react-three-fiber + tensorflow.js(cocossdモデル)+ GLSLで作るリアルタイムメディアアート
初めに
こんにちは、Frontend devのかめぽんです。2023年の12月23、24日に八戸市美術館というところで写真とメディアアートの展示を行いました。そこで、機械学習を使って人を判別しそこに光の輪が追尾するリアルタイムメディアアートを作ったのですが、個人的にはかなり勉強になりましたし表現の幅が広がったこともあり、記事にしようと思いました。ぜひご参考にしてもらえれば嬉しいです。
各技術の説明
react-three-fiber
react-three-fiberはReactとThree.jsを組み合わせたライブラリで、シームレスな3Dグラフィックスを構築するのに最適です。ReactのコンポーネントベースのアーキテクチャとThree.jsの強力な3D描画機能が統合され、直感的で拡張可能な3Dアプリケーションを開発できます。three.jsと異なる大きな点は宣言的に記述できるところです。
three.jsとreact-three-fiberを使った違いを以下に示してみます。
// シーンの作成
const scene = new THREE.Scene();
// カメラの作成
const camera = new THREE.PerspectiveCamera(75, window.innerWidth / window.innerHeight, 0.1, 1000);
camera.position.z = 5;
// レンダラーの作成
const renderer = new THREE.WebGLRenderer();
renderer.setSize(window.innerWidth, window.innerHeight);
document.body.appendChild(renderer.domElement);
// キューブの作成
const geometry = new THREE.BoxGeometry();
const material = new THREE.MeshBasicMaterial({ color: 0x00ff00 });
const cube = new THREE.Mesh(geometry, material);
scene.add(cube);
// アニメーションの設定
const animate = () => {
requestAnimationFrame(animate);
cube.rotation.x += 0.01;
cube.rotation.y += 0.01;
renderer.render(scene, camera);
};
// ウィンドウサイズが変更されたときの処理
window.addEventListener('resize', () => {
camera.aspect = window.innerWidth / window.innerHeight;
camera.updateProjectionMatrix();
renderer.setSize(window.innerWidth, window.innerHeight);
});
animate();
次にreact-three-fiberで書いた場合のサンプルです。
import React, { useRef } from 'react';
import { Canvas, useFrame } from 'react-three-fiber';
const Cube = () => {
const cubeRef = useRef();
// フレームごとのアニメーション処理
useFrame(() => {
cubeRef.current.rotation.x += 0.01;
cubeRef.current.rotation.y += 0.01;
});
return (
<mesh ref={cubeRef}>
<boxGeometry args={[1, 1, 1]} />
<meshBasicMaterial color={0x00ff00} />
</mesh>
);
};
const App = () => {
return (
<Canvas>
<Cube />
</Canvas>
);
};
export default App;
three.jsだけでも手軽に3Dをあつかえ扱えますが、react-three-fiberを使うことでReactと親和性の高い宣言的な書き方で記述できます。
今回は、react-three-fiberらしい機能はそこまで使いませんが、GLSLを実行するためのモジュールが含まれていて、js =>GLSLの 環境を作る手間を省くためにshaderMaterialを使ってテンプレートを作るために使用します。
tensorflow.js
tensorflow.jsは、機械学習モデルをブラウザやNode.js上で実行するためのオープンソースのJavaScriptライブラリです。リアルタイムでの機械学習推論を可能にし、ブラウザ上で複雑なタスクを実現します。COCO-SSD(Common Objects in Context - Single Shot Multibox Detector)などの事前トレーニング済みモデルも提供されており、簡単に導入できます。webカメラを使ったサンプルアプリのコードやチュートリアルもあり手軽に始められます。
GLSL (Graphics Library Shading Language)
GLSLはグラフィックスプログラミング用のシェーダ言語で、GPU上で動作します。シェーダは3Dオブジェクトや効果を描画するためのプログラムであり、高度な視覚効果やクリエイティブな表現を可能にします。react-three-fiberと組み合わせることで、リアルタイムでのシームレスな視覚体験を構築するのに役立ちます。シェーダーを手軽に試すにはGLSL Editorやvscode上で実行可能な拡張機能であるglsl-canvasを使うとすぐに始められます。
アーキテクチャとそれぞれの役割
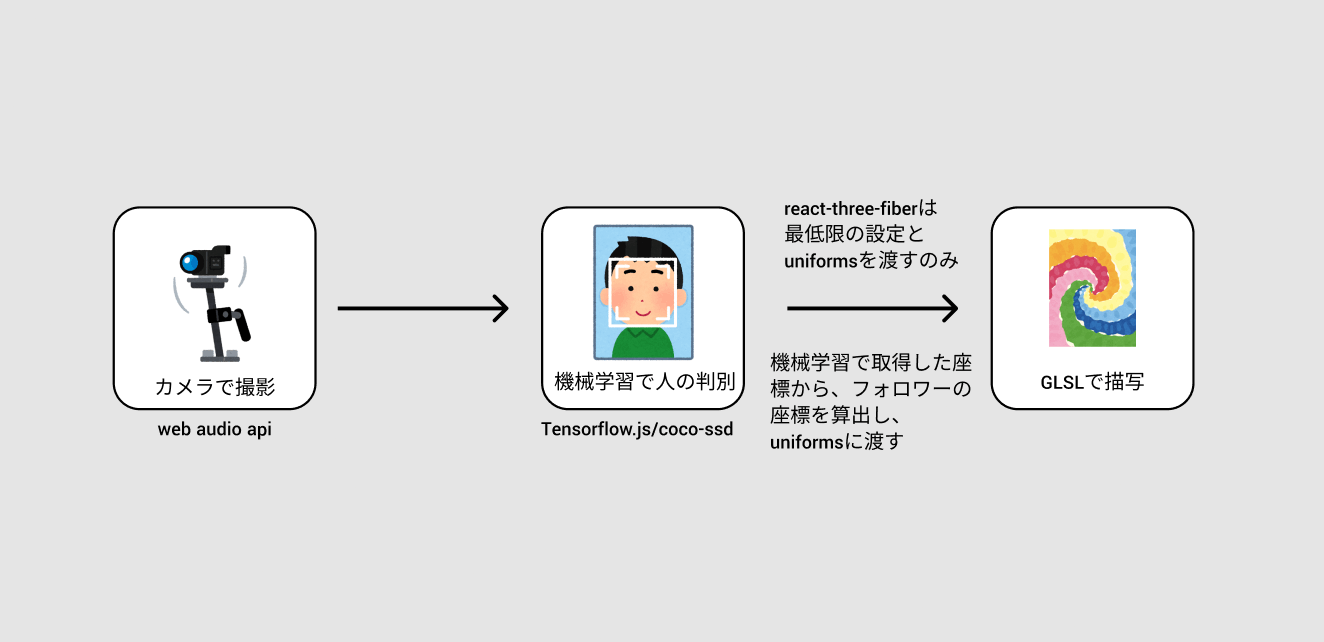
アーキテクチャ自体ははそこまで複雑なものではありませんが、コードにすると少し長くなってしまうので簡単な図にしておきます。実際に使ったコードはGithubに上げていますので参考にしてみてください。
上記のアーキテクチャを実現するには以下が必要になってきます。実際にコードを書いていきます。
- react-three-fiberを使ってGLSLとjavascript部分を接合するテンプレート作り
- 機械学習のユーティリティクラスの作成
react-three-fiberを使ってGLSLとjavascript部分を接合するテンプレート作り
react-three-fiberを使うのに事前に @react-three/fiber モジュールをnpm installしておきます。以下がreact-three-fiberを使ったコンポーネントの全容です。
ポイントはshaderMaterialArgsとuseFrameかと思います。 new THREE.ShaderMaterialでシェーダーで扱うデータをもとにShaderMaterialのインスタンスを作っておきます。uniformsはjavascript側からGLSL側に送るデータで変更される可能性が大いにあるので、useMemoのdepsにuniformsを追加しておきます。
useFrameはエフェクトの実行やコントロールの更新など、レンダリングされたフレームごとにコードを実行できます。コールバック関数は、フレームがレンダリングされる直前に呼び出されます。アンマウントされることでレンダリングループから自動的にサブスクライブが解除されます。注意点としてはreact-three-fiberで提供しているCanvasコンポーネントの内部でのみ使えるフックであるということです。
ですので
import { useFrame } from '@react-three/fiber'
function App() {
useFrame((state, delta, frame) => { // not working
// do something
});
return (
<Canvas>
<mesh>
ではなく、以下の通りにすることです。
function Foo() {
useFrame((state, delta, frame) => { // working 🎉🎉🎉
// do something
});
}
function App() {
return (
<Canvas>
<Foo />
useFrameの中ではtimeとresolutionは常に更新しておくようにします。
useFrame((state,delta,frame) => {
shaderMaterialArgs.uniforms.time = { value: state.clock.getElapsedTime()}
shaderMaterialArgs.uniforms.resolution.value.set(window.innerWidth,window.innerHeight)
...
});
機械学習のユーティリティクラスの作成
ここではtensorflowjsのcoco-ssd(物体認識学習済みモデル)を使って映像から物体認識をし、認識結果を返す役割と担います。事前に @tensorflow/tfjs と @tensorflow-models/coco-ssd をnpm installしておきます。
コードの全体はGithubにあげますのでご参考にしてもらえればと思います。
大事な部分としては、load関数とstart関数になります。
loadではcoco-ssdモデルの読み込みとそれに流し込むためのvideoタグの情報を宣言あるいはstreamのセットをします。videoタグではカメラの映像を表示させるので navigator.mediaDevices.getUserMedia でMediaStreamを取得しvideoタグ宣言と同時にstreamのセットをします。そうすることで後でvideoタグとcoco-ssdモデルを結合するだけで物体認識ができます。
async loadModel(config: cocoSsd.ModelConfig = {}) {
try {
this._model = await cocoSsd.load(config);
return this.model;
} catch(e) {
console.error(e);
throw e;
}
}
async loadEl({
$video,
width = INITIAL_VIDEO_EL_WIDTH,
height = INITIAL_VIDEO_EL_HEIGHT
}:LoadElProps): Promise<HTMLVideoElement> {
const stream = await navigator.mediaDevices.getUserMedia({ video: true });
this._stream = stream;
this._magnification = {
x: width / INITIAL_VIDEO_EL_WIDTH,
y: height / INITIAL_VIDEO_EL_HEIGHT
}
if (!$video) {
const _$video = document.createElement('video');
_$video.muted = true;
_$video.autoplay = true;
_$video.width = width;
_$video.height = height;
_$video.srcObject = stream;
this._$video = _$video;
return _$video;
}
$video.width = width;
$video.height = height;
$video.srcObject = stream;
this._$video = $video;
return $video;
}
次にstart関数ですが、ここで最も重要なのは const detectedRawObjects = await this.model.detect(this.$video); かと思います。ここでは、load関数内で読み込んだ機械学習のモデルと生成したvideoを認識データの元として結合します。awaitedしたdetectedRawObjectsには物体認識の認識結果(座標や物体の種類)が格納されています。関数の終わりにはrequestAnimationFrameでフレームごとに再起的に実行することでリアルタイムで認識結果を取得することができます。またrenderCallBackのpropsを受け取るようにしておくことで、認識結果を使って拡張できるようにします。
async start(renderCallBack?: RenderCallBack) {
if(!this.model) {
console.error('model is empty. you should load model');
return
}
if(!this.$video) {
console.error('$video is empty.');
return
}
const detectedRawObjects = await this.model.detect(this.$video);
this._detectedRawObjects = detectedRawObjects;
if(renderCallBack) {
renderCallBack(this.detectedObjects);
}
this._requestAnimationFrameId = window.requestAnimationFrame(this.start.bind(this, renderCallBack));
}
作ってみよう
下準備が出来たところで実際にメディアアート部分を作っていきます。ディレクトリ構成は以下の通りでです。
/top
- index.tsx
- fragment.frag //GLSL
- const.ts
/DetectorView
- index.tsx // VisualDetectorクラスを使って識別結果を取得し取り回せるようにする
DetectorViewコンポーネント
DetectorViewでは先ほど作ったtensorflowjs/coco-ssdモデルをラップしたVisualDetectorクラスを使って物体認識したのち、その値をもとに画面にインジケーターを移したり親コンポーネントへ認識結果を渡し自由に使ってもらえるようにしたコンポーネントになります。
ポイントはuseEffect内の detector.loadと handleDetect内の detector.startに なります。VisualDetecotorのstart関数ではmodelがない場合startできないようにしてあるので必ずloadしてからstartするようにします。
const handleDetect = useCallback(async () => {
if(detector.$video && detector._$video && detector.model) {
detector.$video.style.position = 'absolute';
detector.$video.style.top = '0px';
detector.$video.style.left = '0px';
detector.$video.style.opacity = `${DETECTOR_OPACITY}`;
$videoContainer.current?.appendChild(detector?.$video);
}
await detector.start((objectList) => {
const objects = objectList
.filter(obj => obj.class === 'person'); // 今回は人のみを対象にするのでpersonでフィルターをかけます。
setObjects(objects);
onDetect(objects);
});
setIsShow(false);
},[$videoContainer]);
useEffect(() => {
const init = async () => {
if(isInit) {
isInit = false;
await detector.load({
width: window.innerWidth,
height: window.innerHeight
});
setIsShow(true);
};
}
init();
return () => {
detector.stop();
}
}, []);
start関数にコールバック関数を渡すことで認識結果をオブジェクトで取得できるので、その結果を親コンポーネントに渡すことで、GLSLのuniformsで扱えるようにします。
このコンポーネント自体物体認識をわかりやすくするためのものなので、本番中はopacity: 0にして使うことをおすすめします。
index.tsx
次に GLSLコードに入る前に、ルートのindex.tsxに入ります。
最終的にはカメラの中に入った人の座標に合わせて後から光の輪っかが追尾するようなメディアアートにします。そのため、機械学習で座標を(DetectorViewにて)取得したのち、フォロワー(光の輪)の座標計算、そのあとuniformsに計算結果を入れることでGLSLにフォロワーの座標を伝える実装にしていきます。
uniformsはtimeとresolutionは大体必須で使います。それに加えてフォロワーの座標x,yを入れておきます。handleDetectの中ではDetectorViewで取得した認識結果を座標計算用のオブジェクトに格納します。useEffectの中では認識結果の座標をもとに、フォロワーの追尾処理をします。
ちなみに、tensorflowjsの仕様上videoタグが初期表示でwindow内に表示されていない場合認識開始処理をしても認識されないのと、シェーダーの表示エリアとDetectorViewの表示エリアを合わせないとフォロワーの位置と計算した座標を合わせづらいので、DetectorViewの位置を調整&見えないようにするため絶対値指定しつつopacity: 0でシェーダー部分と位置を合わせます。
fragment.frag
次にシェーダー部分です
先ほどindex.tsxにて書いたuniformsのxとyを以下で受け取り、取り扱えるようにします。
uniform float time;
uniform vec2 resolution;
uniform float x;
uniform float y;
main関数のなかでは大きく分けると背景と円を描写する部分に分かれます。背景部分では異なるランダムノイズでできたレイヤーを3枚重ねる感じで、以下のような模様を描いています。
float random (in vec2 _st) {
return fract(sin(dot(_st.xy,
vec2(12.9898,78.233)))*
43758.5453123);
}
// Based on Morgan McGuire @morgan3d
// https://www.shadertoy.com/view/4dS3Wd
float noise (in vec2 _st) {
vec2 i = floor(_st);
vec2 f = fract(_st);
// Four corners in 2D of a tile
float a = random(i);
float b = random(i + vec2(1.0, 0.0));
float c = random(i + vec2(0.0, 1.0));
float d = random(i + vec2(1.0, 1.0));
// Cubic Hermine Curve.(3次エルミート曲線) Same as SmoothStep()
vec2 u = f * f * (3.0 - 2.0 * f);
// u = smoothstep(0.,1.,f);
return mix(a, b, u.x) +
(c - a)* u.y * (1.0 - u.x) +
(d - b) * u.x * u.y;
}
#define NUM_OCTAVES 5
// 非整数ブラウン運動(fBM) or フラクタルノイズ
float fbm ( in vec2 _st) {
float v = 0.0;
float a = 0.5;
vec2 shift = vec2(100.0);
// Rotate to reduce axial bias
mat2 rot = mat2(cos(0.5), sin(0.5),
-sin(0.5), cos(0.50));
for (int i = 0; i < NUM_OCTAVES; ++i) {
v += a * noise(_st);
_st = rot * _st * 2.0 + shift;
a *= 0.5;
}
return v;
}
...
vec2 q = vec2(0.0);
q.x = fbm( st + 0.01*time);
q.y = fbm( st + vec2(1.0));
vec2 r = vec2(0.0);
r.x = fbm( st + 1.0*q + vec2(1.7,9.2)+ 0.15*time);
r.y = fbm( st + 1.0*q + vec2(8.3,2.8)+ 0.126*time);
float f = fbm(st+r);
color = mix(
vec3(0.0, 0.7137, 0.7804),
vec3(1.0, 0.8941, 0.3647),
clamp((f*f)*4.0,0.0,1.0)
);
color = mix(
color,
vec3(1.0, 1.0, 1.0),
clamp(length(q),0.0,1.0)
);
color = mix(
color,
vec3(0.9804, 0.3843, 0.9804),
clamp(length(r.x),0.0,1.0)
);
各種ノイズやfbm(非整数ブラウン運動)に関する詳しいことはBook of shaderを参考にしてみてください。
イメージとしては異なるランダムノイズでできたレイヤーを3枚重ねる感じで、以下のような模様を描いています。

次にフォロワー(光の輪)の部分になります。
float times = 2.0;
vec2 center_by(float x, float y) {
return (gl_FragCoord.xy * times - vec2(x, y)) / min(resolution.x, resolution.y);
}
///
vec2 radius = center_by(x * times, y * -times);
// 円の太さ
float bold = abs(sin(time)) * 0.1;
float circle = bold / abs(length(radius) - 0.5);
color += vec3(circle);
center_by関数では円を描くための正規化行い、xとyを中心とした円を描きます。boldはtypescript側で受け渡しているtimeを使って太さを変更しています。円のみの実行結果は以下のようになります。

先ほどの二つのコードをつなげると、画質が荒いですが以下のような感じのものができれば成功です。機械学習の有効化をするために、start_detectのボタンだけは押さないといけませんがそれ以降はずっと人物判定と光の輪が追尾するようになってます。

参考
Discussion