web3 analysis data pipeline Study
web3に集まってくるデータを、AIで分析するサービスが増えてくるという話をよく聞きます。
では具体的にそのようなシステムを作るとするとどのような要素が必要で、システムアーキテクチャはどのようなものになるのか? 先行事例を調査してみたいとおもいます。
Node / block explorer
web3上にデプロイするプログラムを開発する、NFTを購入したときなどblock explorerを頻繁に確認します。block explorer なしでは何が起きているか、ただしく取引が成立したのかを調べるのも一苦労です。
block chainでは、取引履歴がblock chainを構成している各ノードに書き込まれ、それが正当なものだと検証されることでデータ(block)が保存されます。
なので、自分でNodeを立ち上げればblock explorer に頼らずともデータが把握できるはずです。
(注:台帳(ledger)ベースのbitcoin, ethereum の場合。Objectベースだと前提が変わります)
Ethereumのノードは下記2種類が存在します
-
FullNode
- ノードは直近の128 block のみを保存する
- 検証に参加する
- minimum requirement SSD: 1TB(blocksize 変動する)
-
ArchiveNode
- Genesisからの全Block情報を保存する
- 検証には参加しなくてもよい
- 2023/5月でのmiimum requirement SSD: 13.5TB(ひたすら増えていく)
(参考) https://www.quicknode.com/guides/infrastructure/node-setup/ethereum-full-node-vs-archive-node
基本的にweb3 analysis を行うのであれば自分でNodeを構築することは必須になってくると想定しています。ただし、下記のブログでも記事にもありますが、zkproof の技術などを応用して今後はBlockに書き込まれるデータ自体が暗号化されていて 簡単には解読できない、 個人の利用許諾があった場合のみに参照できるようにするなど、個人情報保護と、データ利用の透明性の担保が必須になってくるので、単純にNodeを立てるだけでは不十分になってくると思われます。
Data Hub
Block chain 上に書き込みが発生したとき、 監視対象のweb3 プログラムからイベントが発生したときなど、処理のタイミングは大量に発生しますので 処理をCueing する仕組みが求められます。このあたりはweb3とは直接関係ないのでお好きなものをという感じです。
- Kafka
ChainAlysisというSaaSでは 下記のような構成でKafkaをk8s上で構築し対応しているようです。

(参考:https://www.chainalysis.com/wp-content/uploads/2023/05/privacy-and-security-white-paper.pdf)
- Kinesis Data Firehose
AWSでは KinesisDataFirehoseをつかうパターン
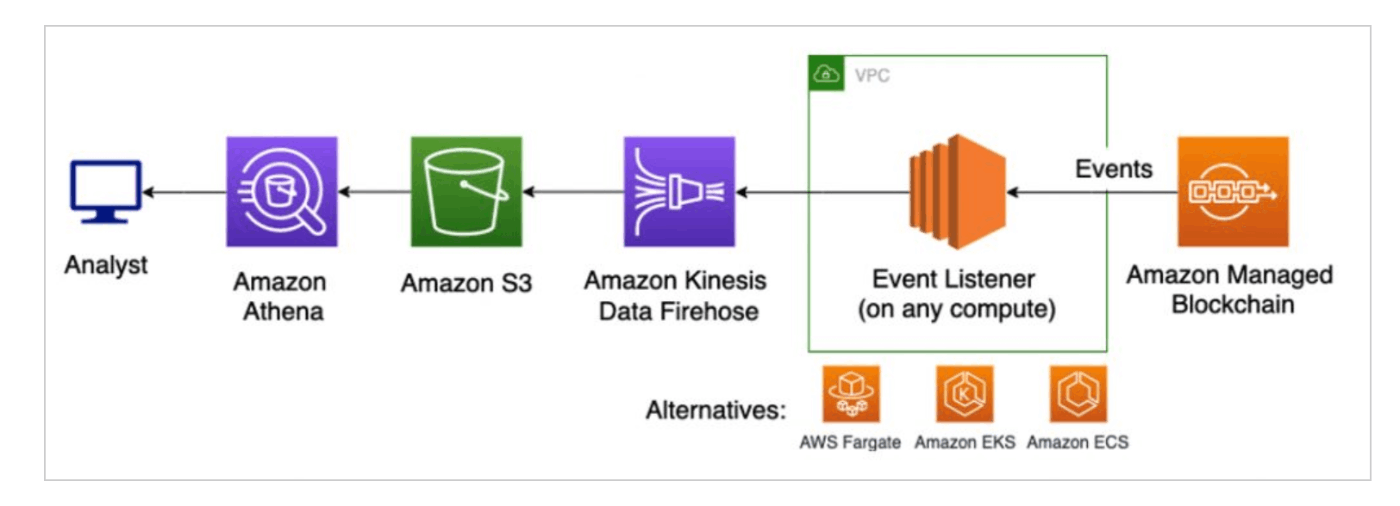
(参考:https://aws.amazon.com/jp/blogs/database/performing-analytics-on-amazon-managed-blockchain/)
- EventGrid, ServiceBus
Azureでは EventGridや、ServiceBusをつかうパターン
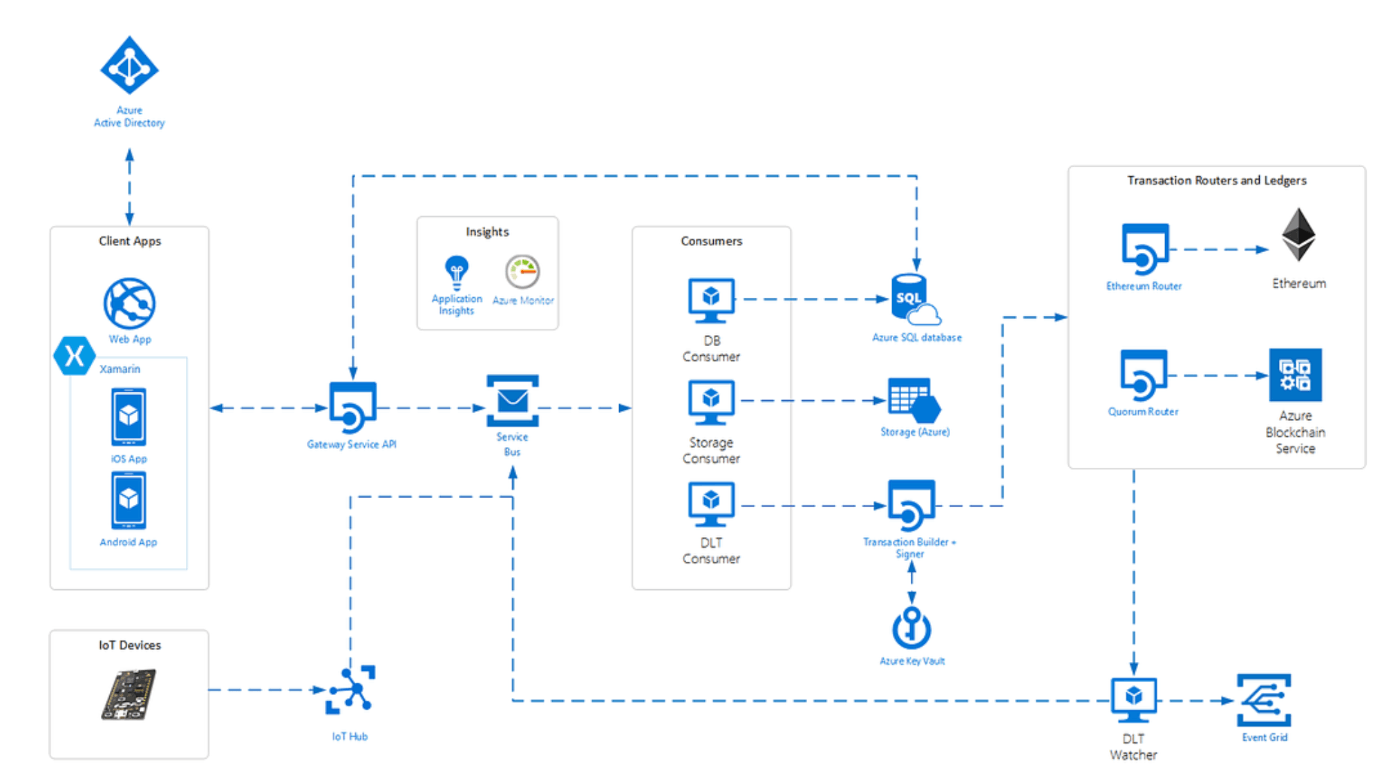
(参考:https://hashhub-research.com/articles/2020-10-21-microsoft-blockchain-services-02)
DB
最初は下記のような時系列DB(InFlux,TimeScaleDB)が適しているのかなともおもいましたが、よく考えてみると構造や関連をたどりたくなるケースがおおく、かつ10TB以上の大量のデータになりますので CloudNativeのManagedDBもしくは列指向DB(Cassandra,HBase)が向いていると思います。
時系列DB: https://db-engines.com/en/ranking_trend/time+series+dbms
列指向DB: https://db-engines.com/en/ranking_trend/wide+column+store
AWS: https://aws.amazon.com/jp/nosql/columnar/
GCP: https://cloud.google.com/bigquery
System Arch
基本的な仕組みとしては下記のサイトで紹介されているものと似たようなフローになると思います。

(参考:https://bcc-munich.com/insight/report-block-explorer/)
あとは何を解析したいか次第で Analysis 部分は個別につくっていくことになるでしょう。
例えばわかり易い例として Bitcoinの価格を推測するシステムの解析部分は下記のように作っている例があります。(下記の例ではCrawl元のデータはTwitterですが、Analysis部分の例として参照しています)

Discussion