TPUとKaggle
はじめに
この記事は、Kaggle Advent Calendar 2021の13日目の記事です。
昨日はtattakaさんによる鳥コンペ三部作を振り返る、でした。明日はymd_さんによる時系列のCross Validationについて、です。
この記事では、最近Kaggleでもよく用いられるようになってきたTPUについてまとめていこうと思います。
想定読者は
- TPUをまだ使ったことがない人
- Kaggleをやってみたいが、安く使える計算リソースがなく困っている人
です。
TPUとは
TPUに関する一般的な話はGoogleのTPU紹介を視聴した方が良いので、少し触れるのみにします。
TPUはGoogleが開発した、行列計算に特化した計算デバイスです。機械学習、その中でも特にDeep Learningは行列計算が数多く登場しますが、従来はこれをCPUやGPUなどの汎用性の高い計算デバイスで行っていました。これらのデバイスは途中の計算結果をメモリに書き出すことで柔軟性の高い計算を行うことができます。一方TPUは柔軟性を犠牲にしつつも、複数の計算ユニットを繋いで物理的な計算パイプラインを作りメモリアクセスを大幅に減らすことで高速に行列計算を行うことができます。
TPUには世代があり現在はTPU-v4が最新のものです。後で触れるKaggle NotebookではTPU-v3が使え、Google ColaboratoryではTPU-v2を利用することができます。また、Cloud TPUでは、複数のTPUを繋いで大きな単位にしたTPU Podというものも利用できるようです。

TPUのPod
Kaggle NotebookとColabにおける利用
Kaggle Notebookでは週に20時間まで、TPU-v3を利用することができます。Acceleratorという項目でプルダウンメニューからTPU v3-8を選択することで利用が可能です。
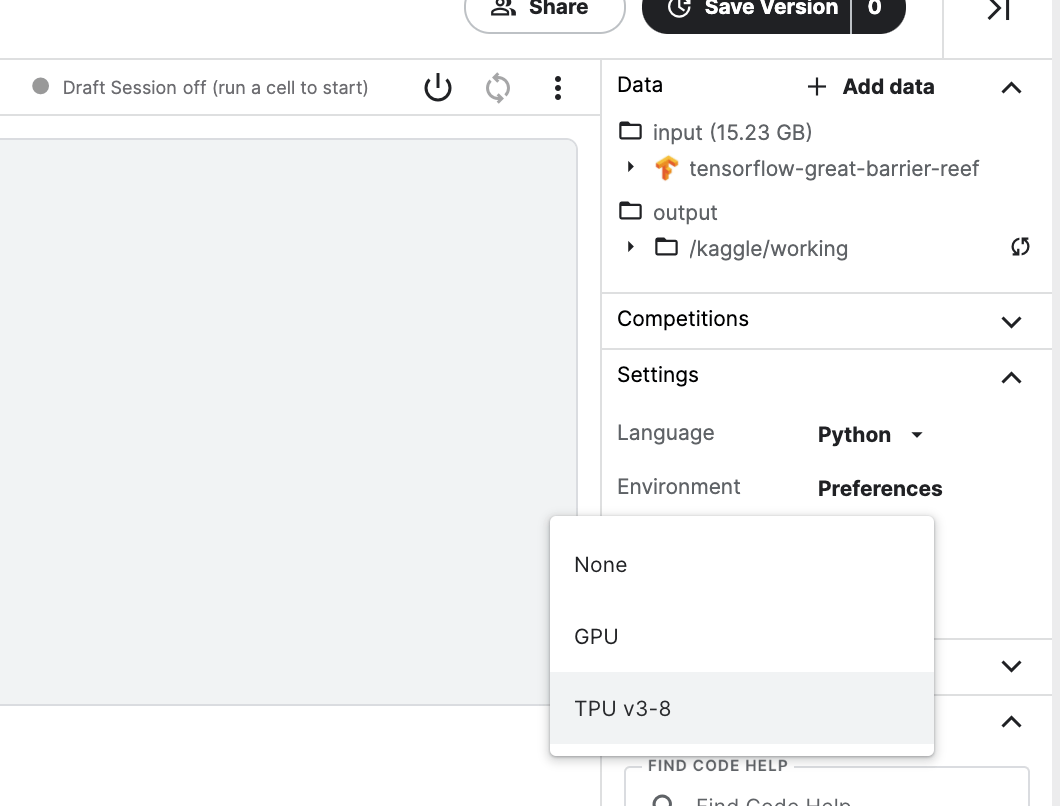
Kaggle NotebookでTPUを利用するにはAcceleratorのところで選択する
一方Google Colaboratory、Colab Proでは最大12時間までTPUを利用できます。ただし、Google Colaboratoryは、実際にはTPUを12時間利用し続けるのは想定利用用途と異なるため長時間利用する場合はColab Proを使うことが推奨されています。実際、Google Colaboratoryで長時間かかる計算を行うと、頻繁に操作中であることを確認するポップアップが現れるほか、一定時間操作がないと接続が自動的に遮断されてしまいます。
Colab Proは2021年12月現在で1072円/月となっているため、Kaggle用途の計算環境としてはかなり格安となっています。
また、Colab Pro+はColab Proの5倍の価格設定となっていますが、TPUも24時間連続利用可能なセッションが3つ上限で同時に建てられるとのことで、計算環境としてはかなり魅力的な条件になっているかと思います[1]。また、Colab Pro+はバックグラウンド実行ができるため、ブラウザでセッションを繋ぎっぱなしにしておく必要がないのもありがたいところです。
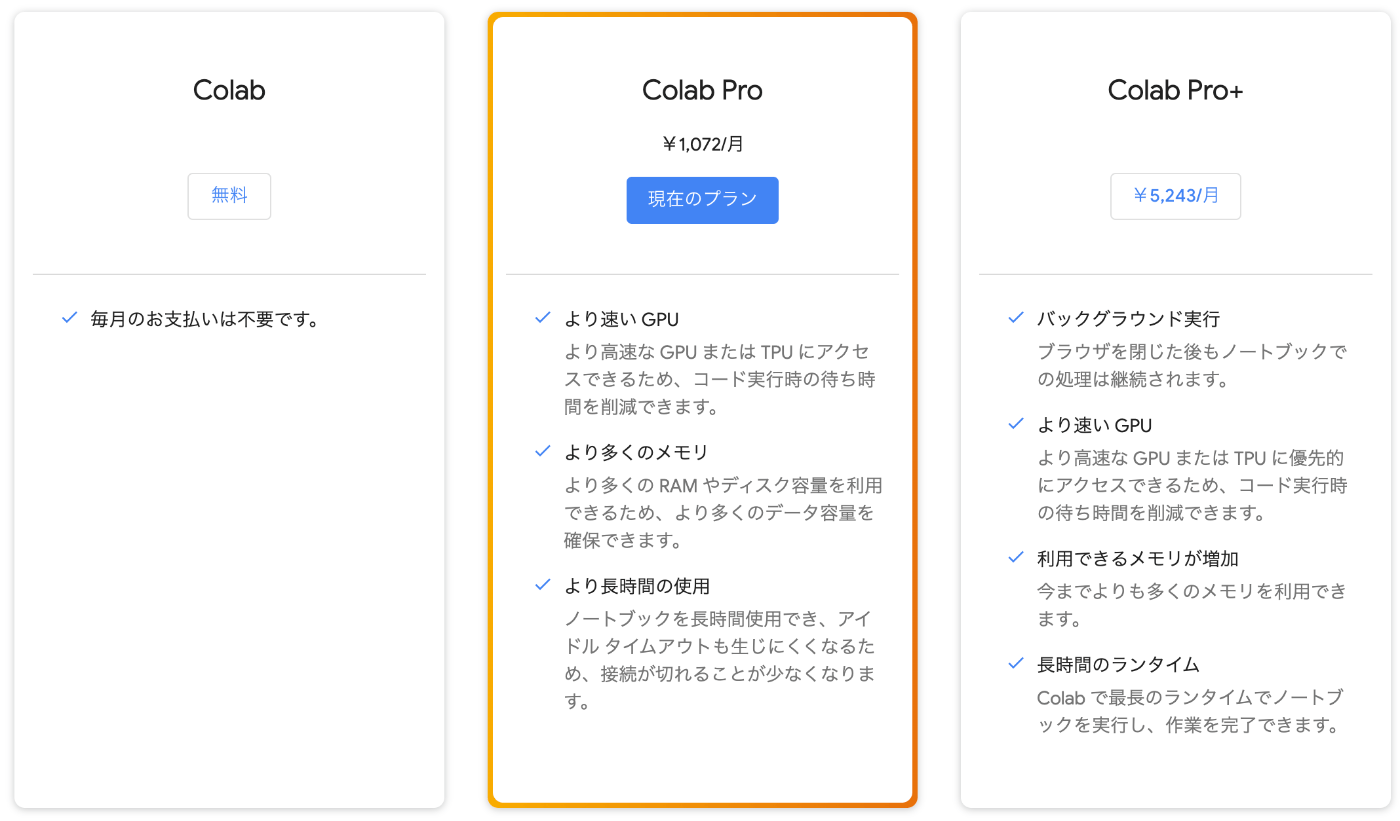
Google Colaboratory Seriesの価格設定(2021年12月時点)
さて、Colab SeriesでTPUを利用するためには、まず画面左上のタブから「ランタイム」を選択し、プルダウンの中から「ランタイムのタイプを変更」をクリックします。その後現れるモーダルの中で、「ハードウェアアクセラレータ」をTPUに変更して保存をクリックすればTPUが利用できるようになります。

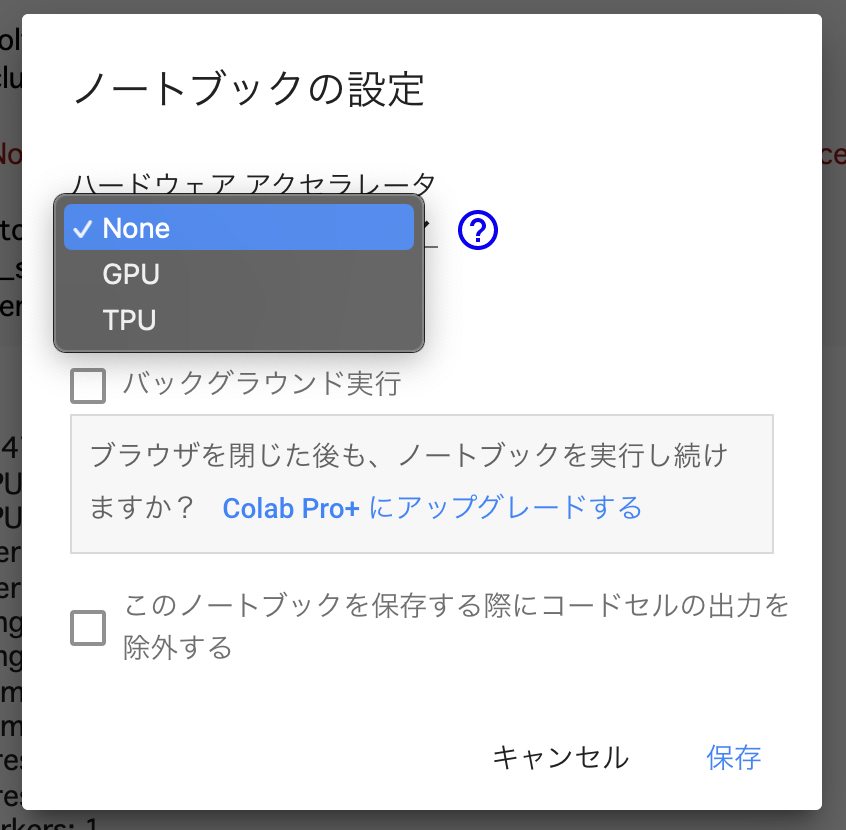
フレームワークでのTPUの利用設定
ここまではKaggle NotebookやGoogle ColaboratoryでTPUをバックエンドで利用できるようにする手順を紹介しましたが、コード上でもTPUを利用する設定をしないとTPUを使った計算は行われません。ここからのセクションでは、Tensorflow、PyTorch、JAXでのTPUの利用の仕方を紹介します。
なお私自身はTensorflowを用いてしかTPU利用経験がないため、PyTorchとJAXについては、公開されている情報をもとに、試してみた程度の話となっています。
Tensorflowでの利用
Googleが公式で提供するTPUs in ColabのNotebookでは、TPUを利用するための手順として次のようなコードスニペットが紹介されています。
%tensorflow_version 2.x
import tensorflow as tf
print("Tensorflow version " + tf.__version__)
try:
tpu = tf.distribute.cluster_resolver.TPUClusterResolver() # TPU detection
print('Running on TPU ', tpu.cluster_spec().as_dict()['worker'])
except ValueError:
raise BaseException('ERROR: Not connected to a TPU runtime; please see the previous cell in this notebook for instructions!')
tf.config.experimental_connect_to_cluster(tpu)
tf.tpu.experimental.initialize_tpu_system(tpu)
tpu_strategy = tf.distribute.experimental.TPUStrategy(tpu)
出力
TensorFlow 2.x selected.
Tensorflow version 2.1.0
Running on TPU ['10.4.82.210:8470']
INFO:tensorflow:Initializing the TPU system: 10.4.82.210:8470
INFO:tensorflow:Initializing the TPU system: 10.4.82.210:8470
INFO:tensorflow:Clearing out eager caches
INFO:tensorflow:Clearing out eager caches
INFO:tensorflow:Finished initializing TPU system.
INFO:tensorflow:Finished initializing TPU system.
INFO:tensorflow:Found TPU system:
INFO:tensorflow:Found TPU system:
INFO:tensorflow:*** Num TPU Cores: 8
INFO:tensorflow:*** Num TPU Cores: 8
INFO:tensorflow:*** Num TPU Workers: 1
INFO:tensorflow:*** Num TPU Workers: 1
INFO:tensorflow:*** Num TPU Cores Per Worker: 8
INFO:tensorflow:*** Num TPU Cores Per Worker: 8
INFO:tensorflow:*** Available Device: _DeviceAttributes(/job:localhost/replica:0/task:0/device:CPU:0, CPU, 0, 0)
INFO:tensorflow:*** Available Device: _DeviceAttributes(/job:localhost/replica:0/task:0/device:CPU:0, CPU, 0, 0)
INFO:tensorflow:*** Available Device: _DeviceAttributes(/job:localhost/replica:0/task:0/device:XLA_CPU:0, XLA_CPU, 0, 0)
INFO:tensorflow:*** Available Device: _DeviceAttributes(/job:localhost/replica:0/task:0/device:XLA_CPU:0, XLA_CPU, 0, 0)
INFO:tensorflow:*** Available Device: _DeviceAttributes(/job:worker/replica:0/task:0/device:CPU:0, CPU, 0, 0)
INFO:tensorflow:*** Available Device: _DeviceAttributes(/job:worker/replica:0/task:0/device:CPU:0, CPU, 0, 0)
INFO:tensorflow:*** Available Device: _DeviceAttributes(/job:worker/replica:0/task:0/device:TPU:0, TPU, 0, 0)
INFO:tensorflow:*** Available Device: _DeviceAttributes(/job:worker/replica:0/task:0/device:TPU:0, TPU, 0, 0)
INFO:tensorflow:*** Available Device: _DeviceAttributes(/job:worker/replica:0/task:0/device:TPU:1, TPU, 0, 0)
INFO:tensorflow:*** Available Device: _DeviceAttributes(/job:worker/replica:0/task:0/device:TPU:1, TPU, 0, 0)
INFO:tensorflow:*** Available Device: _DeviceAttributes(/job:worker/replica:0/task:0/device:TPU:2, TPU, 0, 0)
INFO:tensorflow:*** Available Device: _DeviceAttributes(/job:worker/replica:0/task:0/device:TPU:2, TPU, 0, 0)
INFO:tensorflow:*** Available Device: _DeviceAttributes(/job:worker/replica:0/task:0/device:TPU:3, TPU, 0, 0)
INFO:tensorflow:*** Available Device: _DeviceAttributes(/job:worker/replica:0/task:0/device:TPU:3, TPU, 0, 0)
INFO:tensorflow:*** Available Device: _DeviceAttributes(/job:worker/replica:0/task:0/device:TPU:4, TPU, 0, 0)
INFO:tensorflow:*** Available Device: _DeviceAttributes(/job:worker/replica:0/task:0/device:TPU:4, TPU, 0, 0)
INFO:tensorflow:*** Available Device: _DeviceAttributes(/job:worker/replica:0/task:0/device:TPU:5, TPU, 0, 0)
INFO:tensorflow:*** Available Device: _DeviceAttributes(/job:worker/replica:0/task:0/device:TPU:5, TPU, 0, 0)
INFO:tensorflow:*** Available Device: _DeviceAttributes(/job:worker/replica:0/task:0/device:TPU:6, TPU, 0, 0)
INFO:tensorflow:*** Available Device: _DeviceAttributes(/job:worker/replica:0/task:0/device:TPU:6, TPU, 0, 0)
INFO:tensorflow:*** Available Device: _DeviceAttributes(/job:worker/replica:0/task:0/device:TPU:7, TPU, 0, 0)
INFO:tensorflow:*** Available Device: _DeviceAttributes(/job:worker/replica:0/task:0/device:TPU:7, TPU, 0, 0)
INFO:tensorflow:*** Available Device: _DeviceAttributes(/job:worker/replica:0/task:0/device:TPU_SYSTEM:0, TPU_SYSTEM, 0, 0)
INFO:tensorflow:*** Available Device: _DeviceAttributes(/job:worker/replica:0/task:0/device:TPU_SYSTEM:0, TPU_SYSTEM, 0, 0)
INFO:tensorflow:*** Available Device: _DeviceAttributes(/job:worker/replica:0/task:0/device:XLA_CPU:0, XLA_CPU, 0, 0)
INFO:tensorflow:*** Available Device: _DeviceAttributes(/job:worker/replica:0/task:0/device:XLA_CPU:0, XLA_CPU, 0, 0)
これにより、TPUを利用する分散学習のStrategyが手に入ります。後は次のようにモデル定義のときにwith tpu_strategy.scope()ブロックを用いればTPU上で学習が行われるようになります。
def create_model():
pretrained_model = tf.keras.applications.Xception(input_shape=[*IMAGE_SIZE, 3], include_top=False)
pretrained_model.trainable = True
model = tf.keras.Sequential([
pretrained_model,
tf.keras.layers.GlobalAveragePooling2D(),
tf.keras.layers.Dense(5, activation='softmax')
])
model.compile(
optimizer='adam',
loss = 'categorical_crossentropy',
metrics=['accuracy']
)
return model
with tpu_strategy.scope(): # creating the model in the TPUStrategy scope means we will train the model on the TPU
model = create_model()
model.summary()
また、Kaggle上ではバックエンドがTPUではなくても同じコードで実行できるようにした次のような関数がよく用いられています。
def auto_select_accelerator():
TPU_DETECTED = False
try:
tpu = tf.distribute.cluster_resolver.TPUClusterResolver()
tf.config.experimental_connect_to_cluster(tpu)
tf.tpu.experimental.initialize_tpu_system(tpu)
strategy = tf.distribute.experimental.TPUStrategy(tpu)
print("Running on TPU:", tpu.master())
TPU_DETECTED = True
except ValueError:
strategy = tf.distribute.get_strategy()
print(f"Running on {strategy.num_replicas_in_sync} replicas")
return strategy, TPU_DETECTED
PyTorchでの利用
PyTorchでの利用は調査中です。PyTorch XLAを用いて行う必要がありますが、デバイスを1個使う場合と8個全て使う場合で注意しなければいけない事項が異なるため、挙動を調査しています。
TPUを使ってKaggleのRSNA Pulmonary Embplism Detectionコンペの学習パイプラインを組む記事などもあるため参照してみるといいかもしれません。
JAXでの利用
Cloud TPUのドキュメントによれば、Cloud TPU上では
pip install "jax[tpu]>=0.2.16" -f https://storage.googleapis.com/jax-releases/libtpu_releases.html
のようにインストールをすることでアクセラレータとしてTPUを使うようになってくれるようですが、Colabなどで利用する場合には、JAX入門~高速なNumPyとして使いこなすためのチュートリアル~にあるように
import requests
import os
if "TPU_DRIVER_MODE" not in globals():
url = 'http://' + os.environ['COLAB_TPU_ADDR'].split(':')[0] + ':8475/requestversion/tpu_driver0.1-dev20191206'
resp = requests.post(url)
from jax.config import config
config.FLAGS.jax_xla_backend = "tpu_driver"
config.FLAGS.jax_backend_target = "grpc://" + os.environ['COLAB_TPU_ADDR']
print(config.FLAGS.jax_backend_target)
TPUのアドレスを直接指定する必要があるようです。
一方Kaggle NotebookでJAXでTPUを利用するには、次のような指定をする必要があります。若干Colabと異なるので気をつける必要があります。
import os
if 'TPU_NAME' in os.environ:
import requests
if 'TPU_DRIVER_MODE' not in globals():
url = 'http:' + os.environ['TPU_NAME'].split(':')[1] + ':8475/requestversion/tpu_driver_nightly'
resp = requests.post(url)
TPU_DRIVER_MODE = 1
from jax.config import config
config.FLAGS.jax_xla_backend = "tpu_driver"
config.FLAGS.jax_backend_target = os.environ['TPU_NAME']
print('Registered TPU:', config.FLAGS.jax_backend_target)
else:
print('No TPU detected. Can be changed under "Runtime/Change runtime type".')
うまく指定できていれば
import jax
jax.local_devices()
の結果が次のようになります。
[TpuDevice(id=0, process_index=0, coords=(0,0,0), core_on_chip=0),
TpuDevice(id=1, process_index=0, coords=(0,0,0), core_on_chip=1),
TpuDevice(id=2, process_index=0, coords=(1,0,0), core_on_chip=0),
TpuDevice(id=3, process_index=0, coords=(1,0,0), core_on_chip=1),
TpuDevice(id=4, process_index=0, coords=(0,1,0), core_on_chip=0),
TpuDevice(id=5, process_index=0, coords=(0,1,0), core_on_chip=1),
TpuDevice(id=6, process_index=0, coords=(1,1,0), core_on_chip=0),
TpuDevice(id=7, process_index=0, coords=(1,1,0), core_on_chip=1)]
TPUを使うときの注意
TPUの計算はCPUやGPUの計算と大きく異なるため、CPUやGPUで動いていたコードが動かない、といったケースもあります。ここでは、そういったケースの中で私がTPUを利用している中で遭遇したものと解決法について紹介します。
なお、先述したとおり私のTPUの利用経験は主にTensorflowを用いてのものなので、解決策もTensorflowを用いる場合のものが中心となっています。
Data Loaderでは最後のバッチを使わない方がよい
TPUで学習を行なっている場合、バッチサイズが学習途中で変化するとエラーになることがあります。学習途中でバッチサイズが変化するシナリオとしてよくあるのが、Epochの最後のバッチです。
Deep LearningではミニバッチごとにForwardステップとBackwardステップを繰り返しながら勾配降下法によって重みを学習していきますが、データセットのサイズでミニバッチのサイズが割り切れない場合、最後のバッチのサイズは"あまり"のサイズになってしまいバッチサイズの変化が起きます。
これを防ぐためには、tensorflow.data.Datasetを使っている場合は、.batch(drop_remainder=True)オプションを設定します。torch.utils.data.DataLoaderの場合は、drop_last=TrueとしてDataLoaderを定義する必要があります。
TPUでは使えない演算や、制約のある演算がある
TPUは特定の軸方向の演算や、テンソルのサイズ、形などを変更する演算が得意ではありません。特定の軸方向に関してminをとるreduce_minやテンソルの形を変更するreshapeといった、比較的よく使われる演算においてもaxisやshapeがコンパイル時に判明している定数である必要がある、といった制約がかかっているものが多くあります。
また、Data Augmentationなどでよく用いられるtf.random_〇〇といった一部の演算はそもそも使えないこともあります。
一部演算に課せられた制約や、使えない演算などに関する情報は利用可能なTensorflow Operationのページにまとまっています。TPUで発生するエラーのスタックトレースはあまり読みやすくないのでデバッグに時間がかかりがちですが、制約のある演算の制約に触れてしまっていたりしないか確認してみたりすることでエラーの原因が見つかるかもしれません。
バッチサイズや特徴のサイズは128/8の倍数にする
TPUのパフォーマンスを高く保つためには、さまざまな条件があるようですが、その中でも重要なのが、バッチサイズや特徴サイズ(画像であれば画像の空間方向のサイズ)が重要となってくるようです。これは、内部ではパディングを行なってテンソルのサイズをTPUで計算可能な形に直してから計算を行なっているため、パディングのコストを下げることがパフォーマンス向上につながるからのようです。
詳しくはパフォーマンスガイドを参照してください。
また、このパフォーマンスガイドには
-
tf.nn.max_poolは遅いので可能な限りtf.nn.avg_poolにする - テンソルの結合は負荷が高いため可能な限り
tf.concatなどの演算は避ける
などの演算ごとの推奨事項も書いてあるため目を通す価値はあるでしょう。
Memory Exhaustedの場合はTPUコネクションを繋ぎ直す
TPUを利用して5Foldの学習を行なっていると、なぜか3Fold目で突然Memory Exhaustedになってエラーになる、といったことが起きる場合があります。
この場合、毎Foldで
tf.config.experimental_connect_to_cluster(tpu)
tf.tpu.experimental.initialize_tpu_system(tpu)
を呼んであげるとエラーが起こらなくなることがあります。他にも、Jupyter環境などで何度も少し計算を回してみては実行することを繰り返していると、Memory Exhaustedになってしまう場合がありますが、その時は同様にTPUとの接続を繋ぎ直すと解消します。
まとめ
この記事では、TPUの概要とその利用法、そして利用にあたっての注意点や対処策などを紹介しました。近年のKaggleのコンペは計算リソースを要するものが多く、あまりコンペにお金をかけたくない人に少しつらい環境になりつつあります。TPUの利用にもお金がかかることが多いですが、Kaggle NotebookやGoogle Colaboratoryなど、無料または比較的安価に利用できる環境があるのと、うまく使いこなせればGPU以上の計算パフォーマンスを発揮できることもあることから、近年ではKaggleでもよく用いられるようになってきています。この記事がTPU利用を考える人たちの背中を押すようなものになればいいな、と思いつつ結びたいと思います。
-
※私はColab Pro+は契約していないため、これは伝聞です。 ↩︎
Discussion