Prometheus と Alertmanager によるモニタリングシステム入門
Prometheus と Alertmanager によるモニタリングシステム入門
Prometheus と Alertmanager を活用したモニタリングシステムを Docker(Compose) コンテナ上に構築します。
Prometheus の公式サイトでは、Prometheus とその周辺エコシステムとの関係が以下の通り図示されています。
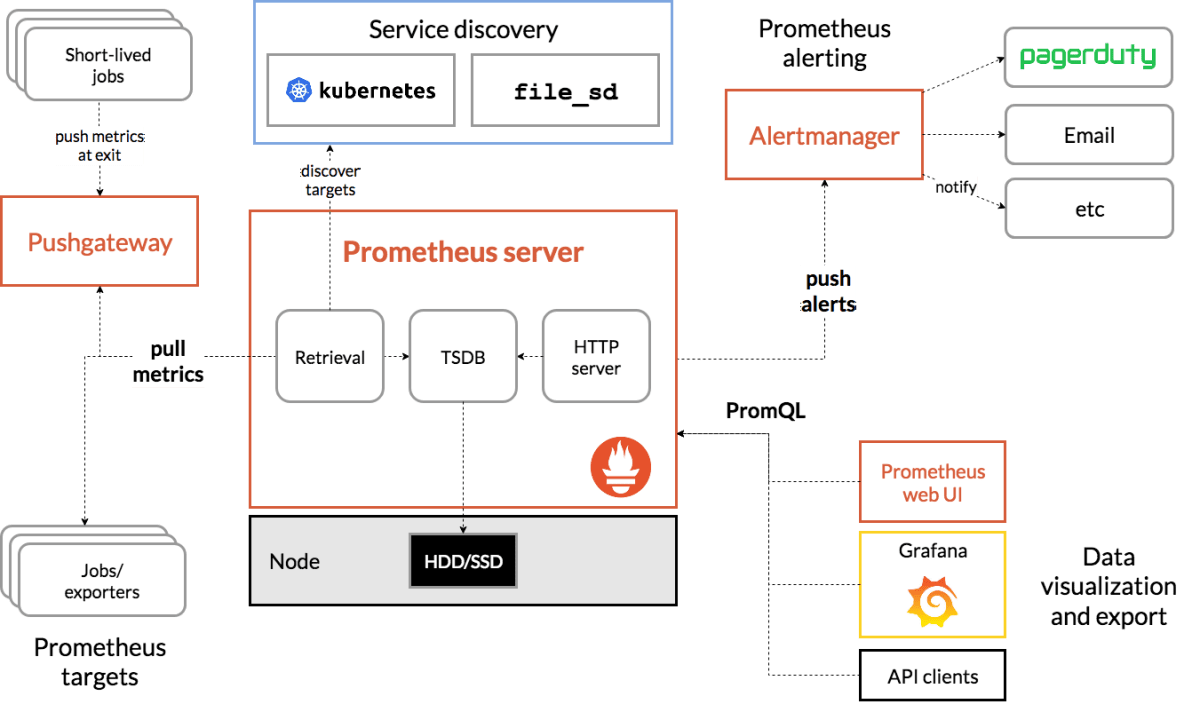
今回は上図における「exporter からメトリクスを pull する」と「Alertmanager にアラートを発報する」部分について簡単なハンズオンをしてみます。
使用した各サービスは以下のとおりです。
- Prometheus: 定期的にターゲット(exporter)をポーリングしてリソース情報を収集し、自サービス内の DB に保持します
- Alertmanager: Prometheus 等のクライアントから発報されたアラートをハンドリングします。今回は slack の Incoming webhook を使って slack の特定 channel に通知します。
- Node Exporter: ハードウェア、OS のメトリクスを提供します。
本稿で作成したコードはすべて以下のリポジトリにまとめてありますので、ご自由にお使いください。Pull Request 等も歓迎です。
Prometheus
Docker Compose の Prometheus のサービス定義は以下の通りです。
/etc/prometheus 以下に設定ファイルが配置されているので、ローカルファイルをマウントすることで設定値を反映させます。
ローカルホスト側でバインドするポート番号は ${PROMETHEUS_PORT} で変数指定できます。
起動後、http://localhost:${PROMETHEUS_PORT}/config から現在反映されている設定を確認できます。
services:
prometheus:
image: prom/prometheus:v2.25.0
container_name: prometheus
ports:
- ${PROMETHEUS_PORT}:9090
volumes:
- ./docker/prometheus:/etc/prometheus
networks:
- shared-network
Prometheus は Pull 型アプローチを採ったモニタリングツールです。
scrape_configs で指定した監視対象のホストに対して scrape_interval で設定した間隔でスクレイプします。
アラートのルールは rule_files にて指定できます(後述)。
global:
scrape_interval: 15s
evaluation_interval: 15s
alerting:
alertmanagers:
- static_configs:
- targets:
- alertmanager:9093
rule_files:
- "alertmanager_rules.yml"
scrape_configs:
- job_name: 'prometheus'
static_configs:
- targets:
- prometheus:9090
- job_name: 'node-exporter'
static_configs:
- targets:
- node-exporter:9100
発報のルールを以下の通り定義しました。
- 監視対象のターゲットと通信できない状態が 5 分以上継続
- API 呼び出しのレイテンシの中央値が 1 秒以上の状態が 10 分以上継続
groups:
- name: example
rules:
- alert: InstanceDown
expr: up == 0
for: 5m
labels:
severity: page
annotations:
summary: "Instance {{ $labels.instance }} down"
description: "{{ $labels.instance }} of job {{ $labels.job }} has been down for more than 5 minutes."
- alert: APIHighRequestLatency
expr: api_http_request_latencies_second{quantile="0.5"} > 1
for: 10m
annotations:
summary: "High request latency on {{ $labels.instance }}"
description: "{{ $labels.instance }} has a median request latency above 1s (current value: {{ $value }}s)"
Alertmanager
/etc/alertmanager/alertmanager.yml に設定ファイルが配置されているので、ローカルファイルをマウントすることで設定値を反映させています。
ゼロから作成してもよいですが、デフォルト状態で起動してコンテナ内に入って設定値を確認し、必要な項目だけ書き換えるとかだと作業が早いです。
サービス起動後、http://localhost:${ALERTMANAGER_PORT}/#/statusにアクセスすると現在の設定値が確認できます。
services:
alertmanager:
image: prom/alertmanager:v0.21.0
container_name: alertmanager
ports:
- ${ALERTMANAGER_PORT}:9093
privileged: true
volumes:
- ./docker/alertmanager/alertmanager.yml:/etc/alertmanager/alertmanager.yml
networks:
- shared-network
Alertmanager が発報を受けてどうハンドリングするかを定義します。
ここでは Slack の Incoming webhook を使って、指定した slack channel にメッセージを投稿します。
slack_api_url で Incoming webhook で作成した URL を設定します。
global:
resolve_timeout: 5m
# set your incoming webhook url for slack
slack_api_url: 'https://hooks.slack.com/services/XXXXXXXXX/XXXXXXXXXXX/XXXXXXXXXXXXXXXXXXXXXXXX'
route:
group_by: ['alertname', 'datacenter', 'app']
group_wait: 10s
group_interval: 10s
repeat_interval: 1h
receiver: 'slack-notifications'
receivers:
- name: 'slack-notifications'
slack_configs:
- channel: '#alerts'
text: 'https://prometheus.io/docs/alerting/latest/notification_examples/#customizing-slack-notifications'
Node Exporter
サービスが実行されている Node の各種メトリクスを提供するサーバを構築します。
/metrics にアクセスすると Prometheus が解釈可能なフォーマットで出力されたメトリクスがざっと取得できます。
services:
node-exporter:
image: prom/node-exporter:v1.1.2
container_name: node-exporter
ports:
- ${NODE_EXPORTER_PORT}:9100
networks:
- shared-network
動作確認
以下の手順で適切にモニタリングシステムが稼働しているかを確認しました。
# リポジトリの clone
git clone https://github.com/ks6088ts/example-monitoring-system.git
cd example-monitoring-system
# .env file をリポジトリルートに作成
cp .env.sample .env
# Docker network を作成
docker network create shared-network
# slack_api_url を書き換え
# 手早く確認できるように、`alertmanager_rules` で指定した判定条件を `for: 5s` 等に差し替え
# サービスを起動
docker-compose up -d
# Node Exporter を停止
docker-compose stop node-exporter
Node Exporter を停止させてしばらく経つと slack channel にアラートが飛びました。
めでたし。めでたし。
Discussion