和歌の Bag of Words作成 (python)
この記事は古川研究室 AdventCalendar 7日目の記事です.
本記事は古川研究室の学生が学習の一環として書いたものです.
内容が曖昧であったり表現が多少異なったりする場合があります.
まえがき
雷神(なるかみ)の 少し響(とよ)みて さし曇り 雨もふらぬか 君を留めむ
どうも,新海誠作品が大好きな一般学生です.上の歌は「言の葉の庭」の劇中にでてきた和歌であり,万葉集からの出典です.
「雷が少し鳴って、曇って、そして雨なんか降ってくれないかなあ・・あなたを留めるために」
という恋文です.この歌は女性が歌って,その返歌として,柿本人麻呂が,
「雷が少し鳴って、雨が降らなくても,君がここにいてくれと思ってくれるのであれば(一緒にいるよ)」
と返します[1].
・・・
和歌の解析がしたくなってきましたね.この記事は八代集のBoWの作成を目的にしています.
データセット
解析といってもそもそも和歌のデータセットがなければ始まりません.
和歌のデータセットを探していたところ東工大の山元先生が熱心に和歌の解析[2]のみならず,和歌関係のオープンソースデータセットの整備も熱心に取り組まれております.この論文に書いてある八代集データセットはこちらになり,データセットの解析用のGithubはこちらになります.
八代集とは勅撰和歌集[3](天皇や上皇の命により編纂された歌集)21集のうち,最初の8集《古今和歌集》《後撰和歌集》《拾遺和歌集》《後拾遺和歌集》《金葉和歌集》《詞花和歌集》《千載和歌集》《新古今和歌集》です.師曰く,この和歌集は歌が特に盛んなころのものらしいです.(これ以降は歌の文化は盛り下がったらしいです)
特徴量抽出方針
テキストから特徴量を抽出するといえば Bag of Words(BoW)です.(一般にはDoc2Vec等のDeep特徴量が考えられますが今回は和歌なので保留)
BoWは文章ごとの単語頻出度数を特徴量にしたデータです.
以下の様なドキュメント[4]からは,例えば下の表の様な特徴量になります.
Doc1: The white-beard pirates are a pack of cowards
Doc2: White-Beard is a loser from a bygone era
Doc3: take that back !! huff take back what you said
| Doc | white-beard | a | cowards | loser | take | back |
|---|---|---|---|---|---|---|
| Doc1 | 1 | 1 | 1 | 0 | 0 | 0 |
| Doc2 | 1 | 1 | 0 | 1 | 0 | 0 |
| Doc3 | 0 | 0 | 0 | 0 | 2 | 2 |
データ整形
hachidaishu.dbをpandasのDataFrame(DF)に落とし込んで扱いやすい形にします.
このデータ整形の作業をするにあたっては,サンプルコード様が非常に優秀で,どの様な解析をしていくにしても,DataclassのHachidaishuDBをそのまま使うのがいいと思います.そして,pandasのDFに変更するコードもサンプルコードから頂戴します.
ただし,どの選集かの情報を表すためのEnumだけはIntEnumの型に変更します.これはのちにPandasのgroupbyの機能を使うときに怒られない様にするためです.
- from enum import Enum
+ from enum import IntEnum
- Anthology = Enum('Anthology', 'Kokinshu Gosenshu Shuishu Goshuishu Kin’yoshu Shikashu Senzaishu Shinkokinshu')
+ Anthology = IntEnum('Anthology', 'Kokinshu Gosenshu Shuishu Goshuishu Kin’yoshu Shikashu Senzaishu Shinkokinshu')
...
db = HachidaishuDB()
import pandas as pd
dfp = pd.DataFrame.from_records(db.query(), columns=db.columns())
この結果のdfpは以下の様な歌にでてくる単語(形態素)にまつわるDFなります.
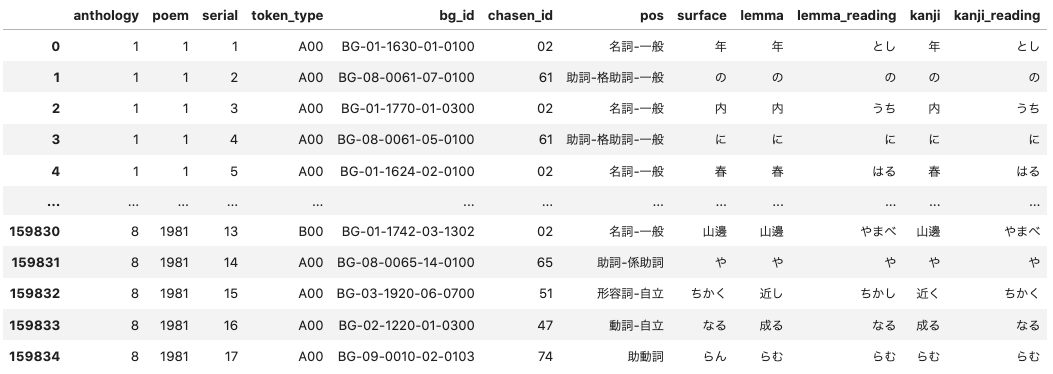
dfp
それぞれ簡単にコメントします.(全てGithubやサンプルコード内に正しい説明はありますが,日本語の説明はなく,少なからず需要はあると思うので素人ながらコメントします.)
| 列 | 列名 | コメント |
|---|---|---|
| 1 | anthology | どの勅撰和歌集かを示す |
| 2 | poem | その勅撰和歌集の何番目の歌なのかを示す |
| 3 | serial | その歌の何番目かの単語かを示す |
| 4 | token_type | その単語の種類を示す.(単一で意味を持つ単語か複数の単語が組み合わさって意味をもつか等)サンプルコード内に説明あり |
| 5 | bg_id | 分類語彙表(WLSP)に沿ってつけられたIDで,単語が持つ意味を示す.例:春(BG-01-1624-02-0100)-> 1.1624 に着目.1.1(部門ID): 関係,1.16(中項目ID)時間,1.1624(分類項目ID):季節.02-0100は分類語彙表DBにおけるID. |
| 6 | chasen_id | 形態素解析システム「Chasen」で使われている単語の品詞を示したID.サンプルコードに説明あり |
| 7 | pos | 上のchasen_idを日本語で示したもの.05のchasen_idは '名詞-固有名詞-人名', |
| 8 | surface | 歌に出てくるままの単語の表記 |
| 9 | lemma | 漢字表記の字句を示します |
| 10 | lemma_reading | かな表記の字句を示す |
| 11 | kanji | 漢字の活用形を示す |
| 12 | kanji_reading | かなの活用形を示す |
Make DataFrame BoW
ここからはこちらの自然言語処理の前処理の記事を参考に前処理を行なっていきます.
①単語のクリーニング
これは元データがすでにきれいなので省略します
② 単語の分割 品詞選出
動詞・形容詞・名詞に絞ってBoWを作ります.
# make_new_attribution
dfp['pos_1'] = dfp.pos.apply(lambda s: s.split('-')[0])
# selected
dfp_noun_adjective_verb = dfp.query('pos_1 in ["名詞", "形容詞", "動詞"]')
dfp_nav = dfp_noun_adjective_verb
③単語の正規化
文字種の統一
こちらも元データがすでにきれいなので省略します
数字の置き換え
今回は,数字が意味を持つ様な気がしているので,置き換えません.
辞書を用いた単語の統一
同じ意味をもつものを統一します.例えば,「刈る」という動詞は色々な活用系があります."刈ら", "刈り", "刈る", "刈れ"で検索してみると,
dfp.query('kanji in ["刈ら", "刈り", "刈る", "刈れ"]')[:30]

["刈ら", "刈り", "刈る", "刈れ"]
以上の様になります.どれもbg_idは一緒なので意味は一緒です.また,lemmaのほうの「刈る」というので統一されていますので."刈ら", "刈り", "刈る", "刈れ"の単語はlemmaの単語の「刈る」に置き換えます.
④ストップワードの除去
ストップワードというのは自然言語処理する際に一般的で役に立たない等の理由で処理対象外とする単語のことです。
辞書による方式
和歌のストップワードは知られていないのでできません.品詞選出で助詞を取り除いているのがこれに当たるかもしれません.
出現頻度による方式
俗にいうTF-IDFです.
③④を反映して,歌ごとのDFを作成すると次の様になります.
df_bow = dfp_nav.groupby(['anthology', 'poem'])['lemma'].agg(' '.join)
df_bows = pd.DataFrame(df_bow)
df_bows['surface'] = dfp.groupby(['anthology', 'poem'])['surface'].agg(' '.join)
df_bows = df_bows.reset_index()

df_bows
surfaceは元の歌ですね.lemmaにBoWにする前の分かち書き状態のテキストが入っています.これをskleranのCountVectorizerとTfidfTransformerを使ってBoW化します.
from sklearn.feature_extraction.text import CountVectorizer
from sklearn.feature_extraction.text import TfidfTransformer
import numpy as np
# cv = CountVectorizer(max_df=50, min_df=3)
cv = CountVectorizer()
feature_sparse = cv.fit_transform(df_bows["lemma"])
# Tfidf
tfidf_transformer = TfidfTransformer(norm='l2', sublinear_tf=True)
feature_sparse = tfidf_transformer.fit_transform(feature_sparse)
features = np.array(feature_sparse.todense())
print(features.shape[0],"が歌数",features.shape[1],"が単語数")
cv.get_feature_names()[:]
9499 が歌数 3194 が単語数
'あから目', 'あし絹', 'あなじ', 'あらまし', 'あらまほし', 'いさよふ', 'いとほし', 'いひ', 'うき', 'うたた寝', 'うつる', 'うらびる', 'おほけなし', 'おぼめく', 'かけ嶋', 'かす', 'かほやが沼', 'がまし', 'けふの細布', 'こふ', 'さいたづま', 'さがにくし', 'さくさめの刀自', 'さす', 'さび江', 'さぶ', 'さ牡鹿', 'さ雄鹿', 'しけ糸', 'しだく',...
となりました.
Easy analysis
頻出度数が高い単語から表示してみます.(これはTF-IDFかけておりません)
A=np.argsort(np.sum(features, axis=0))[::-1]
print(A[0:20])
print(np.argmax(np.sum(features, axis=0)))
for i in A:
print(cv.get_feature_names()[i], np.sum(features, axis=0)[i])
思ふ 1832
見る 1473
無し 1198
有り 1198
知る 780
立つ 646
行く 636
逢ふ 536
成る 534
見ゆ 495
鳴く 449
恋ふ 445
言ふ 425
散る 416
待つ 405
降る 383
出づ 378
吹く 378
聞く 375
動詞が上位ですねー.「恋ふ」という動詞はどう使うんでしょうか・・・わたし,気になります!
というところで今回はここらで終わりになりますが,実際の研究はここからスタートです.
皆様も和歌を解析して,想いがつのる相手に対して,自分の気持ちを伝える昔の人の技術を見てみてはいかがでしょうか.
和歌にもルールがあって,それを知ると定石がわかって読み方が広がります.ルールを知るには,こちらの本がおすすめです.
それでは.
雷神(なるかみ)の 少し響(とよ)みて ふらずとも 吾は留らむ 妹し留めば
Discussion