HTML/CSSっぽい記述でPDFを作れるライブラリをRustで作る
経緯
Satoriというライブラリに感化されて、HTMLとCSSっぽい記述でPDFを作れたら面白そうと思ったので作ってみました。JavaScriptで書こうかと思いましたが、react-pdfという先人がいたので勉強を兼ねてRustで書いてみます。
どんなライブラリか
HTMLとCSSのような記述でPDFを作ることができるライブラリです。
たとえば下記のようなXMLで肉じゃがレシピのPDFが作成できます。CSSは長いため省略していますが、GitHubで確認できます。
<Document title="recipe">
<Page style="page">
<Layer style="main">
<Text style="title">肉じゃが</Text>
<Text style="description">日本の家庭でおなじみの肉じゃが。肉やじゃがいも、玉ねぎを油で炒めてから、醤油やみりんで甘煮にします。ごはんのおかずに最適です。</Text>
<Layer style="summary">
<Image style="photo" src="food" />
<Layer style="ingredients">
<Text style="summary-title">材料(2人前)</Text>
<Text style="ingredient">豚肉 ... 200g</Text>
<Text style="ingredient">じゃがいも ... 3個</Text>
<Text style="ingredient">玉ねぎ ... 1個</Text>
<Text style="ingredient">砂糖、醤油 ... おおさじ2</Text>
<Text style="ingredient">水 ... 200ml</Text>
</Layer>
</Layer>
<Layer style="steps">
<Text style="step">1. にんじんとじゃがいもは乱切りに、玉ねぎは串切りにします。</Text>
<Text style="step">2. 鍋に油を加えて豚肉を炒めます。豚肉がさっと炒まったらにんじんとじゃがいも、玉ねぎを加えて炒めます。全体に火が通ったら水と砂糖を加えます。</Text>
<Text style="step">3. 調味料を加えた後、落し蓋をして数十分間煮込みます。</Text>
<Text style="last-step">4. 汁気が無くなったら味見をして、味が染み込んでいるのを確認した後、お皿に盛り付けをして完成です。</Text>
</Layer>
</Layer>
</Page>
</Document>
生成されるPDFがこちら。文章は適当なのでレシピ通り作っても肉じゃがはできません。

どのようにPDFが作成されるのか
今回作成したライブラリが内部でどのように動作しているか紹介します。殆ど外部ライブラリを利用しているだけなので複雑なロジックはありません。大まかな流れは以下の通りです。
- 文字列で受け取ったXMLをパースしてDOMツリーのような構造体に変換
- 描画前に各要素の表示位置(座標)を計算しておく
- ルートから順に要素をPDFへ描画していく
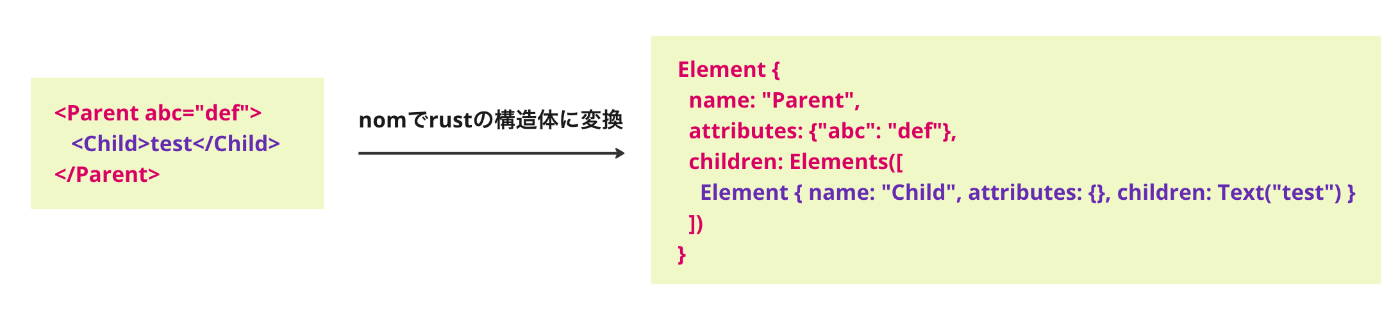
1. 文字列で受け取ったXMLをパースして構造体に変換
最初に、文字列のXMLをパースして構造体に変換します。
今回は nom を使ってパース処理を作成しました。このライブラリはXMLやDSLのような構文をパースするための「パーサコンビネータ」です。「パーサコンビネータ」では名前通り小さな「パーサ」を沢山作った上で、それらをレゴブロックのように組み合わせていき、最終的に大きな「パーサ」を作ります。下記のようなイメージです。
-
src="abc"という文字列からabcという文字列を取り出すパーサを作成。 -
<img src="abc">という文字列からimgという文字列を取り出すパーサ作成。 - 上記の 1. と 2. のパーサを使って
<img src="abc">という文字列を{ tag: "img", src: "abc" }のような構造体に変換するパーサを作成。
パーサの実装は Learning Parser Combinators With Rust の記事を参考にしました。こちらの記事ではnomは使っておらずフルスクラッチでXMLのパースを実装していますが、nomには汎用的なパーサが予め用意されているので、参考にした記事よりも楽に実装できました。nomにどのようなパーサがあるか知りたい場合は List of parsers and combinators の一覧表が便利です。
最終的に完成したコードは dom.rs(GitHub)にあります。parse関数にXMLの文字列を渡して呼び出すとパース結果がElementという構造体で帰ってきます。この構造体はDOMツリーのようにツリー構造になっています。
今回は学習目的でパーサをスクラッチしましたが、Rustにはquick-xmlというライブラリがあるため、本番でXMLを使う際は通常自作する意味はありません。
2. 描画前に各要素の表示位置を計算しておく
次にPDF上のどの座標に画像や文字を配置するかを計算します。座標計算にはtaffyというライブラリを使用しました。
これはYogaのRust版のようなもので、CSSのフレックスボックスのような形でレイアウトの構造体を渡してあげると、その要素をどこに配置するべきかをxとyの座標で返してくれます。複雑な座標計算を任せられるので楽です。
但し、座標を得るためには事前にtaffy.new_leafやらtaffy.new_with_childrenを使ってTaffyのツリー構造を作る必要があります。(ちなみにこちらの記事を拝見する限りYogaも同じAPIのようです。)
また注意点として、得られる座標はルートからの絶対座標ではなく、Yogaと同じく自分の親要素からの相対位置なので、入れ子になった要素の絶対座標を得るには親の絶対座標を加算して計算する必要があります。
今回作成したライブラリでは、1.のステップで作ったツリー構造をルート要素から順にTaffyのツリー構造に変換していきます。layout.rsというファイル内で処理しています。
3. ルートから順に要素をPDFへ描画していく
DOMツリーの構造体と座標が手に入ったので、あとはPDFに描画していきます。
今回はprintpdfというライブラリを使って実装しました。直感的なAPIで図形や文字をPDFに描画できます。
描画する際はルート要素から子要素の順にPDFへ描画していきます。描画のロジックは <Image> タグであれば image.rs、 <Text> タグであればtext.rs、という風にタグ単位で構造体に分けて管理しています。なお、使用できるタグの一覧はREADME.mdに記載しています。
履歴書を作ってみる
せっかくなのでもっと書類らしい何かを作ってみよう、ということで日本でよく見る履歴書のPDFファイルを作ってみました。実際に完成したのが下記です。

printpdfだけで作成しようとするとどうしても座標計算でコードがゴチャついてしまうのですが、taffyのおかげでCSS風に表示位置を指定することができ、少ないコードで記述することができました。コードはGitHubの方で確認できます。
課題
一通りやりたいことは実現できたのですが、いくつか課題があります。
日本語フォントを使用するとPDFが出力されるまで時間がかかる
普通に日本語フォントを使用するとPDFが出力されるまで1〜2分ほどかかります。おそらく日本語フォントのファイルサイズが大きいのが原因。若干面倒ですがサブセットフォントメーカーなどで常用漢字だけに絞れば数秒で出力できます。
文章の量から自動で高さを自動で調整してくれない
ブラウザのCSSだと、heightを指定していない場合は文章の量によって自動でボックスの高さが変わるのですが、今回作成したライブラリではまだサポートできていません。手動で横幅と高さを指定してあげる必要があります。
コードはGitHubで確認できます
本番用途で使用できるレベルまでには仕上がってないですが、GitHubで公開してみました。
今回作成したコードは全て下記のリポジトリで閲覧できます。
Discussion
これはリポジトリに含まれる examples/recipe.rs も該当しますか?
READMEに記載されている上記のように実行した際、手元の環境で33.7秒くらいかかりました
releaseビルドにした場合は0.55秒で終了しました
日本語フォントを使用すると遅くなる問題はreleaseビルドでも発生するものでしょうか?
ありがとうございます。ご指摘の通り、こちらの環境でも
--releaseフラグを付与すると短時間でビルドすることができました。具体的にどのような理由で高速化したのかまでは追えていませんが、--releaseを使用すると opt-level=3で最適化される のでこの最適化が効いているのかもしれません。