【Isaac Sim × Isaac Lab入門】#4 カメラからRGB・法線・セグメンテーション画像を取得する
以下の記事にて、Isaac Sim内の、オブジェクトの座標を取得することができた。
今回はPart4として、公式サイトを参考に、
- Isaac Simに設置したカメラの映像から、画像を取得する
ことを試してみる。
この記事の内容を実施すると、以下のように「RGB画像」「法線画像」「インスタンスセグメンテーション画像」を取得することができる。
| RGB | 法線 | インスタンスセグメンテーション |
|---|---|---|
 |
 |
 |
法線画像とは?
法線画像は、3Dモデルの法線ベクトル(=表面の向き、XYZの値)を、画像(RGB)として書き込んだもの。法線画像を使用することで、低ポリゴンで、光の反射具合を計算することができる。
例えば航空機にボルトや溝を作る場合、実際にその形状を作って配置することも一つの手段ではあるが、ボルトの数が増えるとポリゴン数も増加し、描画に負荷がかかる。
そこで、平面(低ポリゴン)に法線画像を貼り付けることで、ボルトなどのポリゴンを実際に用意しなくても、凹凸や傷の部分を立体的に見せることができる。
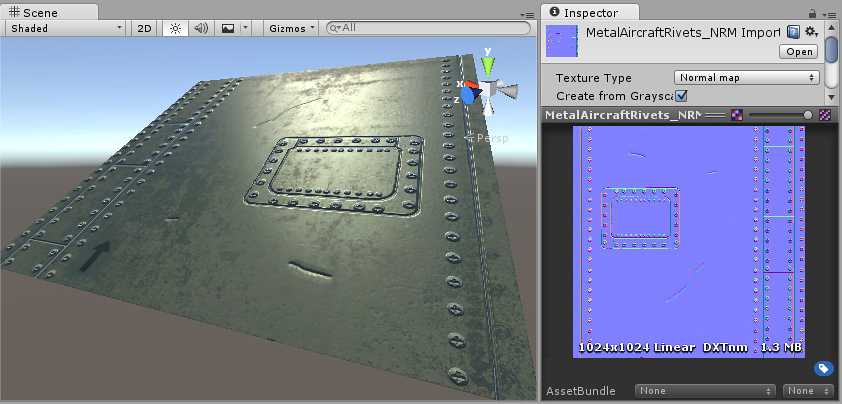
ただし、今回取得できる法線画像は、カメラから見た視点における法線情報であり、一般的な法線マップ(テクスチャとしてオブジェクトに貼る用途のもの)とは異なる。そのため、この画像を直接3Dモデルのマテリアルに適用することはできない点に注意。
インスタンスセグメンテーションとは
画像の画素1ピクセルずつに、ラベルを付与した画像。
同じクラスであっても、別々のオブジェクトとしてラベル付けされる。
例えば、映像中に「タイヤA」「タイヤB」が存在する場合、別個のオブジェクトとして、個別に色が付けられる。
手順
手順1. Pythonスクリプトの作成
前回までの手順と同様に、C:\Users\{ユーザ名}\work\python_scriptsディレクトリの中に、camera_capture.pyというPythonスクリプトを作成する。
C:\Users\{ユーザ名}\work\
├─ IsaacLab
└─ python_scripts
└─ create_empty_scene.py
└─ create_object.py
└─ get_object_transform.py
└─ camera_capture.py
そしてcamera_capture.pyの中に、以下のコードを貼り付ける。
今回のコード
import argparse
from isaaclab.app import AppLauncher
# ステップ0. 引数を受け取る
parser = argparse.ArgumentParser(description="This script demonstrates how to use the camera sensor.")
AppLauncher.add_app_launcher_args(parser)
args_cli = parser.parse_args()
# ステップ1. シミュレータの起動
app_launcher = AppLauncher(args_cli)
simulation_app = app_launcher.app
# ステップ2. Isaac Simやその他のモジュールをインポート
import os
import torch
import isaacsim.core.utils.prims as prim_utils
import omni.replicator.core as rep
import isaaclab.sim as sim_utils
from isaaclab.assets import RigidObject, RigidObjectCfg
from isaaclab.sensors.camera import Camera, CameraCfg
from isaaclab.utils import convert_dict_to_backend
def define_sensor() -> Camera:
"""
カメラセンサーを作成する関数。
data_types によって、センサーの出力形式を設定する。設定可能な値は以下:
- `rgb`: カラー画像(3チャンネル)
- `rgba`: αチャンネル付きのカラー画像
- `distance_to_camera`: カメラの光学中心までの深度画像
- `distance_to_image_plane`: カメラのZ軸に沿ったカメラ平面からの深度画像
- `depth`: `distance_to_image_plane`と同じ
- `normals`: 法線画像
- `motion_vectors`: 各ピクセルの動きベクトルデータの画像
- `semantic_segmentation`: セマンティックセグメンテーション画像
- `instance_segmentation_fast`: インスタンスセグメンテーション画像
- `instance_id_segmentation_fast`:インスタンスIDセグメンテーション画像
Returns:
カメラオブジェクト(1つ or 複数)
"""
# カメラの位置・回転情報を保存するためのXformオブジェクトを作成
prim_utils.create_prim("/World/Origin_00", "Xform")
prim_utils.create_prim("/World/Origin_01", "Xform")
# Xformオブジェクトの配下に、カメラを配置
camera_cfg = CameraCfg(
prim_path="/World/Origin_.*/CameraSensor",
update_period=0,
height=480,
width=640,
data_types=[
"rgb",
"normals",
"instance_segmentation_fast",
],
colorize_semantic_segmentation=True,
colorize_instance_id_segmentation=True,
colorize_instance_segmentation=True,
spawn=sim_utils.PinholeCameraCfg(
focal_length=24.0, focus_distance=400.0, horizontal_aperture=20.955, clipping_range=(0.1, 1.0e5)
),
)
# カメラを作成
camera = Camera(cfg=camera_cfg)
return camera
def create_scene() -> dict:
"""環境の準備"""
# 地面を配置
cfg_ground = sim_utils.GroundPlaneCfg()
cfg_ground.func("/World/defaultGroundPlane", cfg_ground)
# ライトを配置
cfg_light_distant = sim_utils.DistantLightCfg(
intensity=3000.0,
color=(0.75, 0.75, 0.75),
)
cfg_light_distant.func("/World/lightDistant", cfg_light_distant, translation=(1, 0, 10))
# Rigid Bodyの位置情報を格納する用の、Xformオブジェクトを作成
origin = [[0, 0, 2]]
prim_utils.create_prim("/World/Object", "Xform", translation=origin)
# Xformオブジェクトの配下に、Rigid Bodyを付与した直方体を配置
cuboid_cfg = RigidObjectCfg(
prim_path="/World/Object/Cuboid",
spawn=sim_utils.CuboidCfg(
size=(0.5, 0.5, 0.5),
rigid_props=sim_utils.RigidBodyPropertiesCfg(rigid_body_enabled=True),
mass_props=sim_utils.MassPropertiesCfg(mass=1.0),
collision_props=sim_utils.CollisionPropertiesCfg(),
visual_material=sim_utils.PreviewSurfaceCfg(diffuse_color=(0.0, 1.0, 0.0)),
semantic_tags=[("class", "Cube")],
),
init_state=RigidObjectCfg.InitialStateCfg(),
)
cuboid_object = RigidObject(cfg=cuboid_cfg)
# カメラの作成
camera = define_sensor()
# シーンの情報を辞書に登録
scene_entities = {}
scene_entities["rigid_object"] = cuboid_object
scene_entities["camera"] = camera
return scene_entities
def save_images(camera: Camera, camera_index:int, rep_writer: rep.BasicWriter):
"""
カメラがレンダリングする映像を、画像として保存する。
"""
# カメラに映る映像をnumpy型に変換する。
# data_typeにはセンサーの出力形式(rgb, distance_to_image_plane等)、tensorには画素値が格納される。
single_cam_data = convert_dict_to_backend(
{data_type: tensor[camera_index] for data_type, tensor in camera.data.output.items()}, backend="numpy"
)
# 追加情報を抽出。センサーの出力にセマンティック形式が含まれる場合、アノテーション情報が格納されているため必須。
# rgb形式などのセマンティック形式以外の場合、None。
single_cam_info = camera.data.info[camera_index]
# rep_writerに格納できる形に成形
rep_output = {"annotators": {}}
for key, data, info in zip(single_cam_data.keys(), single_cam_data.values(), single_cam_info.values()):
if info is not None:
rep_output["annotators"][key] = {"render_product": {"data": data, **info}}
else:
rep_output["annotators"][key] = {"render_product": {"data": data}}
# 画像を保存
rep_output["trigger_outputs"] = {"on_time": camera.frame[camera_index]}
rep_writer.write(rep_output)
def run_simulator(sim: sim_utils.SimulationContext, scene_entities: dict):
"""シミュレーションの実行"""
camera: Camera = scene_entities["camera"]
# データの出力先ディレクトリを指定
output_dir = os.path.join(os.path.dirname(os.path.realpath(__file__)), "output", "camera")
# すべてのカメラの位置と注視点を設定
camera_positions = torch.tensor([[2.5, 2.5, 2.5], [-2.5, -2.5, 2.5]], device=sim.device)
camera_targets = torch.tensor([[0.0, 0.0, 0.0], [0.0, 0.0, 0.0]], device=sim.device)
camera.set_world_poses_from_view(camera_positions, camera_targets)
# 画像をnumpy形式で保存するためのクラス(Omniverse Replicator)を呼び出し
rep_writer = rep.BasicWriter(
output_dir=output_dir,
frame_padding=0,
colorize_instance_id_segmentation=camera.cfg.colorize_instance_id_segmentation,
colorize_instance_segmentation=camera.cfg.colorize_instance_segmentation,
colorize_semantic_segmentation=camera.cfg.colorize_semantic_segmentation,
bounding_box_2d_tight=True,
)
# シミュレーションのステップ数を制限
num_step = 0
# オブジェクトの投影と映像データの出力
while simulation_app.is_running():
print(f"simulation step: {num_step}")
# 100ステップ経過したら終了
if num_step >= 100:
break
# シミュレーションを1ステップ進める
sim.step()
# カメラのレンダリングを、1ステップ進めた後の値に更新
camera.update(dt=sim.get_physics_dt())
# 0番目のカメラに関する画像を保存。
save_images(camera=camera, camera_index=0, rep_writer=rep_writer)
# 1番目のカメラに関する画像を保存。
save_images(camera=camera, camera_index=1, rep_writer=rep_writer)
num_step += 1
# ステップ3. シミュレーションコンテキストの設定
sim_cfg = sim_utils.SimulationCfg(device=args_cli.device)
sim = sim_utils.SimulationContext(sim_cfg)
# ステップ4. ビューポートを映すカメラの位置・注視点を設定
sim.set_camera_view(eye=[2.5, 2.5, 2.5], target=[0.0, 0.0, 0.0])
# ステップ5. 地面、ライト、直方体、カメラをシーンに配置
scene_entities = create_scene()
# ステップ6. シミュレーションの実行
sim.reset()
run_simulator(sim, scene_entities)
# ステップ7. シミュレーションを終了
simulation_app.close()
このコードは、公式のコードを参考に、ステップが分かりやすくなるように整理したものである。
手順2. 実行前の事前準備
Isaac SimとIsaac Labを実行する事前作業として、パスを通す。
コマンドプロンプト上で、以下を実行する。
cd C:\Users\{ユーザ名}\work\IsaacLab
set ISAACSIM_PATH="C:/isaacsim"
set ISAACSIM_PYTHON_EXE="%ISAACSIM_PATH:"=%\python.bat"
isaaclab.bat --install
手順3. 実行
コマンドプロンプト上で、以下を実行する。
なお、カメラセンサーを利用する場合は引数に--enable_camerasが必要。
isaaclab.bat -p ..\python_scripts\camera_capture.py --enable_cameras --headless
isaaclab.bat -p ..\python_scripts\camera_capture.py --enable_cameras
実行が成功すると、100ステップのシミュレーションが実行され、2台のカメラについて、それぞれ以下のような「RGB画像」、「法線画像」「インスタンスセグメンテーション画像」がpython_scripts/output/cameraディレクトリに格納される。
| RGB | 法線 | インスタンスセグメンテーション |
|---|---|---|
|
|
|
また、インスタンスセグメンテーションに関しては、以下のようなjsonファイルが作成される。
{
"(0, 0, 0, 0)": {"class": "BACKGROUND"},
"(0, 0, 0, 255)": {"class": "UNLABELLED"},
"(255, 25, 25, 255)": {"class": "cube"}
}
"(255, 25, 25, 255)"部分はRGBA値であり、画像内でcubeクラスの領域(画像中の赤い部分)を示す。
"(0, 0, 0, 255)": {"class": "UNLABELLED"}は、平面オブジェクト(ただしラベルがないためUNLABELLED)の領域を表す。
これらの情報を使うことで、色でオブジェクトの部分をフィルターして使用することができる。
シミュレーションを終了するときは、
- コマンドプロンプトで「Ctrl+C」を押す
- シミュレータ画面を「×ボタン」で消す
のどちらかを実行する。
所感
今回はPythonスクリプトによって、「RGB画像」と「法線画像」「インスタンスセグメンテーション画像」を取得することができた。
良かった点として、画像を作成するためのAPIがすでに整っており、ロジックを自力で書かなくても「インスタンスセグメンテーション画像」のような、AI向けのデータを取得できることが価値として感じられた。
一方で、シミュレーションごとに環境を作る必要があることは、使いづらく感じた。
例えば「事前に3D環境を用意して、そのうえで人を歩かせる」ことなどを行う場合、環境内で人をどう配置し、どう動かすかをコードですべて記載するのは難しく、現時点では、Isaac Sim × Isaac Labで同様のシミュレーションを実現するのは難しいと感じた。
Next Action
最終目標としては、PLATEAUのような3D環境を用意し、そのうえで人を歩かせるようなシミュレーションを行いたい。
ただし、Isaac Sim × Isaac Labで行う場合、環境と人の動きをすべてコードで記載する必要があり、実現は厳しいと感じられたため、回避策や別の手段を検討する。
(理想的には、Isaac Simで環境を作り、そのうえでPythonコードを実行できる形が望ましい)
Discussion