物体検出モデルで忘れ物防止システムを作る
Jetson Nanoを使って忘れ物防止システムを作りました。
💡きっかけ
小物(財布やBluetoothイヤホン)を忘れて、外出することがあります。
それを防止するシステムをつくれないかと思い作りました。
⚙概要
動作の流れ
以下の流れです。
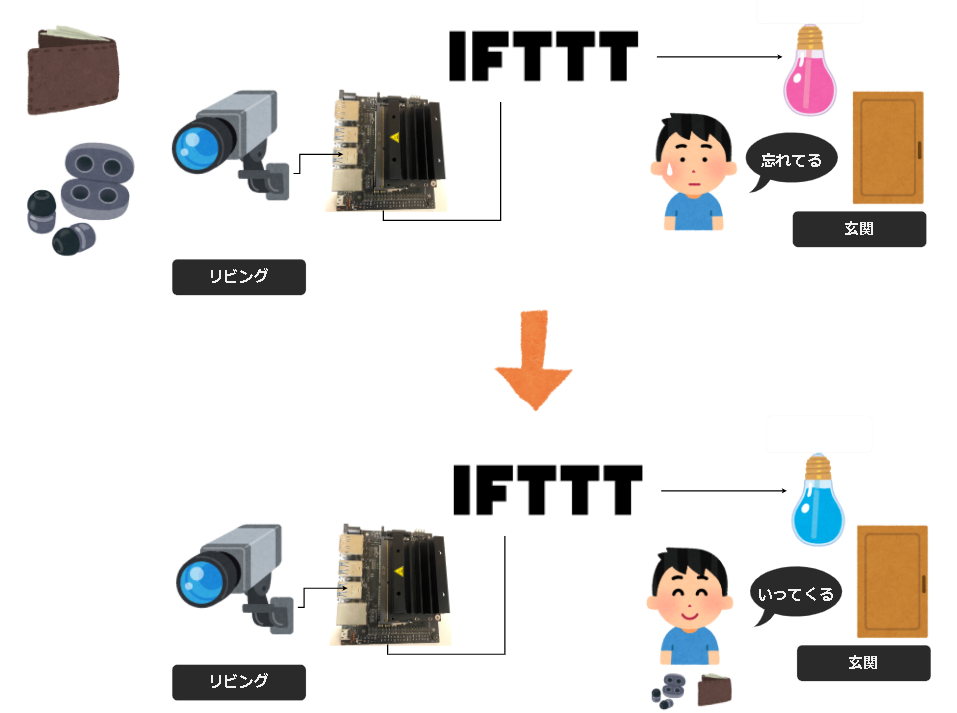
- Jetsonからwebカメラから小物を撮影する
- 撮影した画像から、物体検出モデルを使い推論する
- 推論の結果から、玄関にあるライトの状態を変更する
- 小物がない場合、ライトを赤くする(忘れているの状態)
- 小物がある場合、ライトを消灯する(忘れていないの状態)
外出する直前で、気づきを与えることで忘れ物を防止します。
作業の流れ
以下の手順で行いました。
- JetsonNanoのセットアップ
- 独自の学習データを作成
- 学習を行う
- 検出を確認する
- システムをつくる
🔧パーツ一覧
| no | 部品名 | 個数 | 備考 |
|---|---|---|---|
| 1 | Jetson Nano | 1 | 4GB版, JetPack6.1で確認 |
| 2 | Webカメラ(ロジクールC270n) | 1 | Amazon |
| 3 | スマートLED電球 | 1 | Magic Hue WiFi スマート LED電球 |
💻JetsonNanoのセットアップ
SDカードイメージのダウンロード/書き込み
詳細手順については、公式サイト↓に記載されています。
ここでは、簡単な概要を記載します。
下記のページより、SDカードイメージをダウンロードします。
今回、JetsonNano(4GB版)を使用するため、下記が該当します。
JETSON NANO DEVELOPER KITS >
For Jetson Nano Developer Kit:
Follow the steps at Getting Started with Jetson Nano Developer Kit.
現時点では、JetPack 4.6 (L4T R32.6.1)が最新となります。
書き込みツールには、以下のものがあります。
開発環境(docker)および必要ファイルのインストール
HELLO AI WORLDのレポジトリをベースに環境構築を行います。
本レポジトリで提供されているDockerを使用する方法が簡単です。
構築手順は、下記を参照願います。
作業手順は下記となります。
$ git clone --recursive https://github.com/dusty-nv/jetson-inference
$ cd jetson-inference
$ docker/run.sh
独自の学習データを作成
物体検出モデルは、SSD-Mobilenetを使用します。
MobilenetSSDは、画像から物体のバウンディングボックスとカテゴリを計算するモデルです。
学習用のスクリプトなどは、PyTorchでポーティングされている下記のレポジトリを使用します。
また、HELLO AI WORLDのレポジトリには、学習の手順および自前のデータセットの作成の仕方が記載されています。
- 学習手順の例 - フルーツの学習
- 自前データセットの作成手順
データセットの構造
学習用のスクリプト("train_ssd.py")を使用するために、下記のようにデータセットを配置する必要があります。
| ディレクトリ名 | 内容 | 備考 |
|---|---|---|
| ./Annotations | アノテーションデータ- voc形式 | xml形式のデータ |
| ./ImageSets/Main | train.txt, val.txt, trainval.txt, test.txt | 各フェーズで使用するデータのファイル名が記載 |
| ./JPEGImages | 画像データ- JPEG | JPEG形式のデータ |
独自の学習データ支援ツール
↑で記載されている自前データセットの作成手順を行うことで、データセットを作ることが可能です。
ただ、実際にやってみると思っていたよりも時間がかかることが分かりました。
もう少し効率的にできないかと考え、突貫で支援ツールを作成しました。
以下のような感じです。
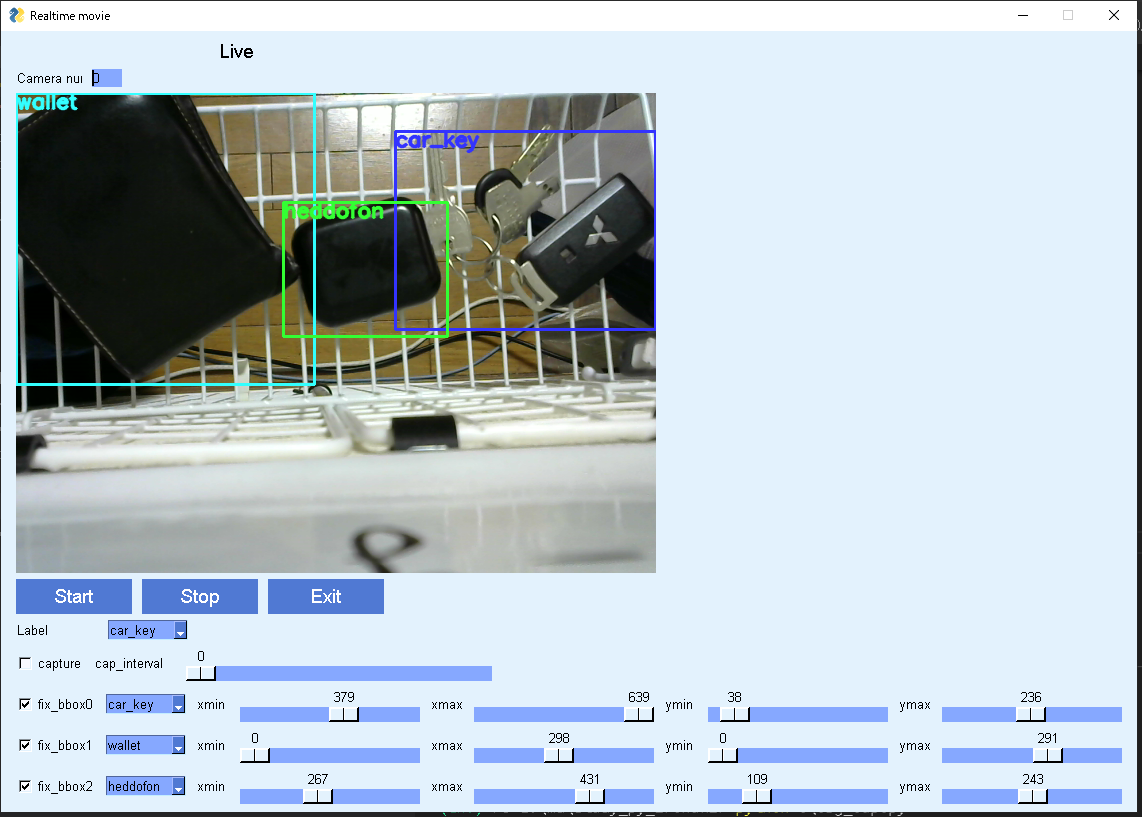
財布や鍵などの小物を位置をずらしたり、背景を変えたりしながら、アノテーションデータと画像データを作成しました。
最終的には以下のように、データとなりました。
| 種別 | 枚数 | 備考 |
|---|---|---|
| train | 246枚 | train.txt, trainval.txtに記載 |
| valitation | 82枚 | val.txt, trainval.txtに記載 |
| test | 82枚 | test.txtに記載 |
学習を行う
学習は、GoogleサービスのColaboratoryを使用しました。
Colaboratoryより、自身のGoogleDriveをマウントします。
必要なデータは、下記に配置および出力されることを前提に説明します。
| パス | 内容 | 備考 |
|---|---|---|
| ./ | Googleドライブのルート | - |
| ./pytorch-ssd | 学習/変換スクリプト | !git clone https://github.com/dusty-nv/pytorch-ssd.git |
| ./pytorch-ssd/data/sikou | データセット | Annotations, ImageSets/Main, JPEGImagesを配置 |
| ./pytorch-ssd/models/mobilenet-v1-ssd-mp-0_675.pth | 学習済みデータ | 学習の最初の重みとして使用する(https://storage.googleapis.com/models-hao/mobilenet-v1-ssd-mp-0_675.pthよりダウンロード) |
| ./pytorch-ssd/models/sikou | 学習結果の格納先 | 学習実施前は、空のディレクトリ |
学習実施のコード
学習実施のコードは以下となります。
また、Jetson(TensorRT)で推論を実施するために、ONNX形式に変換します。
以下は、Colaboratory上で実施しています。
from google.colab import drive
drive.mount('/content/drive')
# =>Google Driveをマウント
!pwd
# /content
!cd drive/MyDrive/
!git clone https://github.com/dusty-nv/pytorch-ssd.git
# =>./pytorch-ssd が配置
# =>独自のデータセットを./pytorch-ssd/data/sikouに配置
# =>mobilenet-v1-ssd-mp-0_675.pthを./pytorch-ssd/models/に配置
# =>./pytorch-ssd/models/sikouを作成
!cd pytorch-ssd/
!pip3 install -r requirements.txt
# =>必要なモジュールをインストール
!python train_ssd.py --dataset-type=voc --data=data/sikou/ --model-dir=models/sikou/ --batch-size=4 --epochs=200
# 2021-11-20 06:24:28 - Using CUDA...
# ...
# 2021-11-20 07:20:00 - Epoch: 199, Step: 80/82, Avg Loss: 0.8338, Avg Regression Loss 0.1625, Avg Classification Loss: 0.6712
# 2021-11-20 07:20:02 - Epoch: 199, Validation Loss: 0.1921, Validation Regression Loss 0.0548, Validation Classification Loss: 0.1372
# 2021-11-20 07:20:02 - Saved model models/sikou/mb1-ssd-Epoch-199-Loss-0.19206559676222684.pth
# 2021-11-20 07:20:02 - Task done, exiting program.
!python3 onnx_export.py --model-dir=models/sikou/
# Namespace(batch_size=1, height=300, input='', labels='labels.txt', model_dir='models/sikou/', net='ssd-mobilenet', output='', width=300)
# running on device cuda:0
# found best checkpoint with loss 0.069102 (models/sikou/mb1-ssd-Epoch-108-Loss-0.06910200616935404.pth)
# creating network: ssd-mobilenet
# num classes: 4
# loading checkpoint: models/sikou/mb1-ssd-Epoch-108-Loss-0.06910200616935404.pth
# ...
# %boxes : Float(1, 3000, 4, strides=[12000, 4, 1], requires_grad=1, device=cuda:0) = onnx::Concat[axis=2](%442, %448) # /content/drive/My Drive/pytorch-ssd/vision/utils/box_utils.py:209:0
# return (%scores, %boxes)
# model exported to: models/sikou/ssd-mobilenet.onnx
# task done, exiting program
# =>学習済みモデルが ./pytorch-ssd/models/sikou/ssd-mobilenet.onnx に配置されている
# =>使用したラベル情報が ./pytorch-ssd/models/sikou/labels.txt に配置されている
検出を確認する
上記の学習時に作成された
- ssd-mobilenet.onnx
- labels.txt
をJetsonに転送し、下記に配置します。
- ./jetson-inference/data/sikou/ssd-mobilenet.onnx
- ./jetson-inference/data/sikou/labels.txt
Jetsonにキーボード/マウス/モニタをつないで、ターミナルより以下を実施します。
$ ./docker/run.sh
reading L4T version from /etc/nv_tegra_release
L4T BSP Version: L4T R32.6.1
[sudo] password for xxx:
...
/jetson-inference# cd data
/jetson-inference/data# detectnet.py --model=sikou/ssd-mobilenet.onnx --labels=sikou/labels.txt --input-blob=input_0 --output-cvg=scores --output-bbox=boxes /dev/video0
デモで実施した結果が得られました。
システムをつくる
物体検出のベースになっているコードが、元々用意されているdetect.pyとなります。
本コードに対し、検出の結果によって、ライトの制御を行います。
まず、ライト制御部分について記載します。
ライト制御
MagicHueをIFTTT経由で点灯/消灯を行います。
事前準備(IFTTT)
Appletの登録
IFTTTの設定手順について説明します。
- https://ifttt.com/home へアクセスしてアカウントを作成 or ログイン
- Createにて、以下の2つを作成
- 忘れている状態 - 赤点灯
- This(Trigger)
- "Webhooks" - "Receive a web request"
- "Event Name" : wasuremono_red
- "Webhooks" - "Receive a web request"
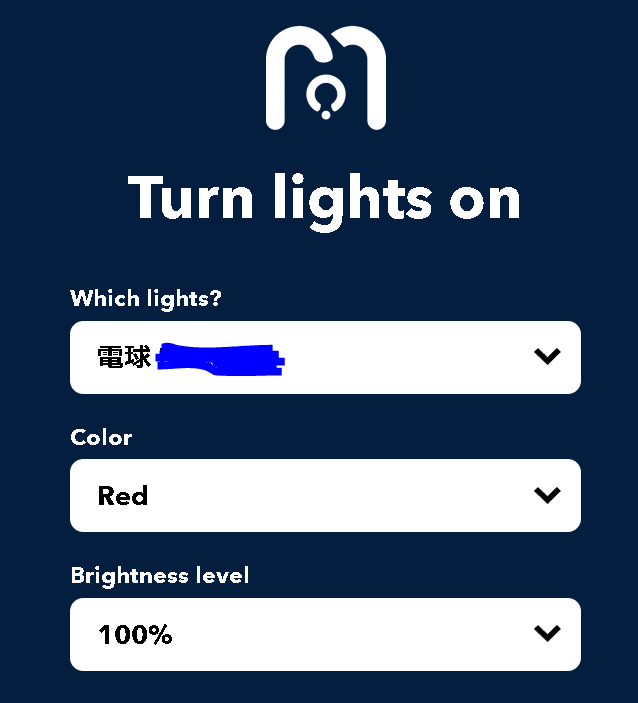
- That(Action)
- Magic Hue - Turn lights on
- Which lights? : 使用するMagicHue
- Color : Red
- Brightness level : 100%
- Magic Hue - Turn lights on
- This(Trigger)
- 忘れていない状態 - 消灯
- This(Trigger)
- "Webhooks" - "Receive a web request"
- "Event Name" : wasuremono_off
- "Webhooks" - "Receive a web request"
- That(Action)
- Magic Hue - Turn lights off
- Which lights? : 使用するMagicHue
- Magic Hue - Turn lights off

- This(Trigger)
- 忘れている状態 - 赤点灯
tokenの確認
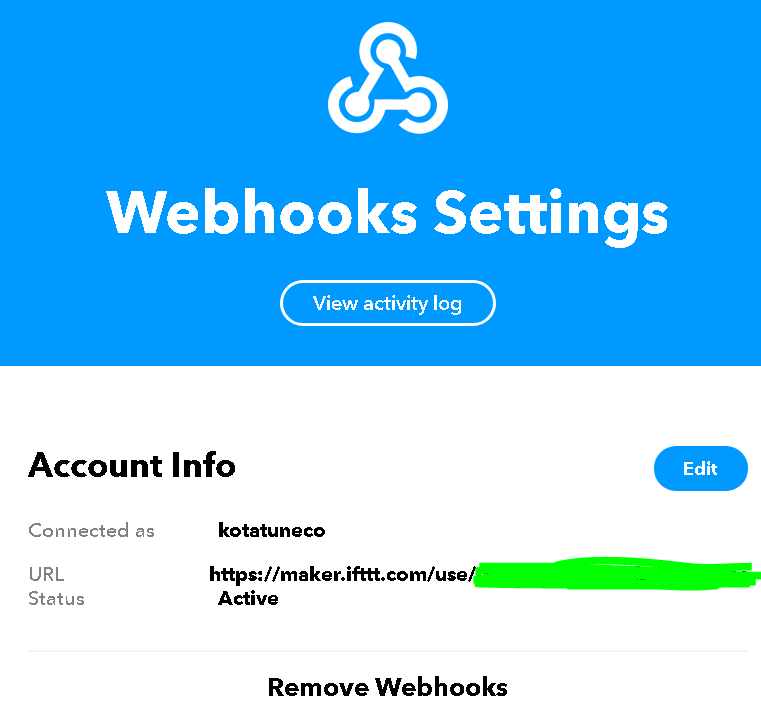
webhooksをキックするためにtokenを確認します。
- Webhooks Settingsのページより確認する
- 下記画像のマスクされている箇所に記載されている
検出部分と通知部分を組み合わせる
以下の動作となります。
- 小物がすべてそろっている場合(忘れている状態)
- 20回連続でそろっていると判定されるとIFTTT - wasuremono_redを送信
- ライトが赤く表示
- 小物がいずれかない場合(忘れていない状態)
- 20回連続でそろっていると判定されるとIFTTT - wasuremono_redを送信
- ライトが消灯
以下が動作結果です。
コード
コードは以下となります。
import jetson.inference
import jetson.utils
import argparse
import sys
import requests
from enum import Enum
class Wasuremo(Enum):
ILL = 1
NOT_FIND = 2
FOUND = 3
# classの定義 - labels.txtの定義値
CLS_ID_BACKGROUND = 0
CLS_ID_CAR_KEY = 1
CLS_ID_WALLET = 2
CLS_ID_EARPHONE = 3
# 通信
IFTTT_TOKEN = "ct7qw9aa__5MTbUeHjTmps"
# 判定マッチ回数
# =>状態が複数回続いたらの閾値
INTERVAL = 20
def main():
parser = argparse.ArgumentParser(description="Locate objects in a live camera stream using an object detection DNN.",
formatter_class=argparse.RawTextHelpFormatter, epilog=jetson.inference.detectNet.Usage() +
jetson.utils.videoSource.Usage() + jetson.utils.videoOutput.Usage() + jetson.utils.logUsage())
parser.add_argument("input_URI", type=str, default="", nargs='?', help="URI of the input stream")
parser.add_argument("output_URI", type=str, default="", nargs='?', help="URI of the output stream")
parser.add_argument("--network", type=str, default="ssd-mobilenet-v2", help="pre-trained model to load (see below for options)")
parser.add_argument("--overlay", type=str, default="box,labels,conf", help="detection overlay flags (e.g. --overlay=box,labels,conf)\nvalid combinations are: 'box', 'labels', 'conf', 'none'")
parser.add_argument("--threshold", type=float, default=0.5, help="minimum detection threshold to use")
is_headless = ["--headless"] if sys.argv[0].find('console.py') != -1 else [""]
try:
opt = parser.parse_known_args()[0]
except:
print("")
parser.print_help()
sys.exit(0)
# create video output object
output = jetson.utils.videoOutput(opt.output_URI, argv=sys.argv+is_headless)
# load the object detection network
net = jetson.inference.detectNet(opt.network, sys.argv, opt.threshold)
# create video sources
input = jetson.utils.videoSource(opt.input_URI, argv=sys.argv)
# add
wasuremono = Wasuremo.ILL
find_count = 0
not_find_count = 0
comp_class = {CLS_ID_CAR_KEY, CLS_ID_WALLET, CLS_ID_EARPHONE}
# process frames until the user exits
while True:
# capture the next image
img = input.Capture()
# detect objects in the image (with overlay)
detections = net.Detect(img, overlay=opt.overlay)
# print the detections
print("detected {:d} objects in image".format(len(detections)))
find_class = set()
for detection in detections:
find_class.add(detection.ClassID)
# print(detection)
if find_class == comp_class:
# 小物がみつかった
find_count += 1
not_find_count = 0
print("mitukatta : ", find_count, not_find_count)
else:
# 小物がみつからなかった
find_count = 0
not_find_count += 1
print("mitukaranakatta! : ", find_count, not_find_count)
if find_count > INTERVAL and wasuremono != Wasuremo.FOUND:
print(Wasuremo.FOUND)
wasuremono = Wasuremo.FOUND
post_request("wasuremono_red")
if not_find_count > INTERVAL and wasuremono != Wasuremo.NOT_FIND:
print(Wasuremo.NOT_FIND)
wasuremono = Wasuremo.NOT_FIND
post_request("wasuremono_off")
# render the image
output.Render(img)
# update the title bar
output.SetStatus("{:s} | Network {:.0f} FPS".format(opt.network, net.GetNetworkFPS()))
# print out performance info
net.PrintProfilerTimes()
# exit on input/output EOS
if not input.IsStreaming() or not output.IsStreaming():
break
def post_request(event_id):
payload = {"value1": "",
"value2": "",
"value3": "" }
payload["value1"] = ""
payload["value2"] = ""
payload["value3"] = ""
url = "https://maker.ifttt.com/trigger/" + event_id + "/with/key/" + IFTTT_TOKEN
try:
response = requests.post(url, data=payload)
if 200 == response.status_code and "Congratulations" in response.text:
pass
else:
print("error : ifttt")
response.close()
except requests.exceptions.RequestException as e:
print("[ifttt_th] e", e)
return
if __name__ == "__main__":
main()
実行手順
IFTTTにリクエストを投げるため、requestsモジュールのインストールが必要です。
# pip install requests
# python ./sikou/detectnet.py --model=sikou/ssd-mobilenet.onnx --labels=sikou/labels.txt --input-blob=input_0 --output-cvg=scores --output-bbox=boxes /dev/video0
さいごに
比較的高い精度で、検出ですることができました。
決まった画角 且つ 判定する対象も同じなので、良い結果だと思います。
この仕組みでは、動きっぱなしなので効率が悪いです。
人感センサーなどを使って、必要な時に処理するようにした方がいいかなと考えています。
久しぶりにJetsonを使ってみて楽しかったです。
Discussion