ローカルLLMを構築して無課金でClineを使いたい!!
はじめに
こんにちは!北国でエンジニアをやっているNakaeです。
最近流行りのVibeコーディング、私も手を出して感動しています。
ただ、やはりクソ雑魚個人開発者である私は料金が気になってしまい、Clineを動かす度に動悸が止まりません。
どうにか無課金で使用する手段がないかと探していたところ、ローカルLLMを構築して、Clineの設定でモデルをそのローカルLLMに指定すれば課金不要でClineを動かすことができるとの情報を得ました。
今回はローカルLLMを構築して実際にClineで指示出しをするところまでの手順の記録を書いていこうと思います。
ローカルLLMを知らなかった人・使ってみたいなと思っている人たちの参考になれば幸いです。
以下参考記事です。
対象読者
- ローカルLLMの存在を知らなかった人
- ローカルLLMを使いたいと思っていたがなかなか手を出せずにいた人
そもそもローカルLLMって?
ローカルLLMとは、自端末にインストールして使用する大規模言語モデル(LLM)のことです。
Claudeやgptのようなクラウドベースのサービスとは違い、インターネットを介さず、完全にローカル環境で動作させることができます。
つまり、無料で公開されているローカルLLMを自端末にインストールして使用することで、APIの利用料金を気にせずにLLMを使いまくれるようになるということです。

それでは実際にローカルLLMを自端末にインストールしてみましょう。
前提条件
OS: Windows11
CPU: Intel(R) Core(TM) i7-14700F
GPU: NVIDIA GeFOrceRTX 4070 Ti SUPER
メモリ: 64GB
Cursor インストール済み & Clineの拡張機能インストール済み
Ollamaのインストール
まずはollamaの下記サイトからダウンロードしてインストールします。
ollamaは、ローカル環境で大規模言語モデル(LLM)を簡単に動かすことができるCLIツールのことです。
インストーラーが終了した後、Powershellで以下のコマンドを実行し、
ollama --version
以下のようにバージョンが表示されたらインストール完了です。
ollama version is 0.7.1
モデルのダウンロード
次に構築するローカルLLM本体をダウンロードします。
下記のサイトから使用するローカルLLMを選択し、
以下のようにPowershellでコマンドを実行してください。
今回はGoogleのgemma3というモデルを使用します。
ollama run gemma3:12b
ローカルLLMモデルのインストールが完了すると、以下のようにプロンプト入力待ち状態になります。

ここで任意のテキストを入力しEnterを押下すると、入力に対する回答が表示されます。

Clineの設定を変更
Cursorを起動し、Clineの設定画面に遷移します。
Clineの「API Conofiguration」で以下のように入力します。
API Provider: Ollama
Model: ID : ダウンロードしたローカルLLMのモデル名
その他: デフォルトのままでOK
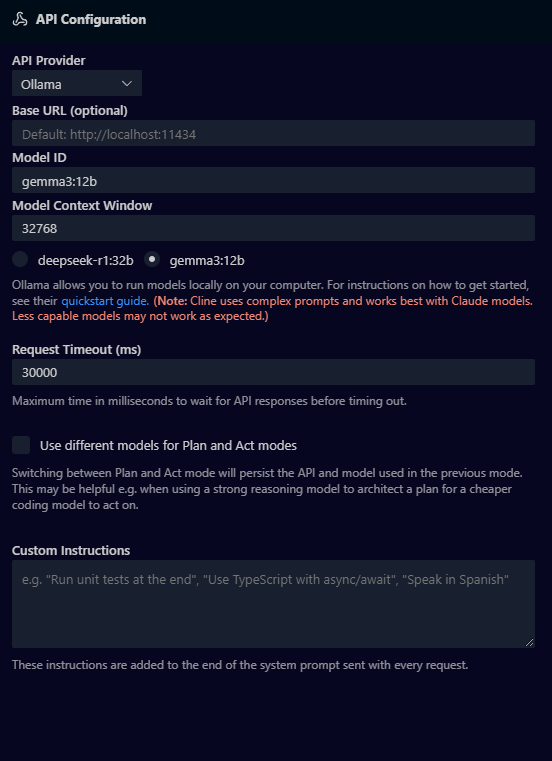
以上でローカルLLMでClineを動かす準備が完了しました。
実際にClineを動かす
それではClineを動かしてみます。
PHPでHelloWorldが表示されるスクリプトを作成してもらいましょう。

結果は以下の通りに作成されました。

やはりクラウドサービスのCloudeやgptを使用するよりかは速度はだいぶ遅いです。(上記は30秒ほどかかりました。)
使用する端末のスペックにより差が出るので、私のPCより高スペックなPCだともっと早くタスクが終了するかと思われます。
終わりに
今回は、ローカルLLMの導入から、実際にClineで動かすところまでを一通り試してみました。
Cloudeやgptに比べると、速度や精度の面ではまだ課題が残るものの、料金を気にせず自由に試行錯誤できる環境としては非常に魅力的です。個人開発や学習用途では、十分に選択肢のひとつになると感じました。
それでは、よいVibeコーディングライフを!
Discussion