (error) {
+ console.error("分析エラー:", error);
+ setFaceAnalysisResult({
+ success: false,
+ message: "エラーが発生しました",
+ });
+ } finally {
+ setIsAnalyzing(false);
+ }
+ }
+ };
return (
<div className="max-w-100 mx-auto p-4 flex flex-col items-center gap-4">
<h1 className="text-2xl font-bold">顔分析</h1>
<Webcam
className="rounded-lg"
ref={webcamRef}
screenshotFormat="image/jpeg"
/>
- <button
- className="w-full bg-green-500 hover:bg-green-600 cursor-pointer text-white px-4 py-1.5 rounded-md"
- onClick={capture}
- >
- 写真を撮る
- </button>
+ <button
+ className="w-full bg-green-500 hover:bg-green-600 cursor-pointer text-white px-4 py-1.5 rounded-md"
+ onClick={analyzeImage}
+ disabled={isAnalyzing}
+ >
+ {isAnalyzing ? "分析中..." : "顔を分析する"}
+ </button>
{image && (
<div>
<h3 className="mb-2 text-lg font-medium">撮影された写真</h3>
<Image
src={image}
alt="撮影された写真"
width={300}
height={200}
className="rounded-lg"
/>
</div>
)}
+ {faceAnalysisResult && (
+ <div className="p-4 bg-gray-100 rounded-lg text-black">
+ <h3 className="text-lg font-semibold mb-2">分析結果</h3>
+ {faceAnalysisResult.success ? (
+ <div>
+ <p>検出された顔: {faceAnalysisResult.faceCount}個 👤</p>
+ {faceAnalysisResult.faceDetails?.map((face, index) => (
+ <div
+ key={index}
+ className="mt-3 p-3 bg-white rounded shadow-sm"
+ >
+ <p>
+ 年齢: 約{face.AgeRange?.Low}~{face.AgeRange?.High}歳
+ </p>
+ <p>
+ 性別:{" "}
+ {face.Gender?.Value === "Male" ? "男性 👨" : "女性 👩"} (
+ {Math.round(face.Gender?.Confidence ?? 0)}%)
+ </p>
+ <p>
+ 感情: {translateEmotion(face.Emotions?.[0]?.Type)} (
+ {Math.round(face.Emotions?.[0]?.Confidence ?? 0)}%)
+ </p>
+ <p>笑顔: {face.Smile?.Value ? "あり 😊" : "なし 😐"}</p>
+ <p>
+ 眼鏡: {face.Eyeglasses?.Value ? "着用 👓" : "未着用 👀"}
+ </p>
+ <p>
+ サングラス:{" "}
+ {face.Sunglasses?.Value ? "着用 🕶️" : "未着用 👀"}
+ </p>
+ <p>ひげ: {face.Beard?.Value ? "あり 🧔" : "なし 🙂"}</p>
+ <p>口髭: {face.Mustache?.Value ? "あり 👨" : "なし 🙂"}</p>
+ <p>
+ 目が開いている:{" "}
+ {face.EyesOpen?.Value ? "開いている 👀" : "閉じている 😌"}
+ </p>
+ <p>
+ 口が開いている:{" "}
+ {face.MouthOpen?.Value ? "開いている 😮" : "閉じている 😶"}
+ </p>
+ </div>
+ ))}
+ </div>
+ ) : (
+ <p>{faceAnalysisResult.message}</p>
+ )}
+ </div>
+ )}
</div>
);
}
主な変更点
-
顔分析結果の型定義
-
FaceAnalysisResult型は、成功・失敗のフラグ、エラーメッセージ、顔の数、顔の詳細情報を格納します。
-
-
感情の翻訳
-
translateEmotion関数が追加され、AWS Rekognitionが返す感情(英語)を日本語に翻訳します。
-
-
画像キャプチャと分析
-
capture関数は削除され、代わりにanalyzeImage関数が画像をキャプチャして送信する処理を担当します。 -
analyzeImageでは、画像をキャプチャし、そのデータを先ほど作成したAPI (/api/analyze-face) に送信します。 - APIからのレスポンスに基づき、顔分析の結果が表示されます。
-
-
顔分析結果の表示
- 成功した場合、顔数や各顔の詳細情報(年齢、性別、感情、笑顔の有無など)が表示されます。
- 結果がない場合やエラーが発生した場合は、そのメッセージが表示されます。
顔分析結果
実装が完了したので顔画像を撮影して分析結果を表示してみます。
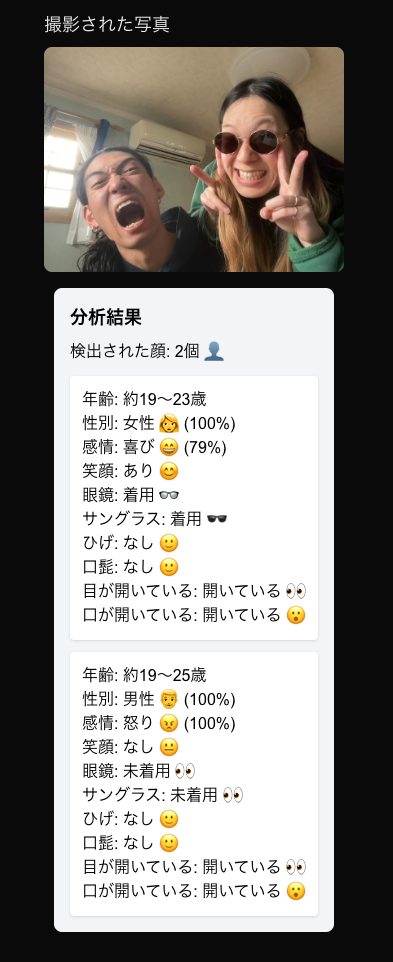
終わり!!
👇今回作成したリポジトリ
Discussion