[survey]Learning a logistic model from aggregated data


メモ代わりなので悪しからず。(言い訳)
論文情報
タイトル: Learning a logistic model from aggregated data
著者: Alexandre Gilotte et al (Criteo)
出自: AdKDD 2021
どのような研究か(要約)
プライバシー保護の観点から従来学習に利用していたデータを取得し続けることは難しくなることが予想されており、生データではなくAggregated Data(生データに対し各種統計処理がかけられたデータ、集約データ)からモデルを学習する必要がある。しかし従来の教師あり学習を集約データに直接適応することは難しいため、代替する方法を検討する必要がある。
本研究では、従来の教師あり学習ではなくMRFを用いた確率モデルを適用することで集約データから直接学習する手法を提案した。
また、上記MRFによる学習は生データに対し多項式カーネルを用いたロジスティック回帰を学習することと同等であることを示し、最終的に提案手法が生データに対するロジスティック回帰に近しい精度であることを実験的に示した
問題設定
生データの各行(特徴ベクトル)とラベルを、
ここで
つまり
参考画像は以下。
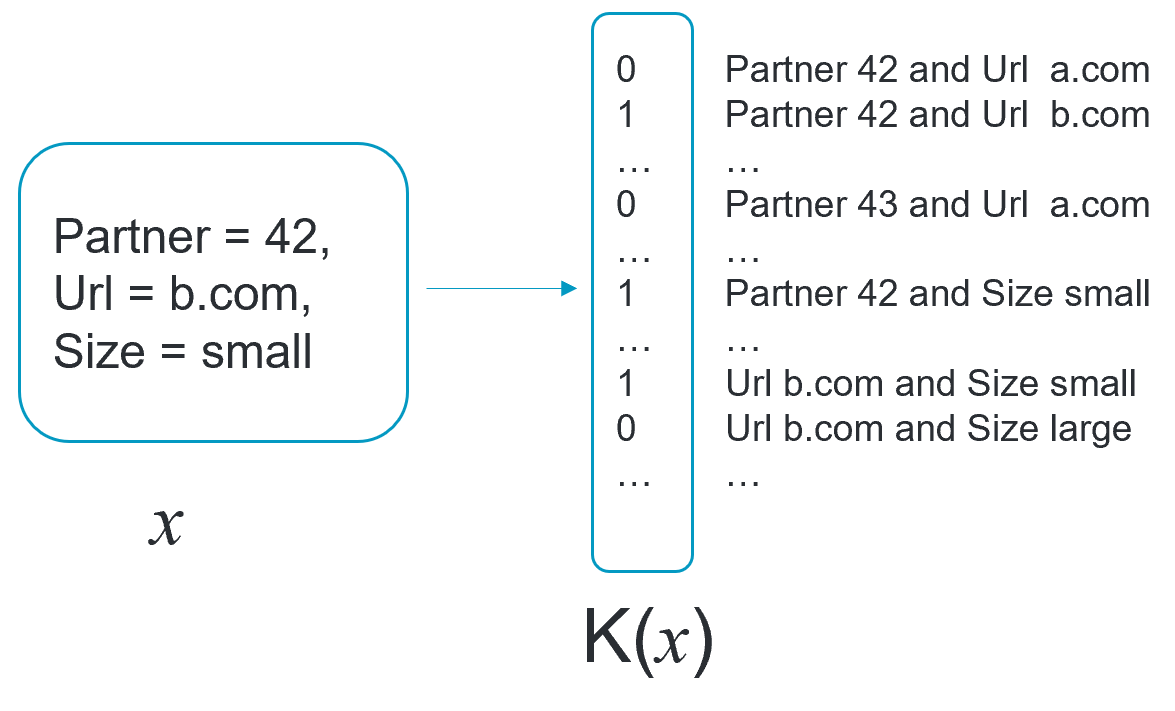
そして本論文における"集約データ"は以下で定義する。
ここで
こうして得られた集約データからどうやってモデルを構築するか、というのが本論文の問題になる。
提案手法
本論文では上記集約データを入力都市、
ここで
- MRFはマルコフ性を仮定する生成的確率モデルであり、無向グラフで表現される。ノイズ除去等によく利用される。
そして条件付分布は以下で求められる。
ここで
実験結果
以下のモデルで検証を行い比較する。(和訳していないのはさぼり)
-
LR2 -
LR -
MRF -
NB
また、指標は以下である。(値が大きい方が望ましい)
上記設定で比較実験を行った結果は以下。
| Model | NLLH train set |
NLLH validation |
best L2 parameter |
run time |
|---|---|---|---|---|
| LR2 | 0.0991 | 0.0907 | 50.0 | |
| LR | 0.0769 | 0.0757 | 8.0 | |
| MRF (50k samples) |
0.0712 | 0.0681 | 400.0 | |
| MRF (400k samples) |
0.0899 | 0.0869 | 400.0 |
提案手法がただのロジスティック回帰に勝利している点が確認できている。また、最もよい多項式カーネルロジスティック回帰に匹敵する精度が出ている。しかし他モデルと比較して学習時間が長い点が見て取れる。
所感
- 情報量が少なくなっているデータで学習したモデルが、生データで学習するレベルと同等に近い精度が出せているのはすごい
- 数式展開がきれい
- ロジスティック回帰はこの分野だと未だに現役
- さすがに時間かかりすぎでは?まだ実用には乏しい気がする
- 集約のやり方って他にどんな方法があるのか、連続値に対してはどうする?その辺に新しい課題ないか?
Discussion