はじめに
Kotoba Technologies, Inc. Co-Founder/CTO、Toyota Technological Institute at Chicago, Research Assistant Professorの笠井淳吾です。これまで自然言語処理(NLP)、機械学習の国際学会(ACL、ICLR、NeurIPS、EMNLP、ICCVなど)にて、投稿や発表を積み重ねてきましたが、一度自分なりに論文を書く際に考えていること、留意点、コツのようなものを言語化して共有したいと思います。個人の好みによるところも多々あるかと思いますので、取捨選択していただいて、皆さんの論文執筆の一助になることを願っています。
全体のストラクチャー
まずは全体の流れから考えていきます。基本的に、論文を書く際には(多くの場合そもそもプロジェクトを始める前に)、タイトルをイメージしていきます。タイトルこそ究極の論文要約であり、一番読まれるものだからです。ちなみにワシントン大学時代のラボメイトであったOfir Pressは、「まず研究プロジェクトを始める前にツイートの内容から考えろ」と言っていました。
Title
タイトルは、まさに究極の論文要約、少し乱暴に言ってしまえば「一言ネタ」だと思います。ここ数年流行っているのは、キーワード(モデル/データセット/手法の名前など)の後にコロンをおき、説明を加えるというスタイルです。有名な論文で言いますと、GLUE: A Multi-Task Benchmark and Analysis Platform for Natural Language Understanding、BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding などが挙げられます。やはり、読者にこれだけは覚えておいてもらいたい、と考える時にキーワードを強調しておくことは有用かと思います。私個人の例ですと、例えばICLR2021に採択された、Deep Encoder, Shallow Decoder: Reevaluating Non-autoregressive Machine Translationでは、とにかくEncoderを多層にして、Decoderを浅くするという非常に単純な手法が、いかに機械翻訳における効率化に役に立つのか、体系的に実験・分析しました。一方で、新しい手法やデータセットを提案するというより、科学的な分析がメインの論文ですと、質問文などが使われたります。If beam search is the answer, what was the question?、Are All Languages Equally Hard to Language-Model? などが挙げられます。私自身、良いタイトルに行き着くまでに苦労することが多く、執筆中に何度もiterateします。国際会議などでタイトルだけでも広くチェックしてみると、面白いですし、勉強になるかと思います。
Abstract
個人的にはAbstractは最初に一通り書いてみて、論文を一通り書き終えてからもう一度戻ってきて修正することが多いです。新しい手法を提案する論文では、We introduce...というのが第一文になる場合を良く見ます。例えば、BERTの論文ですと、We introduce a new language representation model called BERT, which stands for Bidirectional Encoder Representations from Transformers.という一文から始まります。その後、既存の手法との違い、あるいは既存の手法の問題点を指摘し、ベンチマークでのImprovementなどの具体的な結果に踏み込んでいったりします。後ほどのセクションにて実際文章を書いていく上で何度も強調していくポイントですが、基本的な文の流れとしては、抽象から具体ということになります。最初に抽象的に、「こういう手法を提案します。既存の手法のこういう問題を解決しました」と表明しておいて、結果という形で具体的な証拠付けをしていきます。もちろん、We introduce...という形で始まる必要はなく、問題提起から入っていくパターンもあります。例えば拙著、Selective annotation makes language models better few-shot learners (ICLR 2022)においては、This work examines the implications of in-context learning for the creation of datasets for new natural language tasksという問題意識から議論を始めていきました。新しい手法なのか、新しいフレームワークなのか、どういった問題意識を持っているのか、まずはしっかり抽象的に言語化してから書いていくと流れとしては良くなっていくと思います。
Introduction
ここまでは要約要素が強い部分でしたが、いよいよ中身に入っていきます。まずはIntroが勝負です。Introを読み終わった時点で、大抵のReviewerは査読スコアをある程度決めている、あるいは読者はその後読み進めるかどうか判断している、という傾向は間違いなくあるでしょう。Introでは、読者に現状に対するfrustrationであったり、問題点であったり、研究のモチベーションとなる気持ちを共感してもらうのが目標となります。
最初の(最も重要な)勝負: Figure 1
何はともあれ、「Figure 1」が重要になってきます。 ACL系(ダブルコラム)の論文ですと、1ページ目の右上に、Figure 1という形で読者にイメージを持ってもらう場合が多いです。もちろんFigureが1ページ目にない論文もありますが、論文やプレプリントで溢れる昨今、1ページ目でしっかり読者の心を掴むことが重要になってくることは間違いないかと思います。過去に共著したこともある、ワシントン大学のYejin Choi先生がおっしゃっていたことなのですが、Figure 1では、"most cherry-picked example"(最もよい例を選ぶ)を選ぶと効果的であったりします。科学的な論文としては、cherry-pickというのはむしろマイナスにとられがちですが、ことFigure1、最初の導入という意味では、一理あるかと思います。
実は私は文章を書くのに比べ、デザインやFigureを作るのは苦手意識があるのですが、Allen Institute for AIでインターンしている際、メンターの坂口先生(現東北大学准教授)に相当鍛えられました。まず、デザインの基本としては色は少なめに、また読者の動線をある程度把握していく必要があります。坂口さんとの共著論文(Transparent Human Evaluation for Image Captioning、Bidimensional Leaderboards: Generate and Evaluate Language Hand in Hand), NAACL 2022)を例にとって見てみましょう。

まず、最初の論文に関しては、image captioniningの従来の評価方法の問題点を如実に表す例を出しました。こちらでは、hydrantと虹が出ているImageを取り上げ、従来の評価方向が「虹」のような珍しい現象を適切に反映することができないという指摘しています。また、右側の図では、新しいリーダーボード、評価方法のフレームワークを提案し(従来と違い、評価軸も動的に変わっていく)、リーダーボードの参加者としての視点を例示しました。このようにすることで、読者にユーザーとしての視点を持ってもらい、自分が提出するファイル(metric.py, text.out)や参加結果がどのように反映されるのか、一目瞭然になるようにしました。従来のリーダーボードフレームワークとは違い、評価軸の方も参加可能のベンチマークで、この図からもわかるように二次元のリーダーボードとなっています。また色合いに関しても、若干"機械感"の出る緑と紫の色合いを選びました。
最後に、新しいembedding methodを提案した論文のFigure1も見てみます。One Embedder, Any Task: Instruction-Finetuned Text Embeddings (Findings of EMNLP 2022)からの抜粋になります。
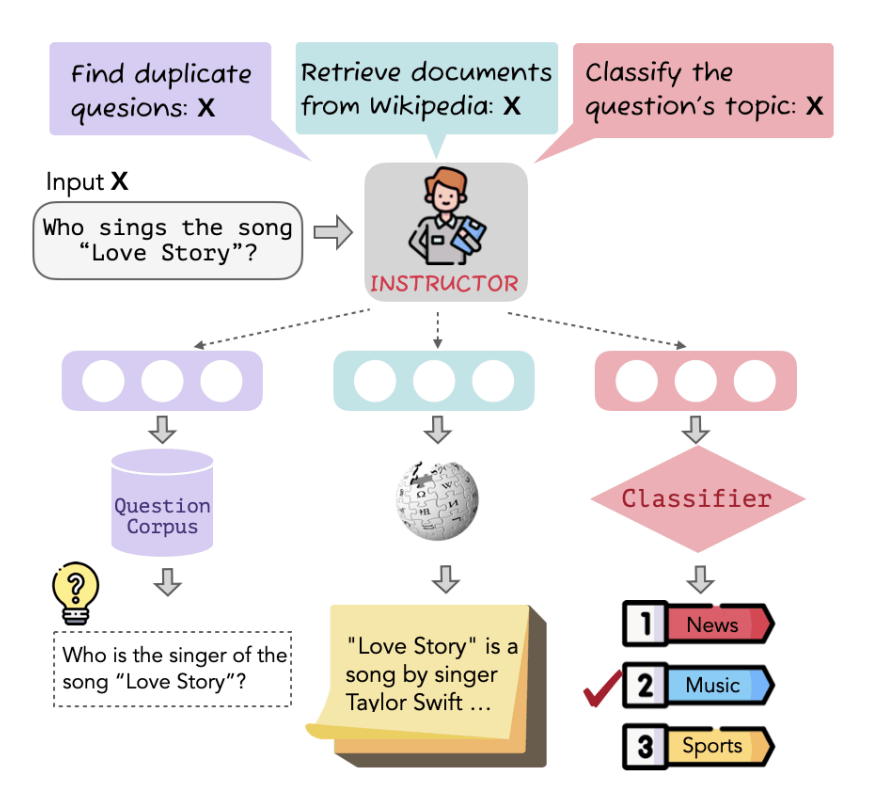
こちらは研究者やスタートアップなどを含め、すでにHuggingFace Transformers上で200万回以上のダウンロードをされているモデルなのですが、従来のEmbedding Methodと違い、自然言語を挿入することで、タスクや目的ごとにEmbeddingを柔軟に変えていくという手法を提案しました。こちらの図では、まずこのEmbeddingモデルは複数のタスク(Retrieval, Topic Classificationなど)に対応しており、なおかつそのタスクに合わせて柔軟に対応できるということを例示しました。Embeddingは至る所で使われているのですが、従来ではタスクごとに別々のEmbeddingを作っていくのが主流です。このInstructorという手法により、新しいタスクに簡単に自然言語を使ってAdaptできる方法を開発しました。このFigureでは、まさにこの肝の部分を視覚的に例示したものとなっています。
最初の二段落(読者の共感、カタルシス)
論文で溢れる昨今、Figure1のような視覚情報が重要なのは疑いの余地がありません。とは言っても、やはり論文である以上、研究内容を言語化し、読者と共有することは重要でしょう。ここで重要だと思うのは、まずはしっかり読者に共感させ、場合によって現状に対するfrustrationや問題点を的確に指摘し、カタルシスのようなものを与え、幸せな気持ちになってもらいたいという点です。先ほども触れた、Bidimesnaional Leaderboardの例を見てみましょう。まずは第一段落です。
Recent modeling advances have led to improved natural language generation in applications such as machine translation and summarization... This progress is typically measured with automatic scores, such as BLEU and ROUGE, executed by modeling researchers themselves...
まずは現状について読者と一緒に確認していきます。言語生成はこの数年かなりの進歩を遂げていて、重要な問題だと考えられる。そしてその進歩の評価方法として、BLEUのような一般的なメトリックがある。ここまではあくまで読者に一体何の話をしているのかを伝え、読者にも「うんうん、そうですね」と頷いてもらうイメージです。
そして第二段落に移っていく際に一気にギアをあげます。Meanwhile, many evaluation metrics that improve correlation with human judgments have been proposed, but this progress has yet to be broadly adopted by the community of researchers focused on advancing models.「あれ、確かにMetricを使うけども、ずっと古いの使っているよね、新しいMetricだって本当は出てきているよね」、こういった違和感を言語化していきます。いきなりこの段落から始めるのではなく、最初の段落があることで、読者が置いていかれづらくなります。また、第二段落であるため、読者が退屈することもある程度は避けられるでしょう。これらを考慮して、私の場合第二段落〜第三段落にギアチェンジすることが多いです。
もう一つ、前述のOne Embedder, Any Task: Instruction-Finetuned Text Embeddingsの例を見てみましょう。Method論文ということで、論文自体の毛色は異なりますが、基本的に同じやり方をしているのがわかるかと思います。
Text embeddings represent discrete text inputs (e.g., sentences, documents, and code) as fixed-sized vectors that can be used in many downstream tasks...
最近の手法は基本的にEmbeddingを使いますよね、と確認を行います。ここまではある程度の知識がある読者なら、「ふむふむ、そうですね」となるわけです。そして第二段落で一気に自分たちのテーマと問題意識に舵を切っていきます。
However, most existing embeddings can have significantly degraded performance when applied to new tasks or domains... we hypothesize that text embeddings (even for the same text input) can be adjusted to different downstream applications using task and domain descriptions, without further task- or domain-specific finetuning.
さて、それではなぜEmbeddingモデルはタスクごとに必要なのでしょうか?その疑問点で第二段落は始まっていき、最終的に我々のHypothesis(目標)を明確にします。ここではそういったEmbeddingモデルをタスクごとに作っていくのではなく、自然言語での指示文を挿入することで、簡単に色々なタスクやドメインに特化させる手法を考えていくよ、と主張していきます。
他の論文でもこのような手法は少なからず使われておりますので、お気に入りの論文でぜひ確認してみてください。Introの最初の二段落は、やはり読者の共感を掴んでいくことを目標にしたいです。
論文のロードマップ
Introの最後の数段落では、ある程度のロードマップを与えることで、読者に適切なExpectationを持ってもらいます。 過度な期待もよくないですし、過小評価されてももったいないところです。基本的に、驚きというのはIntroで全て消化しておき、残りのセクションでは期待通りの流れに持っていくのが理想だと思っています。もちろん、論文を評価したり、読む上でどのような驚くべき結果があるのか、どのような驚くべき手法を提案するのか、といったところがキーになることは多いですが、Introの後に驚きをとっておくのはリスキーです。読者にはIntroでしっかり驚いてもらい、あとは科学的なベンチマークがきちんと行われているか、データセットは何か、数式は正しいのかといった、確認作業に焦点を絞ってもらうのが得策でしょう。読者にマルチタスクを要求するのは難しく、またセクションごとに読む目的をはっきりさせたいという意図があります。一つのやり方として、Key Findingsのようなものを箇条書きにするパターン(例、BERT論文)や、後ほどのセクションがどのように構成されているか説明していくパターンがあります(... (§4.1)... (§4.2)など)。この辺りは論文によって使い分けるのが良いのかな、と思います。箇条書きはFindingsが明確にできる場合には最適ですし、Sequentialに分析や議論を進めていく場合は後者が有効になります。
以上を踏まえて、ロードマップを書いていきます。「Introの後はこのロードマップに従って書いていくので、驚かないでね、お願いだからついてきてね」、と読者に伝えるわけです。
Method/Framework/Dataset/Experiments
さて、Introまでかけてしまえば、論文はもう9割終わったも同然です。 私の場合、これ以降の部分は時間をかけずに一気に書いてしまいます。実は面倒なので、主著の場合、共著者とミーティングを行う際はスライドなどを作らず、Method Sectionを直接書いてアップデートしていました笑。まず、驚きや意外性をすでに消化しているので、後はロードマップに従ってある程度機械的に書くだけになります。
一点心掛けていることとしては、Sectionごとにしっかりとロードマップを書いていくことです。Sectionの始まりの段落で、しっかり読者に「このSectionではこういう話をしますよ、だからここに気をつけて読んでね」、と伝えていくことを心がけています。繰り返し恐縮ですが、拙著の例を見ていきましょう。(Selective annotation makes language models better few-shot learners)
In-context learning only requires a few annotated examples per test instance (few-shot learning), while avoiding expensive finetuning on the whole training data... We formulate a general framework that consists of two steps: selective annotation (§2.1) and prompt retrieval (§2.2).
しっかりこのセクションでは何が起こるのか伝えておきます。繰り返しになりますが、ここまでくると驚きは存在しません。
Method/Experimentsセクションで気をつけていることなど、細かい部分はあるのですが、今回は情報過多を避けるため、割愛します。ご希望があれば別の記事まとめたいと思います。
Related Work
PhD AdvisorのNoah Smithとも一度議論したことがあるのですが、Related Workの原則としては、本当に深くRelatedな論文なら、Related Workではなく、IntroやMethod Sectionなどですでに触れているべき、と考えています。 Related WorkをIntroのすぐ後ろに置くスタイルもあったりしますが、こういった理由から個人的には一番最後に置く方がしっくりきます。機械学習、ACL系の論文では、Related Workを一番最後に置くパターンのが主流だというのが今まで読んできた中での肌感です。
心がけていることとしては、リスト引用など、長くなりがちではありますが、できる限り自分の論文との関連性、相違点、類似点に必ず戻ってくるようにまとめるということです。ただRelated Workを並べるだけでは、やっつけ仕事のように映ってしまいます。(とは言っても査読者に指摘されてやっつけ仕事として引用を増やすことも頻繁にありますが笑。)できる限り論文を分類していき、自分たちのワークとの関連性、相違点を明確に言語化したいところです。例えば、拙著NeurIPS 2023、RealTime QA: What's the Answer Right Now?のRelated Workセクションを見てみてください。自分のWorkに戻ってくるという点、またRelated Workを完璧ではなくともある程度カテゴライズして議論している雰囲気が伝わると幸いです。
便利な表現
-
Departing/Different from <describe/name a previous approach>, we...Related Work Sectionに限りませんが、他のWorkと比較する際、この表現は非常に便利です。一体今までの手法と何が違うのか、端的に伝えることができます。Divergingといった表現もあるにはありますが、若干Negativeなコンテーションがあるので、利点を説明するときにはあまり向かないかと思います。 -
Similar to <読者の知っていると予想されるもの・前述のもの>, ...こちらは類似点を指摘するときに非常に便利な表現です。また、読者の知っていそうなことと関連づけることで、「そんな変なことやってるわけではないですよ。安心してね。」と読者に安心してもらう効果もあると思います。
文章の書き方、段落の構成方法
ここまでが論文のストラクチャー、マクロな部分での話でしたが、最終的には一文ずつ書いていき、論理構成をしていくことになるわけです。その際、いくつ重要なポイントを言語化していきます。
抽象から具体
まずは文章構成の大原則から話しますと、抽象から具体です。英語論文ではこれが基本になります。まずは段落の一文目で抽象的に最も重要な情報を与え、それを具体化していくという作業になります。例を挙げればキリがないですが、例えば、RealTime QA論文において、We evaluate six baselines both in multiplechoice and generation settings in real time...と段落を始めていき、具体的な結果をReportしていきます。まさに、抽象から具体になります。また分析の部分でも、We conducted a manual error analysis of the results so far. In particular, we categorized answers from the best generation model (open-book GPT-3 with GCS) into three categories:...のように、最初に抽象的に何をやったかを説明し、その具体的な詳細を説明していきます。
便利な表現
抽象から具体を組み立いくうえで、便利な表現がいくつかあり、私も多用しています。
-
In particular前文で述べた抽象的な内容を具体に落とし込む表現です。理系の講義やトークなどをする際、教授がよく使う表現だったりもします。非常に便利です。 -
At the core of sth are/is...次の具体的な説明を加える前に、まずは抽象的にモチベーションや根幹部分を伝える表現になります。倒置表現でもあるため、個人差はあるかと思いますが、cognitive loadが通常の文章より高くなるため、ここで目線が若干止まることになります。重要なモチベーションや根幹部分を伝える上で、重宝できる表現です。 -
..., thereby ~ing...前の部分でやったことのモチベーション、「なぜ」や具体的にどのような意味があるのか、という流れを作っていく表現になります。
予告、伏線、期待値管理
繰り返しになりますが、基本的にIntroで驚きを全て消化していくわけなので、しっかりと予告や伏線をはっておき、読者の期待値を正確に設定していきたいところです。その際に便利な表現もいくつかあり、私自身多用しています。
便利な表現
Indeed,..「やっぱりそうなるよね」という気持ちを表す表現になります。「はい、あなたが予想した通りでしたよ、安心してね」ということです。
As our later analysis shows...後で書くのに、どうしてこのように書かないといけないのか、と思われるかもしれません。しかし、「後ほどこういうAnalysisをやるから焦らないでね」と、読者(査読者)を安心させる効果があると考えます。
Consistent with sth, ...前の結果やPrior Workと一致してますよね、と確認しておくことで、しっかりと期待した結果であることを述べます。
Table/Figure Captions, Citations
最後に細かいところになるのですが、神は細部に宿るということで、Table/Figure CaptionsやCitationsで気をつけている点をシェアします。
- Table/Figure Captionはできる限りself-contained(それだけで完結しており、Captionだけ読むだけで理解できる)状態にすることを心がています。査読者もそうですが、色々な読者がいるわけで、TableやFigureだけさらっと(まずは)確認する読者はたくさんいます。また、上から下まで丁寧に読んでいく査読者であっても、目線を動かした先に必要情報があって損することはありません。もちろん字数制限との兼ね合いはありますが、本文からクロスレファレンスしなくてもそれだけで理解できるようなCaptionを心がけています。
- Citationsはリストの場合一番重要なものから、乃至は時系列順序に並べることを意識しています。また、ACL系の論文の場合、
\citet{}: Kasai et al., (2023)と、\citep{}: (Kasai et al., 2023)の二つの区別をしっかりしておきましょう。前者は文章中で触れる場合(例:Kasai et al., (2023) argue that...、後者は括弧で挿入するパターンです。正直あんまり気にする必要はないとは思いますが、査読者がどこでイラつくかはわかりません!
最後に(アメリカのWriting教育は"型はめ"である)
私自身、日本の高校卒業後、アメリカのイェール大学に進学し、その後ワシントン大学でコンピュータサイエンスPhDプログラムに進学しました。アメリカでの教育を学部から10年近く受けて感じることは、Writingは型にはめるという基本的な考え方があるということです。日本ではどちらかというとWritingとは文才といった個性の出る場所、という認識が強いかもしれません。アメリカの学部教育では、Science、Humanities、Social Science、どの分野であっても、Writingはコミュニケーションの基盤であると考えられ、イェール大学をはじめ必修科目となっている大学が多い印象です。私自身、学部で相当鍛えられた結果、今があります。面白いことに、私もアメリカの学部生の研究をメンターする機会が何度もありましたが、ネイティブスピーカーである彼らの書いてきた草稿を、一から書き直す経験が何度もありました。もちろん単語の選び方、Vocabularyの豊富さなどではネイティブスピーカーには太刀打ちできないかもしれませんが、Writingは母国語云々に関わらず、鍛える必要がある(鍛えることができる)スキルではないかと思います。最初は良いと思った論文や著者の真似をしながら、論文執筆を通してどんどんスキルを磨いていきましょう!
不明点、ご質問などあれば、jkasai@kotoba.techまで気軽にご連絡ください。

Discussion