マルチモーダルLLMは本当に文字認識できてる?
どうでもいい前書き
「わっちが学生の頃はな…… LLMなんて無かったんじゃよ」
最近仕事をやめ、次職の勉強などをしつつそんな心の声が気になっていた今日このごろ。
仰げば尊し血反吐を吐きながら書いていた英語論文、今や学生の間ではそれほど大きな障壁にならないのかもしれない。
ともすればLLM普及期の学生が苦労することは何なのか、もはやレポートの提出に遅れるのは想像を絶する怠惰なのだろうか、ChatGPTに課金できない貧困があるのだろうか、あるいは技術を超えたはるか先、起床という問題なのだろうか、どうして4月になろうというのにこんなに寒いのか、、、
混濁する思考の中、つまるところ自分もLLMにチヤホヤされる研究体験がしたかったのだ、という願望に気づき、無職最後の5人日で問題仮説の立案、実験計画と実行、論文化してarXiv投稿までをやってみた話。
20250401: 無事arXivに公開されました
マルチモーダルLLMは本当に文字認識できてる?
最近見た記事にGemini2.0がOCR界隈のゲームチェンジャーというものがあります。
記事を見ると既存のOCR特化サービスであるAWS TextractのパフォーマンスよりもGemini2.0の方が良いという……ほぅ。
事実であればこれは驚愕すべきことで、タスク特化のモデルよりも大量の画像&文章ペアを学習したマルチモーダルLLMの方が良いということは、餅屋が作る餅よりもパン屋が作る餅の方が美味しいということ。食べたい。
TL;DR
- マルチモーダルLLMでは文字認識と文章生成がエンドツーエンド(一気に実行)なのでそれぞれの精度評価が困難
- 文脈推論が困難な単体文字認識タスクを設計すれば前者の文字認識性能が見えてくるはず
- GPT-4o, Gemini, そして既存のOCR特化モデルとしてAzure OCRのパフォーマンスを比較
- GPT-4o, Geminiは300ppi程度の高解像度スキャン画像であれば既存OCR特化モデルと同等精度
- 150ppi以下の場合はマルチモーダルLLMの識字性能は極端に低下するが、Azure OCRのパフォーマンスは低下しない
詳細は論文形式でまとめているので、気になる方はご覧ください。
マルチモーダルLLMのOCRの評価は難しい
皆さんは次の一部が隠された画像をみてテキストを書き出すとするとどう書くでしょうか?

ラーメンとラーヌンの一部が隠された画像
おそらく良い感じに推論して「ラーメン」と「ラーヌン」、あるいは「ラー◯ンとラー◯ン」みたいに不明なところを空欄にするのではと思います。
ちなみにChatGPTでGPT-4oを使うと

「ラーメン」と「ラーメーン」という結果になりました。 ChatGPTでは前の文章のコンテキストが維持されるやろがい!というお叱りはごもっともなので、新しいスレッドで逆の順番でやると…

「ラーメン」と「ラーソン」になります。カオス…
ここで問題にしたいことは、OCRのタスクの中のどこで間違えたのか?ということです。
- そもそもマルチモーダルLLMにとって文字認識できる程度の情報が画像から得られていないのでは?
- 文字認識はできていたが、文章生成の段階でハルシネーションが起きたのでは?
エンドツーエンドでの実行なので、そもそもこれらの要素は不可分という議論もありますが、とはいえプロダクトでの運用などを考えると、少なくとも前項の「文字認識できる程度の情報はあった」状態を担保しなければいけません。
文字認識精度の評価データセットを作る
では文章生成の段階を極限まで省き、単体の文字認識をすればよいのでは?という話になります。やってみましょう。
ここで評価用の画像をどうすべきか?という問題がありますが、常用漢字の中から文字構造の複雑さを一様に網羅した100文字を選定することとしました。 理由としては2つあります。
- マルチモーダルLLMの学習に少なくない数が存在すると推定される(知らない文字を認識することは別問題になる)
- アルファベットより文字形状に多様性があり、文字認識の難易度が定量化しやすい
文字認識の難易度はフラクタル次元とエントロピーの積から計算し、常用漢字2136字をこの難易度でソートした結果から均等間隔で100文字を選定しています。

評価用の漢字データセット
選定した結果は画像に示す通りで、"一"のようなシンプルな文字もあれば、"懸"のような複雑な文字もあります。ちなみに常用漢字で最も文字構造が複雑なのは"鬱"です。鬱ですね。
実験結果
文字認識精度
複数解像度でのGPT-4o, Gemini, Azure OCRの精度評価結果を比較すると以下のようになります。

各解像度におけるOCR精度の比較
Resolutionの40, 20, 15, 10pxはそれぞれ300, 150, 112.5, 75ppiに相当します。
結果からGeminiがOCRに優れるということに嘘はなく、300ppi相当の解像度ではOCR特化モデルと同等の精度を示しています。
しかし150ppi以下の場合はGPT-4o, Geminiの識字性能は極端に低下します。
誤認識の最も高いGPT-4oでいかなる解像度にもかかわらず誤認識する文字は、"一", "揮", "脅", "緊", "懸", "顧", "栽", "晶", "逝", "戚", "捜", "誕", "墜", "丼", "阜", "紛", "噴", "蔑", "頬"の19文字あり、なんとなく難しい形状のものが多いような気がします。
ただ"一"や"丼"のように文字の構造が単純なものも含まれており、それぞれの誤認識結果を確認すると
- "一"がハイフンへ誤認識
- "丼"が別の常用漢字である"井"へ誤認識
前者の"一"は気持ちがわかります。後者のわずかに形状が異なるが別の漢字というのは300ppiあっても文脈の補助なしでの正解は難しいかもしれません。
文字の複雑さは誤認識に影響している?
直感的には"鬱"のような複雑な形状をもつ字は誤認識しやすい気がします。
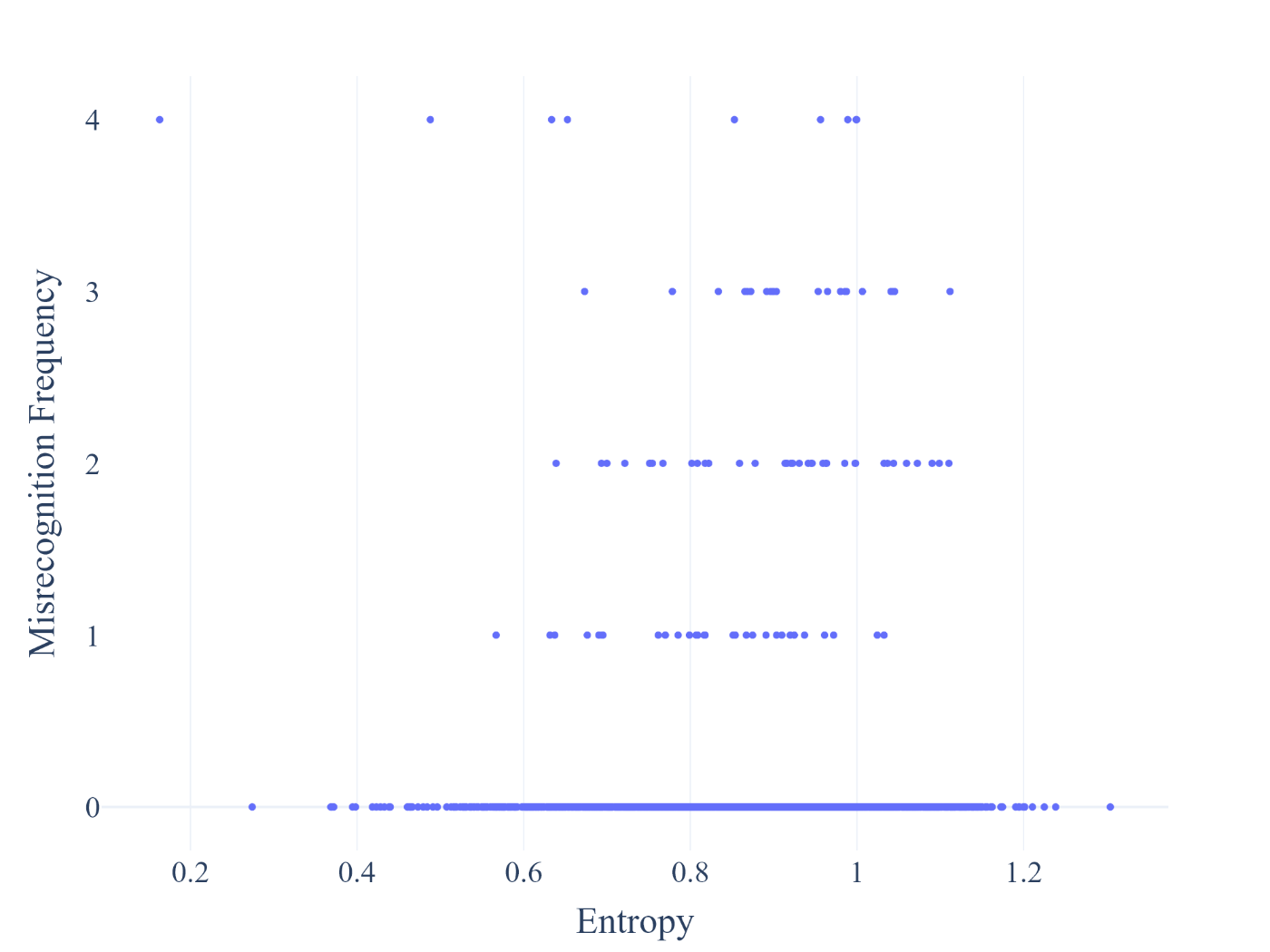
誤認識の回数と文字ごとの複雑度でプロットして確認してみましょう。
| モデル | フラクタル次元 | エントロピー |
|---|---|---|
| GPT-4o |  |
 |
| Gemini |  |
 |
| AzureOCR |  |
 |
横軸にフラクタル次元あるいはエントロピー値、縦軸に誤認識回数をプロットしており、散布図のプロットが全体的にやや右上へと偏っていることがわかります。
上に行くほど誤認識回数が多く、右に行くほど文字の複雑さが高いことを表しているため、直感はあっていそうです。
誤認識回数1回以上の文字を対象に、誤認識回数とフラクタル次元およびエントロピーとの相関を計測した結果をは表の通りで、フラクタル次元で判断すると非常に弱い相関ながら関係がありそうなことがわかります。
| モデル | フラクタル次元相関 | エントロピー相関 |
|---|---|---|
| GPT-4o | 0.281 | 0.150 |
| Gemini | 0.172 | 0.037 |
| AzureOCR | -0.031 | -0.116 |
まとめ
文章ではなく単体の文字認識というOCRタスクを設定することで、マルチモーダルLLMの純粋な文字認識性能を探ろうという試みを実施し、次の傾向を確認しました。
- Gemini2.0のようなマルチモーダルLLMは一般的なドキュメントスキャナーの解像度(300ppi)では既存のOCR特化モデルと同等の文字識別性能がありそう
- 150ppi以下の場合はマルチモーダルLLMの識字性能は極端に低下するため、OCR特化モデルとの併用が必要になるかも
視覚エンコーダを含む実装が公開されたマルチモーダルLLMの動作を確認すれば更に上記現象の原因を探ることができそうなので、だれかy⋯ 今後の課題ですね。
LLMにちやほやされる研究活動を振り返って (蛇足)
今回は次のような手順で研究が遂行され、全体を通して約5人日で簡単な日英の論文を完成させることができました。
- 過去の研究を調べる
- 問題の設定
- 実験計画案を立てる
- プログラムの大枠作成
- プログラムの修正&加筆
- 実行結果のレビュー
- 図表の作成
- 日本語論文原稿をmarkdownで作成
- 日本語論文原稿をLaTex化
- 日本語論文の英訳
- 英訳論文のレビューと修正
- 論文タイトル決め
また明確な境界は曖昧ですが、各ステップの主たる役割分担は以下のようになります。
- 人
- 問題の設定
- 実験計画案を立てる
- プログラムの修正&加筆
- 日本語論文原稿をmarkdownで作成
- 実行結果のレビュー
- 英訳論文のレビューと修正
- 論文タイトル決め
- Cline&Cursor
- プログラムの大枠作成
- 日本語論文原稿をLaTex化
- 図表の作成
- ChatGPT
- 過去の研究を調べる (DeepResearch)
- 日本語論文の英訳
私のLLM使いこなし力が足りないかもしれませんが、まだまだ人の担当する作業は多いです。
しかし体感としては私が博士課程学生だった頃からすると圧倒的に楽になっており、Cline&CursorとChatGPTが無ければあとプラス3~4人日はかかっていそうな気がします。
一方で、LLM系サービスを利用して何度と無く痛感することですが、各種サービスはできる人が更にできるようになるだけという認識に変わりはありませんでした。
学生さんのレポートや研究の進捗が芳しくないことがあるとすれば、やる気を除いて「できる」状態までのサポートが足りないということでしょう。
英語論文の方は試しにarXivには現在提出中で、チェックが無事通過すればURLを掲載します。→ 公開されました
Discussion