gpt-oss-120b をローカルで快適に使いたい
ollama を使えば gpt-oss-120b のローカル推論環境を簡単に作れるのですが、
curl -fsSL https://ollama.com/install.sh | sh
ollama run gpt-oss:120b
動かしている様子を nvitop で確認すると、GPU メモリだけほぼ使い切っていて、 GPU の演算はほぼ使われていないという状態でした。
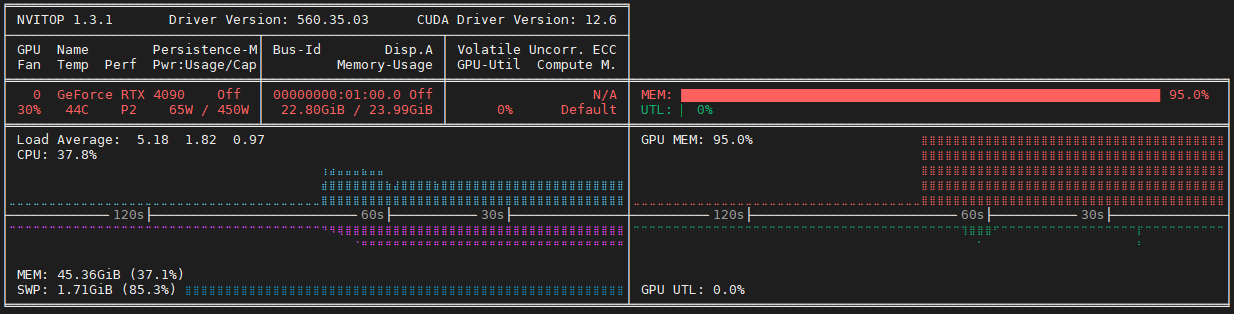
これではせっかく高い GPU がもったいない、ということで高速に推論できる設定を探します。
llama.cpp の環境構築
ollama は細かい設定を自動でしてくれる代わりに、手動で設定するインターフェースが少ないので、今回は ollama のバックエンドとして使われている llama.cpp を直接使ってパラメータの検討をします。
we want to be able to configure this automatically based on available memory rather than making the user configure it
ドキュメントにしたがって llama.cpp をビルドします。
git clone https://github.com/ggml-org/llama.cpp
cd llama.cpp
cmake -B build -DGGML_CUDA=ON
## CMAKE_CUDA_COMPILER-NOTFOUND と出た場合
# export PATH=/usr/local/cuda/bin:$PATH
## Could NOT find CURL と出た場合
# sudo apt install libcurl4-openssl-dev
cmake --build build --config Release -j
下記のコマンドで gpt-oss-120b のサーバーが起動します。( --n-gpu-layers は今回使用している RTX4090 GPU のメモリサイズに合わせてあります)
llama-server -hf ggml-org/gpt-oss-120b-GGUF -c 0 --n-gpu-layers 12 -fa on --jinja --host 0.0.0.0

このコマンドでの推論( decoding )速度は 12.98 tps でした。 ollama で推論した場合と異なり GPU が多少動いていたので、下記のように GPU を完全に無効化してみると 9.41 tps となりました。
CUDA_VISIBLE_DEVICES="" llama-server -hf ggml-org/gpt-oss-120b-GGUF -c 0 --n-gpu-layers 0 -fa on --jinja --host 0.0.0.0
ollama の推論速度は 9.8 tps だったので、何らかの理由で ollama では GPU メモリロードだけされて処理が実行されない状態になっていると推測されます。
オプション比較
さて、今回注目したいオプションは --cpu-moe です。これを指定すると、 MoE モデルの expert だけ CPU で推論させて、アクセス頻度の高い共通部分を GPU で推論します。
llama-server -hf ggml-org/gpt-oss-120b-GGUF -c 0 --cpu-moe -fa on --jinja --host 0.0.0.0
このとき decoding は 17.77 tps と、 ollama 比で約 1.8 倍になりました。 GPU メモリの消費も 8.5 GB まで減っていて、この設定であれば GPU スペックを下げても問題なさそうです。また CPU が Core i5-13400F でこの結果なので、もう少し良い CPU を使えば速度が出るはずです。
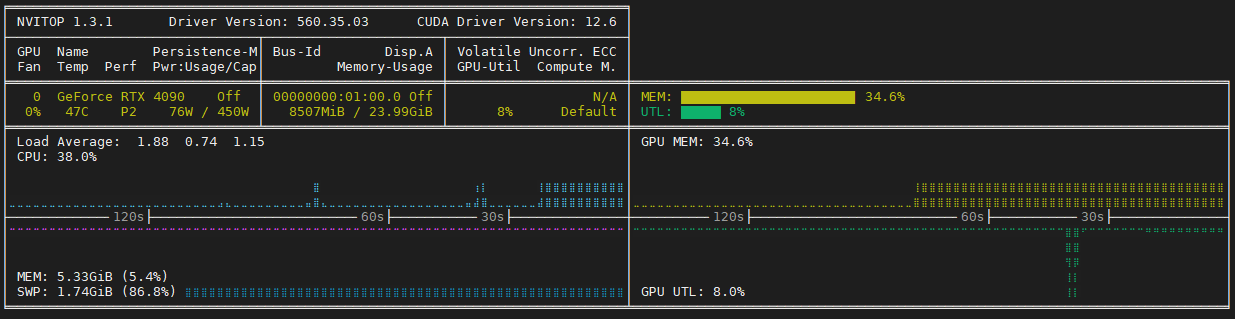
GPU メモリが余っているので、 --n-cpu-moe オプションを使って一部の MoE expert を GPU に移動します。
llama-server -hf ggml-org/gpt-oss-120b-GGUF -c 0 --n-cpu-moe 28 -fa on --jinja --host 0.0.0.0
今回の実験では --n-cpu-moe 28 以上で動作して、このとき 21.96 tps を達成しました。

GPU メモリはこれ以上使えませんが、 GPU 利用率はまだ空いています。これを活用することを目的として、並列にアクセスして計算する -np オプションを追加します。
llama-server -hf ggml-org/gpt-oss-120b-GGUF -c 0 --n-cpu-moe 28 -fa on --jinja --host 0.0.0.0 -np 2
2 つのリクエストを同時に発行して測定したところ、それぞれ 12.21 tps と 13.01 tps となりました。 GPU 利用率は先ほどの測定より下がっているので意図通りではないですが、単独リクエストに比べて合計のスループットが向上することが確認されました。

まとめ
- gpt-oss-120b のローカル推論について、 llama.cpp で適切にオプションを設定すると、 ollama に比べて約 2.2 倍の速度( 9.8 tps → 21.96 tps )で推論できた
- ollama は llama.cpp の GPU 不使用設定とほぼ同じ速度(原因は不明)
-
--n-gpu-layersオプションだけだと 1.3 倍速くらい -
--cpu-moeオプションだけだと 1.8 倍速になるがメモリを使いきらない(5070 12GB とかだとちょうど良いかも:未検証) -
--n-cpu-moeオプションで一部の MoE expert だけオフロードする戦略が最良 - リクエストの並列化で高速になる余地がありそう(未検証)
- いずれにしても API (200 tps 以上) に比べるとかなり遅い
- API の速度測定については https://zenn.dev/kota_iizuka/articles/3fec86fb4a11b4 を参照
Discussion