🙇
DL論文読みまとめ: ResNet(2015)

ResNet (2015)
問題意識
- ConvNetの層の数を増やすことでネットワークが抽出できる特徴量をリッチになり、画像認識や物体検出のタスクの精度が向上してきた。
- しかし、従来のDeep ConvNetの構造では、Conv層の数を増加させると逆に精度が低下していく ”degratdation” という問題が観察されており、層の数を増やすことによる精度向上には限界が見えてきていた。
- 過学習ではvalidation dataにおける精度低下が観察されるが、”degradation”ではtrain dataの精度が低下してしまう。
- → ResNetでは、”degratdation” を引き起こさずにどうやって層を深くしていくか、ということが主要な問題意識。
提案手法
ResNetのアイデア

-
レイヤー間にidentity mappingを導入することにより、 ネットワークにResidual Representationを学習させるようにすることで、従来手法では不可能だった152層もの深いネットワークの学習を可能にした。
- 入力データをx、学習を行いたいmapingをH(x)とすると、ネットワークにはその入力データとその残差F(x) (= H(x) - x)のmappingを学習させるようにする。
- 上記のように学習させることで、レイヤーを多数積み重ねた際に、もしそのレイヤーが不必要なのであれば、レイヤーのパラメタを0に近づけることで、単なるidentity mappingにすることが可能になる。
- → それによって浅いネットワークにレイヤーを重ねて深くした場合、精度は必ず同じかそれ以上になることが保証されることになる。
- もし深いレイヤーが不必要ならば、レイヤーのパタメタが0になり、単なるidentity mappingになるため。
- 原理的には、identity mappingが存在しなくても最適化によって、レイヤーのパラメタが0になるような学習は可能だが、現実的には難しい。
ResNetの構造
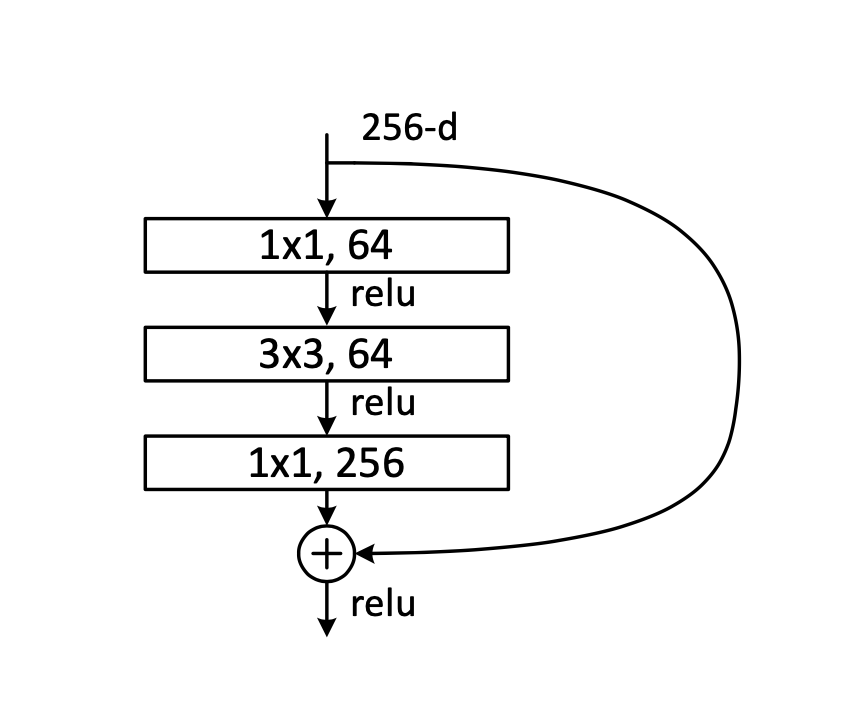
- ResNetは上記のような構造を持った”bottleneck”という構造を積み重ねて作成される。
- 入力としては、256channelの特徴量マップが投入され、それに対して1x1のカーネルを64個適用させて、channel数を64まで削減させる。その後、1x1のカーネルを256個適用させて256channelに戻すような構造になっている。
- 256⇨64⇨64⇨256
- 上記のような構造は、3x3のカーネルに入力されるchannel数を削減したいという意図を持っている。
結果
- それまでは不可能だった152層もの深いネットワークでの学習が可能になり、それらの深いネットワークを組み入れたアンサンブルモデルで、2015年のLSVRCとCOCOの画像認識系のcompetitionで1位を総なめにした。
Discussion