Kindle購入書籍をCSVで保存する
結論・やり方
Kindle for PCもしくはKindle for Macを使っているユーザーが対象。
このユーザーはローカルに自動でKindleSyncMetadataCache.xmlという XML ファイルが生成されているため、これを parse してに CSV を生成する。
環境
他の環境は知らない。多分動く。
❯ node -v
v16.13.2
❯ npm -v
8.1.2
❯ yarn -v
1.22.17
準備
git clone git@github.com:ktanoooo/kindle_csv.git
yarn
実行
run.sh実行時にxmlのパスと文字コードを引数に入れる必要あり。
-
xmlのパス- は Windows ユーザーは
{yourname}のところにユーザー名を入れ変えれば動くはず。。。Mac ユーザーはそのまま使えるはず。
- は Windows ユーザーは
-
文字コード- こちらが対応。
# Windows
/bin/bash run.sh /Users/{yourname}/AppData/Local/Amazon/Kindle/Cache/KindleSyncMetadataCache.xml Shift_JIS
# Windows (WSL)
/bin/bash run.sh /mnt/c/Users/{yourname}/AppData/Local/Amazon/Kindle/Cache/KindleSyncMetadataCache.xml Shift_JIS
# Mac (Kindle for MacをAppStoreでインストールした人)
/bin/bash run.sh $HOME/Library/Containers/com.amazon.Kindle/Data/Library/Application Support/Kindle/Cache/KindleSyncMetadataCache.xml Shift_JIS
# Mac (Kindle for MacをAppStore以外でインストールした人)
/bin/bash run.sh $HOME/Library/Application Support/Kindle/Cache/KindleSyncMetadataCache.xml Shift_JIS
正常に完了すれば./output/kindle-**.csvが生成される。
なぜ
技術系の雑誌や技術書は現物一択だと思っていたが、恥ずかしながら最近 Kindle の目次機能を知って Kindle 信者になった。
おかげで冊数が増えてきて CSV で一覧管理がしたかったが、以下の記事が古くて使えなかったので自分で作ることにした。
ここのコメント欄でKindle for PC,Kindle for MacではKindleSyncMetadataCache.xmlが吐かれているということを教えてくれてたのでこれを使う。
XML の取得
KindleSyncMetadataCache.xmlがどこにあるのかをまず整理しないといけない。
Windows の人はKindle for PC, Mac の人はKindle for Macというのをインストールして使用していることが前提になるが、カスタマイズしていなければデフォルトで大体以下のパスに自動生成されているはず。
- Windows
/Users/{yourname}/AppData/Local/Amazon/Kindle/Cache/KindleSyncMetadataCache.xml
- Windows(WSL)
/mnt/c/Users/{yourname}/AppData/Local/Amazon/Kindle/Cache/KindleSyncMetadataCache.xml
- Mac(Kindle for Mac を AppStore 経由でインストール)
$HOME/Library/Containers/com.amazon.Kindle/Data/Library/Application Support/Kindle/Cache/KindleSyncMetadataCache.xml
- Mac(Kindle for Mac を AppStore 以外でインストール)
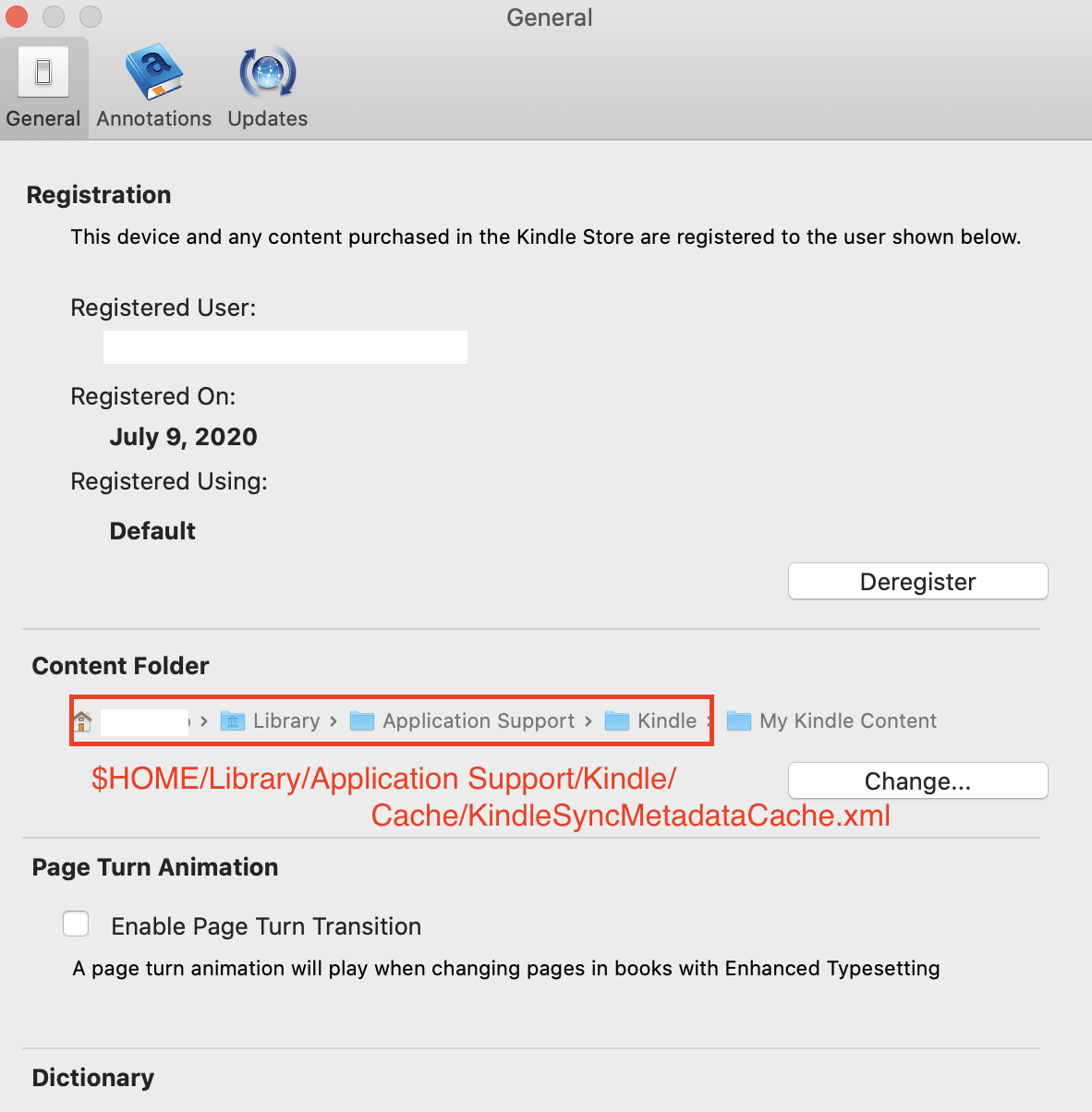
$HOME/Library/Application Support/Kindle/Cache/KindleSyncMetadataCache.xml
Mac の人は以下のようにKindle for Macを開いてPreferences→Content Folderから確認ができる
XML を parse
無事 xml のパスが分かればそれを parse して CSV に直せばよい。
fast-xml-parserを使ってみたかったのでパッケージの力を借りて node で実行することにする。
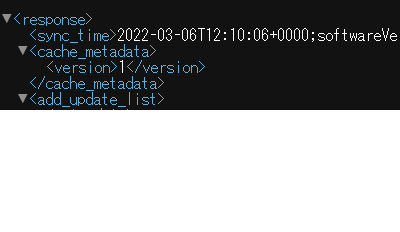
XMLファイルは以下のような HTML みたいな構造になっていて parse することでオブジェクトに直して扱いやすくしてくれる。
<response>
<sync_time>
2022-03-05T16:25:37+0000;softwareVersion:000000;***************-000000000000,Periodical-0000000000000,KB-00000000000000,
</sync_time>
<cache_metadata>
<version>1</version>
</cache_metadata>
<add_update_list>
<meta_data>...</meta_data>
</add_update_lsit>
</response>
{
response: {
sync_time: '2022-03-05T16:25:37+0000;softwareVersion:000000;***************-000000000000,Periodical-0000000000000,KB-00000000000000,',
cache_metadata: { version: 1 },
add_update_list: { meta_data: [Array] }
}
}
実際の parse 処理は以下。
outputに上記のようなオブジェクトが入る。購入した書籍ではないデータも含まれていたため、filterで購入日付のあるデータのみに絞り込んでいる。
const FastXMLParser = require("fast-xml-parser");
const parser = new FastXMLParser.XMLParser({ ignoreAttributes: false });
const output = parser.parse(text);
let purchasedData = output.response.add_update_list.meta_data.filter(
(e) => !!e.purchase_date
);
CSV データを作る
オブジェクトにしてしまえばあとはループ回して csv の形に整えていくだけ。
書籍のデータとして取れるのは以下のデータ
{
ASIN: 'B0000000',
title: {
'#text': 'Book name',
'@_pronunciation': 'Book name'
},
authors: { author: { '#text': 'author name', '@_pronunciation': '' } },
publishers: { publisher: 'publisher name' },
publication_date: '2010-04-01T00:00:00+0000',
purchase_date: '2019-01-01T00:00:00+0000',
textbook_type: 'unknown',
cde_contenttype: 'EBOK',
content_type: 'application/x-mobipocket-ebook'
}
いらないデータもあるので今回 CSV に落とし込むのはasin, title, author, publisher, publication_date, purchase_dateに絞ることにする。
asinは書籍の uniq id みたいなもの。
実際の処理はこれ。normalize()は文字列に", ,が含まれてても大丈夫なように加工する処理。
const normalize = (str) => `"${str.replaceAll('"', "'")}"`;
const create_csv_data = (datas) => {
let csvData = "";
const header = [
"asin",
"title",
"author",
"publisher",
"publication_date",
"purchase_date",
];
csvData += header.join() + "\n";
datas.forEach((data) => {
const {
ASIN: asin,
title: { "#text": titleText },
authors: {
author: { "#text": authorText },
},
publishers: { publisher },
publication_date,
purchase_date,
} = data;
csvData +=
[asin, titleText, authorText, publisher, publication_date, purchase_date]
.map((e) => normalize(e))
.join(",") + "\n";
});
return csvData;
};
CSV ファイル出力
特に必要なかったがついでにutf8以外の文字コードにも対応した。
エンコードにはiconv-liteを使う。
対応している文字コード一覧はこちら
実際に処理を実行するときに未対応の不適切な文字コードを指定するとエラーになるので、判定するために毎回 curl でデータを取得してencodings_list.jsonに保存するようにした。雑だけど頻繁に実行するものでもないしこれでいいかなと思ってそのまま。
const fs = require("fs");
const path = require("path");
const iconv = require("iconv-lite");
const export_csv = (outputpath, data, charset) => {
const list = fs.readFileSync(
path.resolve(__dirname, "encodings_list.json"),
"utf8"
);
if (list.includes(charset)) {
fs.writeFile(outputpath, iconv.encode(data, charset), (err) => {
if (err) throw err;
});
}
};
Discussion