
はじめに
本稿は、音楽制作で限られた音素材から自分の求める音素材を作り出す難しさを解決するために、畳み込みニューラルネットワーク(CNN)と変分オートエンコーダ(VAE)を組み合わせた音素材モーフィングを試行するを目標にしています。
尚、この記事はGoogle Colaboratoryを用いたPythonの環境で実行しています。
提案手法
変分オートエンコーダ(VAE)と畳み込みニューラルネットワーク(CNN)を組み合わせたモデルを用います。
- VAE は生成モデルの一種であり、潜在空間を学習することで、入力音源の再構成や類似音源の生成が可能にします。
- CNN は、画像認識などの分野で高い精度を発揮するニューラルネットワークの一種であり、音源の特徴を抽出することを可能とします。
これらの手法を組み合わせることで、有限の音素材から多様な音源を生成することを可
能とします。
モーフィングの手順
モデルの学習
- 音源をフーリエ変換によってスペクトログラムに変換する。
- CNN-VAEモデルは、画像認識の分野で活用される畳み込み層を使用し、音源を低次元の潜在空間内に落とし込む。
- 逆畳み込み層を用いた後に、逆フーリエ変換で元の音源のスペクトログラムに復元する。
- この復元後のスペクトログラムが元のスペクトログラムに近づくように、CNN-VAEモデルが学習される。
CNN-VAEの概念図は下のように表しています。

モーフィング音源の生成
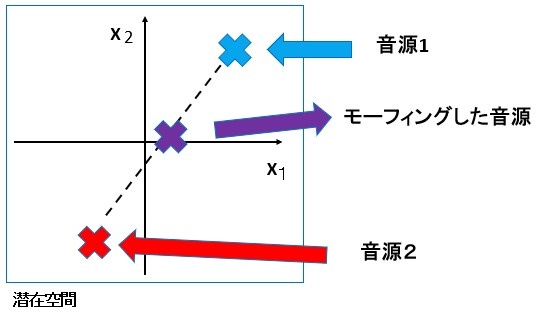
- 潜在空間に落とし込まれた音源のうち2つ選び、潜在空間上でその2つの内分点を任意の内分比で取る。
- そのようにして得られた潜在空間上の点からデコーダを通しスペクトログラムを生成し、音響信号に変換する。
潜在空間を用いたモーフィングの概念図は下のように表しています。
使用データ
本研究では, 音楽ループ素材を Wave 形式で多数収録されたデータセットとして,『Sound PooL vol. 2』を使用します。このデータセットから、ジャンルが「Techno & Trans」で楽器パートが「Drums」のものから3秒間のもの74個を抽出する。
この音源は有料であるため、使用する場合は各自で購入してください。
実際にモーフィングを行おう
モデルの構築と学習
- Google Colaboratoryを開いて準備をする
まず、はじめに使用データをダウンロードします。Googleドライブを開き、「マイドライブ」直下に「Drums」というフォルダを作り、「マイドライブ」フォルダの中に、データセットの示したWAVEデータをすべてアップロードしましょう。
新しいGoogle Colaboratoryノートブックを開きましょう。開いたら、以下のコードでGoogle
ドライブをマウントします。
from google.colab import drive
drive.mount('/content/drive')
- 例外クラス
UnsupportedWavFileExceptionという名前の例外を定義しています。例外というのは、関数実行中に何か困ったことがおきたら、処理をその関数の呼び出し側に戻すという機能です。
class UnsupportedWavFileException(Exception):
"Unsupported WAV File"
- ファイルの読み込みと短時間フーリエ変換
次に、対象となる音声ファイルを読み込み、短時間フーリエ変換を行います。以下のコードを使用します。
import glob
import librosa
import numpy as np
def load_spectrograms(dirs, winsize=2048, hopsize=None):
x_all = []
sr_all = []
S_all = []
if hopsize is None:
hopsize = int(winsize / 4)
for directory in dirs:
files = glob.glob(directory + "/*.wav")
for i, f in enumerate(files):
try:
y, sr = librosa.load(f)
sr_all.append(sr)
D = librosa.stft(y, n_fft=winsize, win_length=winsize, hop_length=hopsize)
S, phase = librosa.magphase(D)
x_all.append(np.expand_dims(S, axis=-1))
S_all.append(np.abs(D))
print(i, f, len(S_all) - 1)
except:
print("skip")
x_train = np.asarray(x_all)
return x_train, sr_all, S_all
-
上記関数load_spectrogramsは、指定されたディレクトリ内のすべての.wavファイルに対して以下の処理を行います
-
winsize でフーリエ変換の窓サイズを指定し、hopsize で窓をずらすサイズを指定します。
-
librosa.load()関数を使用して、音声ファイルを読み込みます。読み込んだ波形データはyに、サンプリングレートはsrに格納されます。
-
librosa.stft()関数を使用して、短時間フーリエ変換を行います。その際、n_fftは窓サイズ(winsize)を、win_lengthは窓の長さ(winsize)を、hop_lengthは窓をずらすサイズ(hopsize)を指定します。変換結果はDに格納されます。
-
librosa.magphase()関数を使用して、フーリエ変換結果Dから強度情報Sと位相情報phaseを取得します。
-
取得したスペクトログラムデータをx_allに追加し、その際のインデックスとファイル名を表示します。これは、後の処理で音源を特定する際に利用します。
続いて、複数のディレクトリに保存されている音声データを読み込みます。
dirs = [
"/content/drive/MyDrive/Drums"
]
x_train, sr_all, original_S = load_spectrograms(dirs)
このコードを実行すると、各音源のファイル名とその配列の添え字が表示されます。これにより、複数のディレクトリから音声データを効率的に読み込み、短時間フーリエ変換を行うことができます。
- 事前分布の準備
この事前分布は、潜在空間のベクトルが生成される際に参照され、モデルの学習や生成における制約となります。正規分布を用いることで、モデルが一定の範囲内での滑らかな表現を学習することが期待されます。
import tensorflow as tf
import tensorflow_probability as tfp
encoded_dim=16
tfd = tfp.distributions
prior = tfd.Independent(
tfd.Normal(loc=tf.zeros(encoded_dim), scale=1),
reinterpreted_batch_ndims=1)
上記プログラムの内容は以下の通りです
- encoded_dimという変数に16が代入されています。これは潜在空間の次元数を表しています。
- priorという変数に、潜在空間の事前分布を定義します。事前分布は一般に、モデルに対して「だいたいこの辺に集まってくれ」というゆるやかな制約を与えるために使用されます。
- tfd.Normal関数を使用して正規分布を作成します。locパラメータには、平均を表すtf.zeros(encoded_dim)を指定しています。これによって、正規分布の平均が0に設定されます。scaleパラメータには、標準偏差を表す1を指定しています。
- 畳み込み層
エンコーダの畳み込み層は、入力データの周波数軸と時間軸の情報を抽出するために使用されます。
seq_length = x_train.shape[2]
input_dim = x_train.shape[1]
hidden_dim=256
encoder = tf.keras.Sequential()
encoder.add(tf.keras.layers.Conv2D(hidden_dim, (input_dim,1),
input_shape=(input_dim,seq_length, 1),
strides=1, padding="valid",
activation="relu"))
encoder.add(tf.keras.layers.Conv2D(hidden_dim, (1,37), strides=( 1,37),
padding="valid", activation="relu"))
encoder.add(tf.keras.layers.Conv2D(hidden_dim, (1,4), strides=(1,4),
padding="valid", activation="relu"))
encoder.add(tf.keras.layers.Flatten())
encoder.add(tf.keras.layers.Dense(
tfp.layers.MultivariateNormalTriL.params_size(encoded_dim),
activation=None))
encoder.add(tfp.layers.MultivariateNormalTriL(
encoded_dim,
activity_regularizer=tfp.layers.KLDivergenceRegularizer(
prior, weight=0.001)))
encoder.summary()
上記プログラムの内容は以下の通りです
- input_dimは入力データの周波数軸の要素数1025、seq_lengthは時間軸の要素数148を取得します。
- 畳み込み層では、入力データの周波数軸方向に対して1次元のフィルタを適用します。フィルタのサイズは(input_dim, 1)です。最初の畳み込み層では、入力データの周波数軸方向の要素数を1025から1に変換します。これにより、音高軸方向の情報を圧縮し、重要な特徴を抽出します。
次に、2つの畳み込み層が時間軸方向の要素数を変換します。1つ目の畳み込み層では、時間軸の要素数を148から4に変換し、2つ目の畳み込み層では、4から1に変換します。 - input_shapeは入力データの形状を指定します。(input_dim, seq_length, 1)となっており、入力データの次元数、時間軸の要素数、チャンネル数を表しています。
- stridesはフィルタの移動量を指定します。ここでは1となっており、フィルタを1つずつ移動させながら畳み込み演算を行います。
- activationは活性化関数を指定します。ここではReLU関数が使用されています。
- Flatten()層を使用することで、CNNの出力をフラットな形状に変換します。つまり、空間的な次元を持たず、すべての要素が1次元の配列となります。
- encoder.summary()を呼び出すことで、エンコーダのモデル構造とパラメータ数の要約を表示します。
このモデルは、3秒の音源を前提しています。それ以外はフィルタの構成を変える必要があります。
- 逆畳み込み層
デコーダの逆畳み込み層は、潜在空間のベクトルを元の入力データの形状に戻すために使用されます。
decoder = tf.keras.Sequential()
decoder.add(tf.keras.layers.Dense(hidden_dim, input_dim=encoded_dim,
activation="relu"))
decoder.add(tf.keras.layers.Reshape((1, 1, hidden_dim)))
decoder.add(tf.keras.layers.Conv2DTranspose( hidden_dim, (1,4), strides=(1,4), padding="valid", activation="relu"))
decoder.add(tf.keras.layers.Conv2DTranspose( hidden_dim, (1,37), strides=(1,37), padding="valid", activation="relu"))
decoder.add(tf.keras.layers.Conv2DTranspose( 1, (input_dim,1), strides=1, padding="valid", activation="relu"))
decoder.summary()
上記プログラムの内容は以下の通りです
- Dense層を使用して、潜在空間のベクトルを1024次元のベクトルに変換します。
- Reshape層を使用して、1次元のベクトルを2次元の行列(2次元配列)に変換します。この層では、目的の形状として(1, 1, hidden_dim)を指定し、出力の形状を変更します。この行列は後続の逆畳み込み層に入力されます。
- 3つの逆畳み込み層(Conv2DTranspose)によって、入力データの形状を徐々に拡大して元の形状に戻す役割を果たします。最初の逆畳み込み層では、時間軸方向の要素数を1から4に変換します。次の逆畳み込み層では、時間軸方向の要素数を4から148に変換します。最後の逆畳み込み層では、周波数軸方向の要素数を1から1025に変換します。これにより、1次元のベクトルが周波数軸×時間軸の2次元配列に復元されます。

上はCNN で行われるスペクトルの構造です。右矢印が畳み込み層、左矢印が逆畳み込み層。
- モデルの構築、読み込み、そして学習
ここでは、既存のモデルの重みを読み込み、さらに学習を進める手法について説明します。
from keras.callbacks import ModelCheckpoint
import os
os.makedirs('drive/MyDrive/vae_model', exist_ok=True)
vae = tf.keras.Model(encoder.inputs, decoder(encoder.outputs))
weight_path = '/content/drive/MyDrive/vae_model/model.h5'
if os.path.exists(weight_path):
vae.load_weights(weight_path)
vae.compile(optimizer="adam", loss="mse", metrics="mse")
model_checkpoint = ModelCheckpoint(
filepath=os.path.join('drive/MyDrive/vae_model', 'model.h5'),
monitor='loss',
save_best_only=True,
verbose=1)
history = vae.fit(x_train, x_train, epochs=500, batch_size=16, callbacks=[model_checkpoint])
上記プログラムの内容は以下の通りです
- 必要なライブラリとモジュールをインポートします。
- 指定されたディレクトリ('drive/MyDrive/vae_model')を作成します。既にディレクトリが存在する場合は、新たに作成することはありません。
- tf.keras.Model関数を使用して、エンコーダの入力とデコーダの出力を結びつけ、VAEモデルを構築します。
- もし既存のモデルの重みが存在する場合、vae.load_weightsメソッドでこれを読み込みます。これにより、前回の学習状態を維持してさらなる学習を進めることができます。
- compileメソッドを使用して、モデルをコンパイルします。ここでも"adam"オプティマイザと"mse"損失関数を使用します。
- ModelCheckpointコールバックを使用して、学習中のモデルの重みを定期的に保存します。このコールバックは、学習中の損失値が改善した場合にのみモデルの重みを更新し、保存します。こうすることで、最良のモデルの重みだけを保存することができます。
- fitメソッドを使用してモデルの学習を行います。この際、ModelCheckpointコールバックを指定して、学習中にモデルの重みを保存します。
このプロセスでは、前回の学習結果を基に、VAEモデルをさらに学習させることができます。また、学習途中のモデルの状態を保存し、後で読み込むことができるため、途中からの学習再開も容易になります。
- 学習済みVAEモデルの読み込みとセットアップ
このセクションでは、先に学習させたVAEモデルの重みを読み込み、新たにデータを予測や追加の学習に使用する準備を行います。
from keras.callbacks import ModelCheckpoint
import os
os.makedirs('drive/MyDrive/vae_model', exist_ok=True)
vae = tf.keras.Model(encoder.inputs, decoder(encoder.outputs))
vae.load_weights('/content/drive/MyDrive/vae_model/model.h5')
vae.compile(optimizer="adam", loss="mse", metrics="mse")
上記プログラムの内容は以下の通りです
- 必要なライブラリとモジュールをインポートします。
- os.makedirsを使用して、指定されたディレクトリ('drive/MyDrive/vae_model')を作成します。このディレクトリは、モデルの重みが保存される場所です。もしディレクトリが既に存在する場合、新たに作成することはありません。
- tf.keras.Model関数を使用して、エンコーダの入力とデコーダの出力を結びつけて、VAEモデルを構築します。
- load_weightsメソッドを使用して、学習済みのモデルの重みを読み込みます。これにより、以前の学習結果を持ったモデルを利用することができます。
- 最後に、compileメソッドを使用して、モデルをコンパイルします。ここでは"adam"オプティマイザと"mse"損失関数を使用しています。
この手順により、以前に学習させたVAEモデルの重みを読み込み、そのモデルを新たなデータに適用する準備が完了します。次のステップでは、この学習済みモデルを用いてデータの予測や追加の学習を行うことができます。
- モデルの精度を評価する
evaluate というメソッドによって学習済みVAEモデルを使用して訓練データセットを評価する操作です。
具体的には、入力データとしてx_trainを与え、VAEモデルによって生成された出力データと入力データとの間の損失(MSE)と評価指標(MSE)を計算します。
評価結果は、損失と評価指標の値からなるリストとして返されます。損失は、モデルが訓練データに対してどれだけ予測の誤差を持っているかを示す指標であり、評価指標はモデルの性能を示す指標です。値が小さいほど、モデルの予測や性能が良いことを示します。
vae.evaluate(x_train,x_train)
- モデルの再構築性能の評価
ディープラーニングモデルを利用したデータの再構築タスクでは、オートエンコーダやVAE(変分オートエンコーダ)などのアーキテクチャが一般的に利用されます。これらのモデルの主な目的は、入力データを潜在空間にエンコードし、そのエンコードされた情報から元のデータをできるだけ忠実にデコード(再構築)することです。
モデルがどれだけ再構築をうまく行っているかを評価するための指標として、「コサイン類似度」が利用されることがあります。コサイン類似度は、2つのベクトルの方向性がどれだけ似ているかを評価する指標で、0(ベクトルが直交する場合)から1(完全に同じ方向)の範囲の値を取ります。
以下の手続きは、オリジナルのスペクトログラム original_S(「実際にモーフィングを行おう/モデルの構築と学習/3. ファイルの読み込みと短時間フーリエ変換」で取得したスペクトログラム情報)と、モデルによって再構築されたスペクトログラム re_spec の間のコサイン類似度を計算するものです。
まず、学習済みのエンコーダーモデルを使用して、入力データセットx_trainを潜在空間にエンコードします。
z = encoder.predict(x_train)
ここで、zは、x_trainの各データポイントに対応する潜在空間のベクトルを含むNumPy配列となります。次に、この潜在空間のベクトルzをデコーダを使用して再構築します。
def decode_spectrograms(encoder, decoder, z):
re_spec = []
for i in range(len(z)):
try:
d = decoder.predict(np.array([z[i]]))
re_spec.append(np.squeeze(d))
except UnsupportedWavFileException:
print("Skip")
return re_spec
re_spec = decode_spectrograms(encoder, decoder, z)
得られた再構築されたスペクトログラムre_specとオリジナルのスペクトログラムoriginal_Sの間でコサイン類似度を計算します。
similarities = []
for i in range(len(original_S)):
s1 = original_S[i]
s2 = re_spec[i]
cosine_similarity = np.dot(s1.flatten(), s2.flatten()) / (np.linalg.norm(s1) * np.linalg.norm(s2))
similarities.append(cosine_similarity)
print(i)
print("類似度: ", cosine_similarity)
- decode_spectrograms関数は、与えられた潜在変数zをデコードして再構築されたスペクトログラムを返します。
- その後、オリジナルのスペクトログラムと再構築されたスペクトログラムのコサイン類似度を計算して、similaritiesリストに保存します。
- 最後に、各スペクトログラムに対する類似度が出力されます。
この方法を利用することで、モデルがどれだけデータの再構築を適切に行っているか、すなわち、再構築されたデータがオリジナルのデータにどれだけ近いかを定量的に評価することができます。
モーフィング音源の生成
- 潜在ベクトルの組み合わせ
次のコードは、2つの潜在空間のベクトルを合成し、デコーダを利用して音声を再生するものです。
import IPython
a = 0.5
i = 指定した音源数字
j = 指定した音源数字
my_x = decoder.predict(np.array([z[i]])*a + np.array([z[j]])* (1-a))
my_x = np.squeeze(my_x)
指定する音源iおよびjのインデックスは、「実際にモーフィングを行おう/モデルの構築と学習/3. ファイルの読み込みと短時間フーリエ変換 」において出力される音源名をその添え字を利用する。
具体的には、学習済みの音源から 2 つ(si, sj とする)選び,それらの潜在空間上の座標を zi, zj とする.このとき,ziとzjを α : 1 − α に内分する点を znew = (1 − α)zi + αzj とす
る.α を適当に決めて znew を求めた上で VAE のデコーダを実行することで, si と sj の中間的なスペクトログラムを生成する.一方の復元した音源を聴きたい場合、αを0、もしくは1にする。
- 逆畳み込みによる音声合成
生成された音声データ(my_x)を逆変換してオーディオ信号を復元する。
import matplotlib.pyplot as plt
winsize = 2048
hopsize = int(winsize/4)
y_inv = librosa.griffinlim(my_x, n_iter=32, win_length=winsize, hop_length=hopsize)
print(y_inv)
plt.matshow(my_x)
上記のプログラムの内容は以下の通りです。
- librosaライブラリのgriffinlim関数を使用して、my_xをスペクトログラムに変換し、そのスペクトログラムを逆変換してオーディオ信号を復元します。
- win_lengthとhop_lengthはウィンドウサイズとホップサイズを指定します。最終的に復元されたオーディオ信号はy_invという変数に格納され、出力されます。
これを実行するとモーフィン後のスペクトログラムが出力されます
- 再生された音声の表示
逆畳み込みによって復元された音声データy_invが再生され、再構築された音声がオーディオプレーヤーで聴くことができます。
IPython.display.display(IPython.display.Audio(y_inv, rate=sr_all[0]))
以下にOverkill J.wav とKaputnik Beat R.wavをモーフィングした場合をスペクトログラムにする。以下のように Overkill J.wav からKaputnik Beat R.wavへとモーフィングできました。

おわりに
実際にモーフィングしたドラム音源は聴けたでしょうか。一方に偏りがあったり、両者のどちらとも異なる新たな音源が生成される場合もあります。まだまだ、改善の余地はありますがぜひ参考にしてみてください。
本稿は授業で配布された資料の一部を許可のもと流用して作成しました。
Discussion