🟰
log変換で見えてきた落とし穴──Targetの12%が“変動なし”だった話
はじめに
log変換は、株価のような桁の大きな時系列データを扱う上で、非常に有効なスケーリング手法です。
本研究でも、XGBoostモデルにおいて価格スケールの歪みを是正するために、log変換を導入しました。
しかし、logを使って予測Target(log収益率)を定義した結果、思わぬ落とし穴に遭遇したのです。
Target定義:log差による収益率
本研究では、以下のようにして翌営業日の収益率(logベース)を予測ターゲットとしました。
df["LogClose"] = np.log(df["Close"])
df["Target"] = df["LogClose"].shift(-1) - df["LogClose"]
logの性質上、これは「翌日と今日の価格比率のlog」つまりlog収益率(log return)を意味します。
この定義は金融の世界でも理論的に一般的であり、モデルが価格水準に引っ張られないようにするためにも有効です。
検証結果:0に張り付いたTargetの存在
しかし、予測の結果を観察していると、以下のように「actualが0.000000」のデータが非常に多く含まれていることに気づきました。

なぜそんなに“変動なし”なのか?
これは以下のような仮説に基づき、調査しました:
- 株価が前日とまったく同じであった
- log差が非常に小さく、浮動小数点的に0と扱われた
- スケール変換により、実質的に“平坦なデータ”が増えた
実際に調べてみた
以下のコードを使用して、Targetがほぼ0(=変動がない)と判定された行の割合を集計しました。
def calc_flat_target_ratio(self, threshold: float = 1e-4) -> float:
total_rows = 0
flat_rows = 0
for f in tqdm(self.__all_files, desc="Reransforming files"):
df = self.load(f)
if "Target" not in df.columns:
continue
df = df.dropna(subset=["Target"])
total_rows += len(df)
flat_rows += (df["Target"].abs() <= threshold).sum()
return flat_rows / total_rows if total_rows else 0.0
結果:
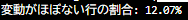
これは問題なのか?
答えは Yes and No。
- YES:この“動かないデータ”が多すぎると、モデルは「変化がないことを学習」してしまう
- NO:log差が0なのは理論的には正しい。変化がなければ収益率も0で当然。
結論と今後の対応
- log変換は正しいアプローチだが、それによって浮かび上がる実務的なデータ構造の偏りには注意が必要。
- 今後は、「変化のないデータの扱い方」にも設計方針を持つ必要がある。
まとめると…
| 発見 | log変換でTargetが0になる行が全体の約12%存在した |
|---|---|
| 背景 | 株価変動がない or log差が極小でゼロ扱い |
| 対策 | モデル学習時に除外 |
| 学び | log変換で正規性・スケール統一は実現できるが、「ゼロの山」は別問題として扱うべき |
▶ 次回予告
次回は、実際にこのflatなTargetを除外した上でモデルを再学習し、SHAP可視化にどのような違いが出たのかを分析します。
Discussion