【イラストで分かる】React Hook
はじめに
こんにちは。
ソフトウェアエンジニアをしています、Koyaです。
普段、React周りを勉強してます。
最近は単に動くものを実装するのではなく、Reactの仕組みを踏まえた実装をするように意識してます。
そこで今回はReact Hookについて調べましたので、まとめたいと思います。
また自分の整理を含めて、極力細かく説明していこうと思ってます。
可能な限り公式ドキュメント等で収集した信頼できる情報を基にまとめていますが、間違いや認識違い等あると思います。
ぜひコメントで指摘いただければと思います。
また筆者は視覚優位な特徴(*1)を持ちます。
同じ視覚優位な特徴を持つ人たちに向けて、わかりやすいように可能な限りイラスト・図を使って説明したいと思います。
では、よろしくお願いします!
*1 : 物事の理解の仕方は人によって異なると言われています
前提
本記事は、【イラストで分かる】Reactとライフサイクルの続編という位置づけの記事です。
もしよければ、こちらも見ていただければと思います。
前回の記事で、クラスコンポーネントのライフサイクルは以下のようになっており、

画像1
Reack hookを使うことで関数コンポーネントでもライフサイクルが再現されていることをお伝えしました。

画像2
2つの画像(特に「Mounting」と「Updating」)を見比べると、関数コンポーネントのライフサイクルでは、constructorとrenderがないことがわかると思います。
これは関数コンポーネントそのものがrenderの役割をしているためです。
興味ある方は、以下参考に見てみてください。
では、各React hookの説明とライフサイクルにおける役割と合わせて説明できればと思います。
React Hook
React hookがどういう経緯で存在するのかは、前回の記事を参照ください。
また本記事でもレンダリングという単語が出てきます。
Reactに関するフロントエンドでは、レンダリングには以下の2種類あると考えています。
- 仮想DOMに反映する、Reactレンダリング
- ブラウザ上に表示する、画面レンダリング
上記のように使い分けていきます。上記の違いについては前回の記事を参照ください。
本題に入る前にこのReactレンダリングが再レンダリングされる条件があります。覚えておいてください。
・コンポーネントのstateが変更されたとき
・コンポーネントのpropsが変更されたとき
・親コンポーネントが再レンダリングされたとき
・コンポーネントの内部で使用されるcontextが変更されたとき
React hookがどんな役割をするのか、イメージできてますでしょうか?
一通り概要を把握した(と思ってる)筆者の認識としては、
React hookは
「いちいちデータを取りに行ったり計算したりするのダルイ。データに関しては、基本はキャッシュに保管しといて、キャッシュから情報を取得する。マジで必要な時だけDB・外部API等に取りに行く。計算(関数実行)に関しても、結果はキャッシュからとってきて、必要な時だけ実行しよう。(出来るだけサボろうぜ)」
用のツールだと思ってます。
このイメージを持って、読み進めていただけたら理解がしやすいかもしれません。
本質的には、DB等へのアクセスや計算の回数を極力減らすことでパフォーマンスを上げよう、というのが狙いです。
そして本題ですが、
各React hookがどういう風に使うのかについては、以下の記事にサンプルコードも含めてとても丁寧にまとめられていると思いますので、まず見てみてください。
正直まとめられすぎて、使い方についてこちらを参考にしましょう(笑)
ただ、自分がhookを理解するうえで詰まった所やイメージしにくい所もあったので、そこをまとめていきたいと思います。
useMemo
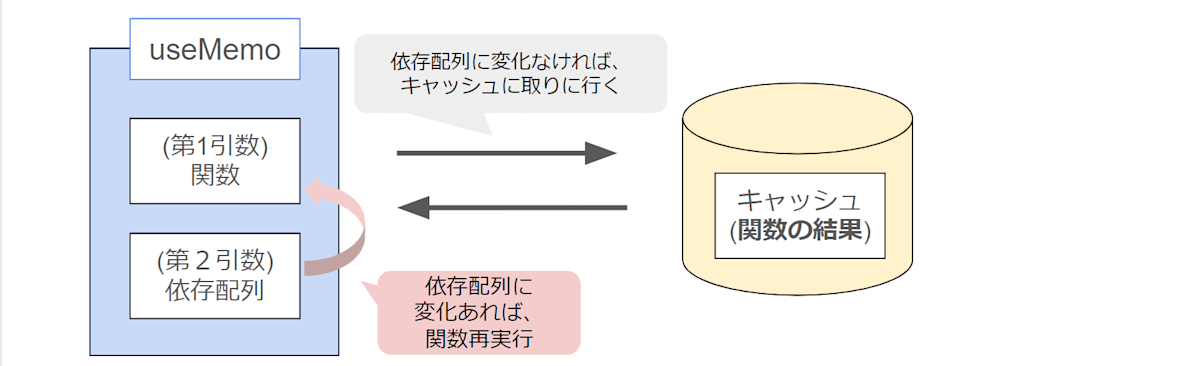
useMemoとは、初回に処理の実行結果を記録(メモ=キャッシュに保管)しておき、値が必要となった2回目以降は、計算せずに保管しておいたキャッシュから値を呼び出すフックです。※依存配列が変更された時だけ計算を再度行います。
これによって、毎度計算する必要がなくなりますね。
太字にしている「実行結果」の部分は覚えておいてください。
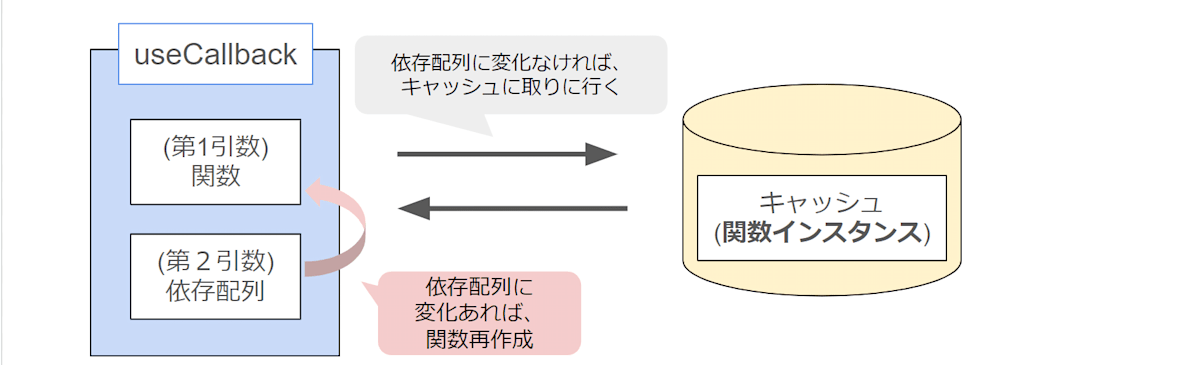
useCallback
useCallbackとは、**関数(インスタンス)**を記録(キャッシュに保管)しておき、 依存配列の値が変わった場合にのみ、新しい関数が生成されるフックです。
useMemoとは、キャッシュに保存するデータが異なることをご注意ください。
また、useCallbackの話があるとReact.memoも一緒に使いましょう的な話題が上がると思います。
このReact.memoと併用することで何がうれしいか、使わないとどんな不利益があるのか、整理してみました。
その前にReact.memoの役割について整理しておきましょう。
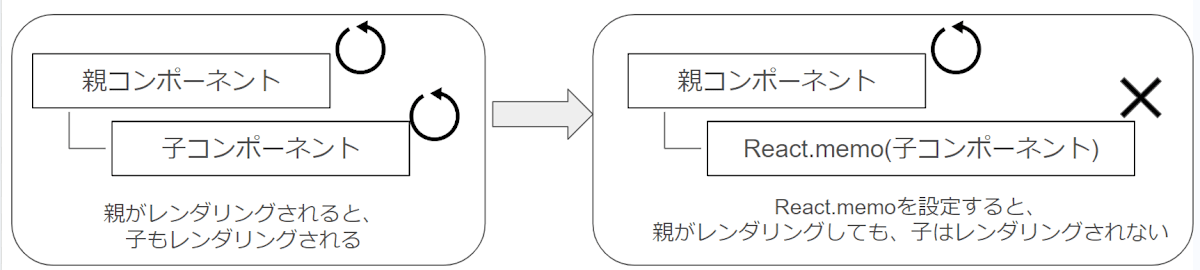
React.memoは、コンポーネントを記録(キャッシュに保管)して、再レンダリングの回数を削減するための関数です。
React.memo()を使用することで、コンポーネントのpropsが変更されていない場合に再レンダリングをスキップすることができます。
※依存配列ではなくpropsが変更されると実行されることも、useMemoやuseCallbackとの違いです。
つまり、下の画像のような使い方をします。これによって、子コンポーネントのレンダリング回数を削減できパフォーマンスの向上が期待できます。
ただし、子コンポーネントのpropsに関数が設定されていた場合、React.memoを使用していても子コンポーネントは」レンダリングされてしまいます。理由は画像記載の通りです。
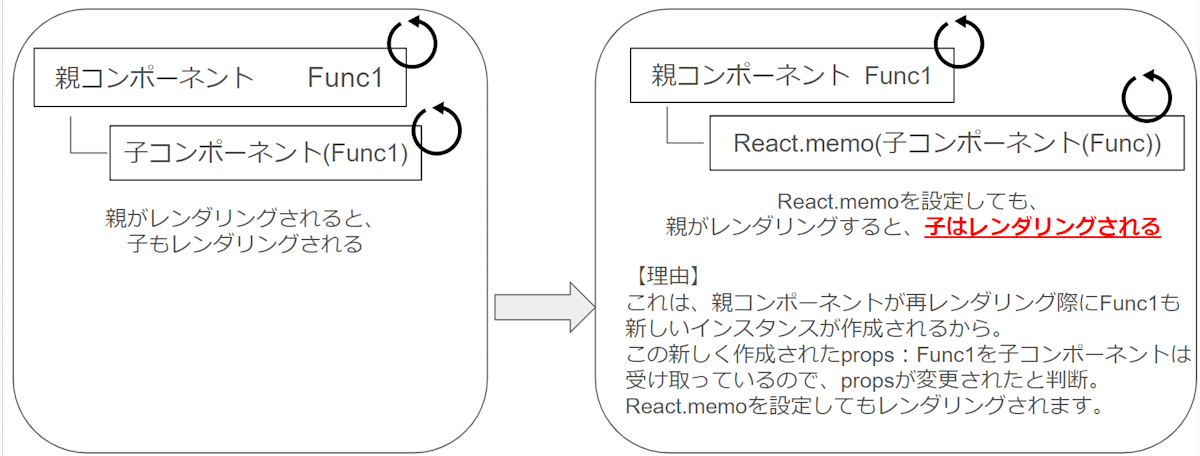
そこで活躍するのが、useCallback()です。useCallbackによって、関数インスタンスの再作成を抑制できます。
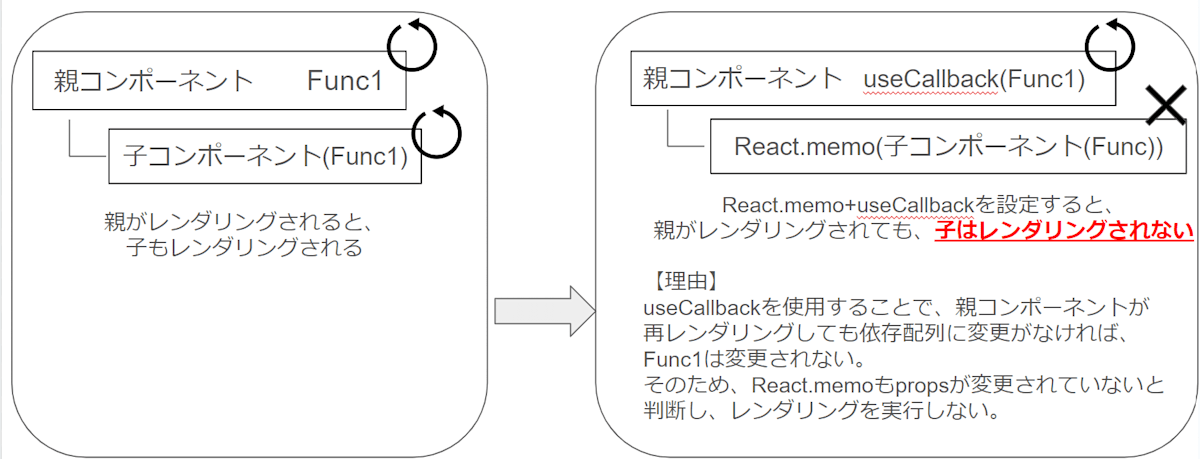
したがって、
- React.memoだけを使用しても、(propsが関数の時は)関数再作成され子コンポーネントはレンダリングされる
- useCallbackだけを使用しても、親がレンダリングされると子コンポーネントもレンダリングされる。
という状況になりますので、**React.memo x useCallback()**の組み合わせが必要になります。
useContext
useContextとは、Context機能をよりシンプルに使えるようになった機能。
親からPropsで渡されていないのに、Contextに収容されているデータへよりシンプルにアクセスできるというものです。
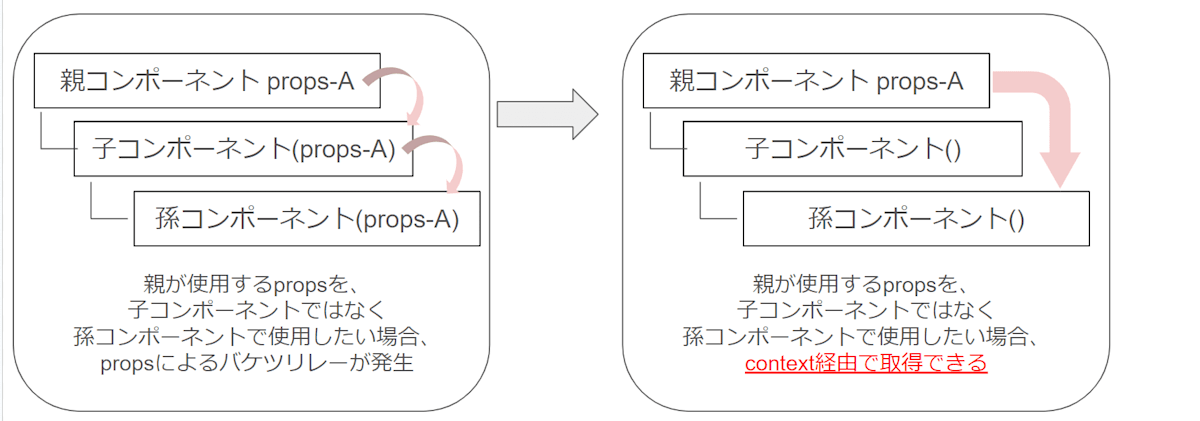
useState
react hookの話があると、まずこの子が出てきます。
これはもう説明が不要とすら感じますが(笑)、状態管理用のhookと言われてます。
ここで「状態管理」と言われて、ピンときましたでしょうか?
(自分は最初分からず、ぼんやりとしか把握できていませんでした)
そこで「状態管理」について、簡単に説明したいと思います。
日本語的に「状態管理」を「状態」と「管理」に分けて考えてみましょう。
状態
そもそも「状態」とは何でしょうか?
一例として「お腹の空き具合」に例えて考えてみましょう。
朝起きたとき、お腹が空いているとします。
これをプログラム的に書くと
stomach = 0; //お腹が空いている状態
そして、ご飯を食べるとお腹いっぱいになります。
これをプログラム的に書くと
stomach = 100; //お腹がいっぱいの状態
になります。
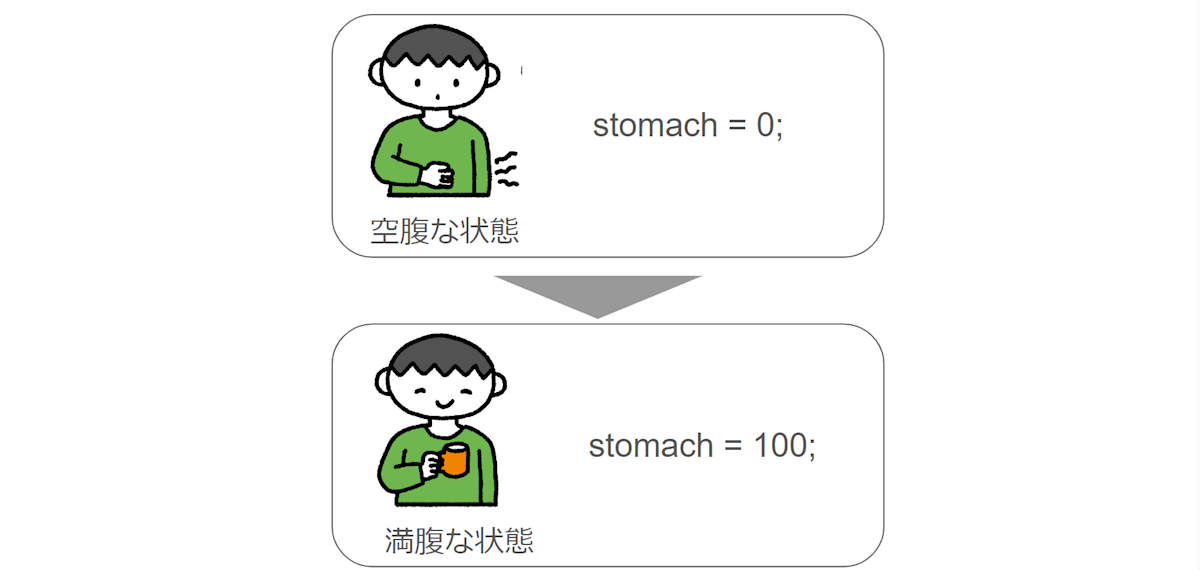
お腹が空いている状態 = (その時)stomachが0というデータを持っている
お腹がいっぱいの状態 = (その時)stomachが100というデータを持っている
ということになりますので、個人としてはプログラム上
状態 = (その時点での)データ
という認識です。
管理
「管理」はreactのドキュメントを見てみましょう。すると以下のように記載されています。
useState は現在の state の値と、それを更新するための関数とをペアにして返します。
「管理」という単語は出てきておらず、「更新」という単語が使われています。
なので
管理 = 更新
と置き換えることができるのではないのでしょうか?
関数コンポーネントのライフサイクル図においても、useStateが「Updating」の部分に属していることも確認ください。
まとめると、
useStateは状態管理( = データ更新)用のhookと言えるのではないでしょうか?
「状態管理」よりはわかりやすくなりましたかね?(笑)
useReducer
問題児ですね。※勝手にそう思っています(笑)。
なかなか使い方がわかりづらい印象です、useReducer。
色々なサイトで、「useStateより複雑なロジックや状態管理(データ更新)をしたいときに使う」といった文言がみられますね。
では一、旦公式ドキュメントを確認してみましょう。
すると以下のように記載されてもいます。
元も子もないことを言われてしまいましたね(笑)
ただこの結論で終わるわけにはいかないので、筆者なりに考えをまとめておこうと思います。
よく複雑ならuseReducer, シンプルならuseStateみたいな風潮がありますが、実は逆(複雑なロジックにuseState, シンプルなものにuseReducerで)も行けます。
以下の記事にサンプルコードあります。
では、結局どう使い分けるべきか、、、
以下のドキュメント記載部分がヒントになる気がしてます
useReducer を使うことで、更新ロジックによって書かれる「どう更新するのか」と、イベントハンドラに書かれる「何が起きたのか」とを、きれいに分離することができます。
useStateと違い、useReducerはreducer関数を作ってロジックを個別に定義できます。
ここが一番大きいかなと。コードの肥大化を防ぎ、可読性や保守性を向上できます。
したがって、見たら一目でわかるような状態管理でしたらuseStateでよいと思いますが個人的にはuseReducerを使った方が色々メリットありそう、という結論にたどり着きました。
参考までに。
useRef
useRef は、唯一のプロパティであるcurrentに、指定された初期値が設定された状態の ref オブジェクトを返します。
次回以降のレンダーでも、useRef は同じオブジェクトを返します。このオブジェクトの current プロパティを書き換えることで情報を保存しておき、あとからその値を読み出すことができます。
これは state と似ていますが、大きく違う点があります。
それは、ref を変更しても、再レンダーはトリガされないということです。
このことから、ref は、出力されるコンポーネントの外見に影響しないデータを保存するのに適しています。
例えば、インターバルの ID を保持しておき、あとから利用したい場合、ref に保存することができます。
useEffect
useEffectも、基本は「計算に関しても、必要な時だけ計算しよう。(出来るだけサボろうぜ)」に乗っ取ったフックです。ただ、注意点は、実行するタイミングです。
useEffectも他hook同様、Reactは第2引数の依存配列の中身の値を比較して、副作用関数をスキップするかどうかを判断します。
ただし、実行する場合はReactによる画面レンダリングが終了した後に実行します(関数の実行タイミングをReactによる画面レンダリング後まで遅らせます)。
ここ、なぜ画面レンダリングされた後に実行されるuseEffectがよく使われているか説明できますか?
色々理由はありますが、大きく以下のような理由が挙げられます。
・レンダリングプロセスが速くする(どちらかというとレンダリングの邪魔をしない)。副作用の実行がレンダリング中に行われると、レンダリングが遅くなる可能性があります。
・コンポーネントのレンダリングが完了した後に関数実行を行うことで、必要なデータが取得されるまでUIが空白やローディング状態を表示できるようになります。
などなど
クリーンアップ関数
適切にクリーンアップ関数を設定しないとメモリリークといった問題が発生します。
クリーンアップが必要な場合:
コンポーネントのライフサイクルに伴い、リソースを確実に解放する必要がある場合
(例:イベントリスナー、タイマー、サブスクリプション、外部リソース)
クリーンアップが不要な場合:
一度限りの操作や、コンポーネントの状態に影響を与える単純な更新が必要な場合
(例:データフェッチ、単純なDOM操作、ローカル状態の更新)
このあたりを意識してコーディングしていきましょう。
useEffectのイメージは以下の記事が参考になります。
ライフサイクル
useEffctのライフサイクルについては、以下のようにドキュメントに記載されています。
useEffect フックを componentDidMount と componentDidUpdate と componentWillUnmount がまとまったものだと考えることができます。
つまりDOMのマウントと更新、いずれのタイミングでも処理が走ります。
そのため、画像2でも、MoutingとUpdatingにまたがったような表現になっているんですね
useLayoutEffect
useLayoutEffectは、useEffectとは違う点は画面レンダリング前に実行されます。
これによって、DOMの変更を即座に適用し、ユーザーに見える前にUIを調整できます。
ただし、useLayoutEffectは通常のuseEffectよりも実行タイミングが早いため、過度に使用するとパフォーマンスに影響を与える可能性があります。お気を付けください。
まとめ
いかがだったでしょうか?
少しでも皆さんの理解につながれば幸いです。
筆者としては文字に書き起こすことでだいぶ整理されたような気がします。
ただイラスト化するのは少し大変でした。
後半はバテちゃいました。すみません(笑)
またreact周りの記事を書いていければと思います。
ありがとうございました。
参考文献
Discussion
とても分かりやすかったです!助かりました!
コメントありがとうございます!