AI エージェントにとって難しいタスクとは何か? SWE-bench から考える
近年、多数のモデルやAIエージェントが公開されていますが、「ベンチマークは良いけど実際使ってみると微妙」という声や、「このベンチマークで1%向上したというが実際どれくらいの差なのか?」という疑問が発生しがちです。
今回は SWE-bench-verified というベンチマークを題材に、AI はどのようなタスクを解くことができて、また何が苦手かについて、いくつかのデータや具体例を確認しながら考えたいと思います。
SWE-bench-verified とは
Python で書かれた 12 リポジトリで実際に提出された 500 件の issue について、正しく解くことができるかを単体テストで確認するベンチマークです。
2025年10月現在、多くのモデル・エージェントが SWE-bench-verified の結果を提出していて、中身を分析しやすい形になっています。
傾向の調査
まずはリポジトリごとに公開日と性能をプロットします。
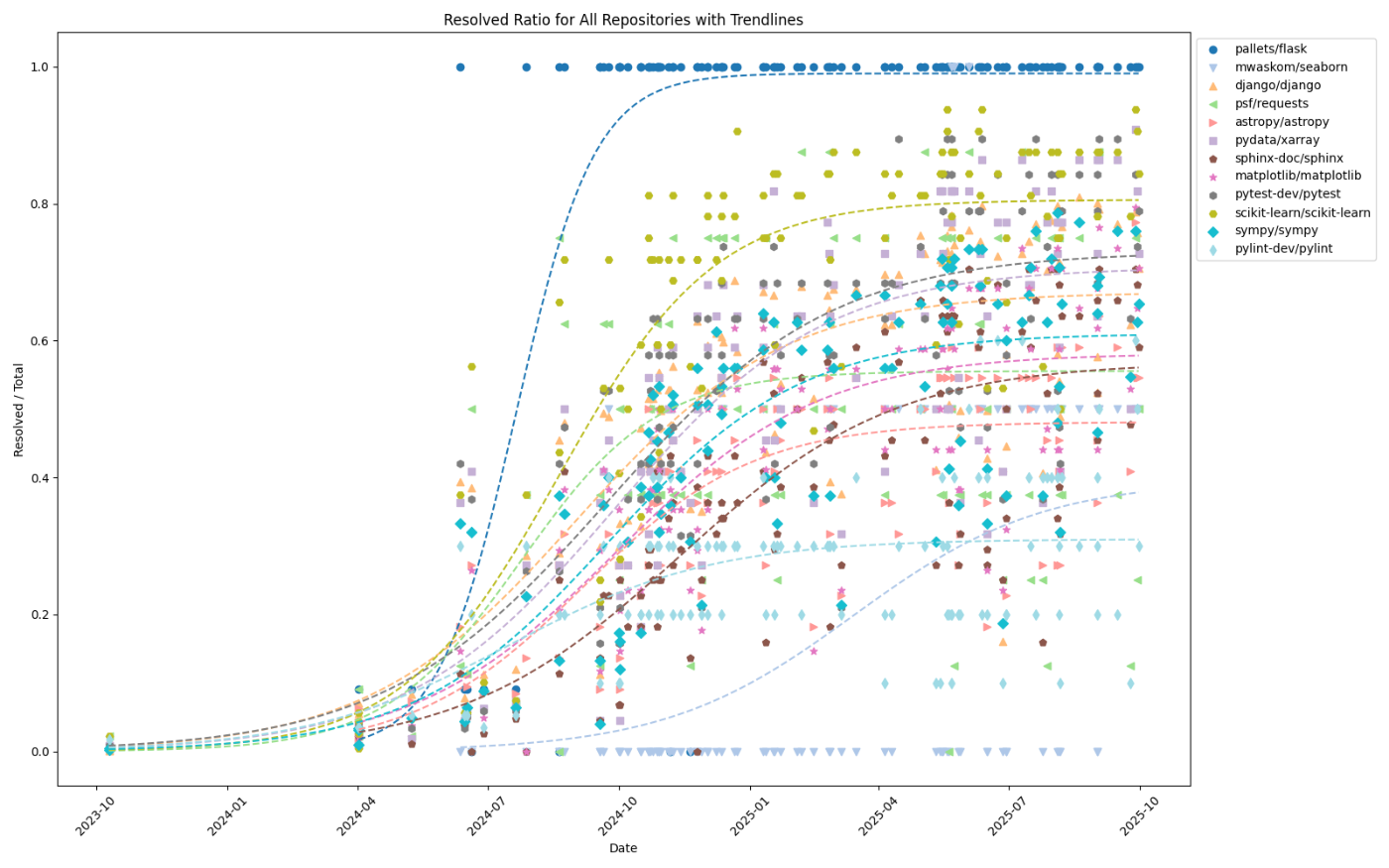
flask のタスクはほぼ 100% に近い性能を達成しているのに対し、 seaborn や pylint など、あまり解けていないリポジトリもあります。また、プロットしたモデルやエージェントの開発企業はバラバラですが、リポジトリごとの得意・不得意には一貫した傾向があるように見えます。
次に、リポジトリ単位より細かく、タスクごとに確認してみましょう。少なくとも1つのエージェントに解かれているタスクについて、正答したエージェント数の分布は次のようになっています。
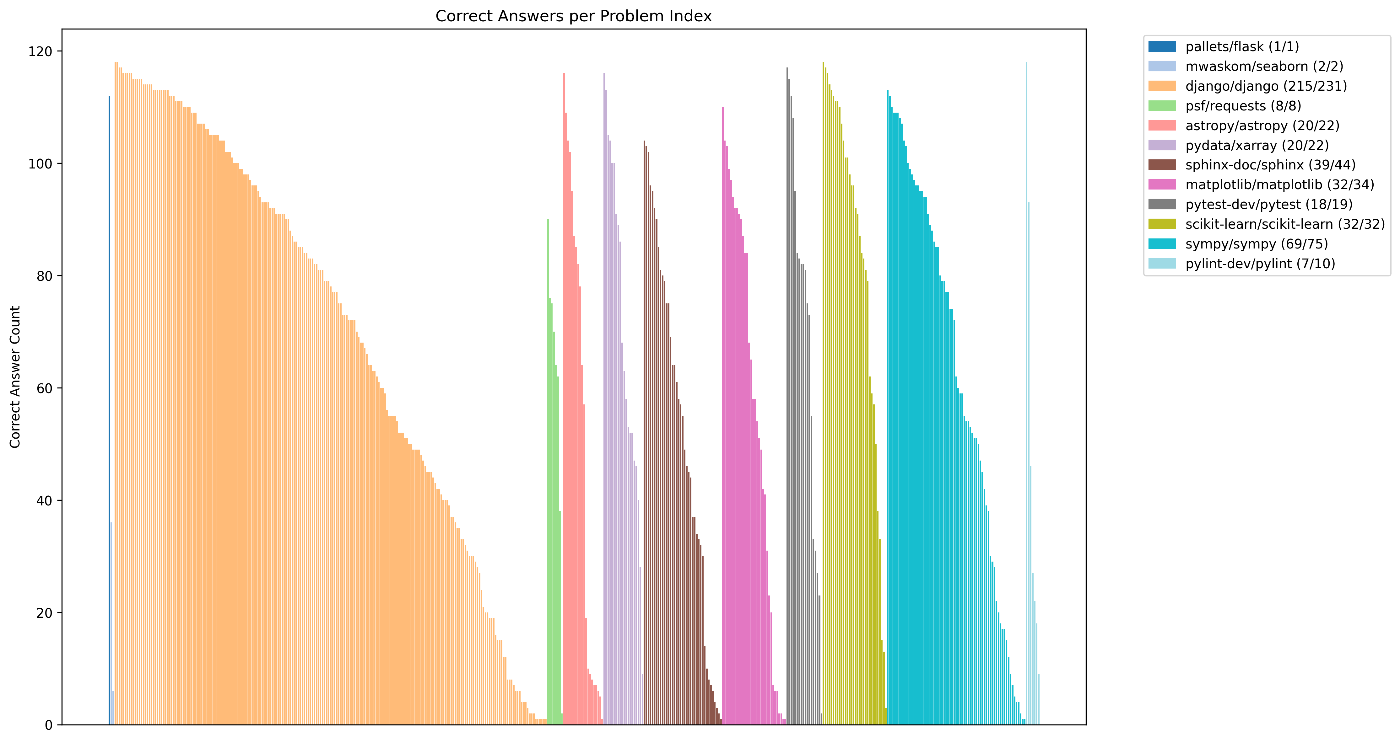
これを見ると、同じリポジトリの中でも解きやすい問題とそうでない問題が混在していることがわかります。リポジトリごとの比較で極端な傾向が出ていたものは、サンプル数の少ないリポジトリであることもわかりました。
各タスクには、問題文 problem_statement に加えて想定難易度 difficulty が設定されています。これらを表示すると次のようになります。
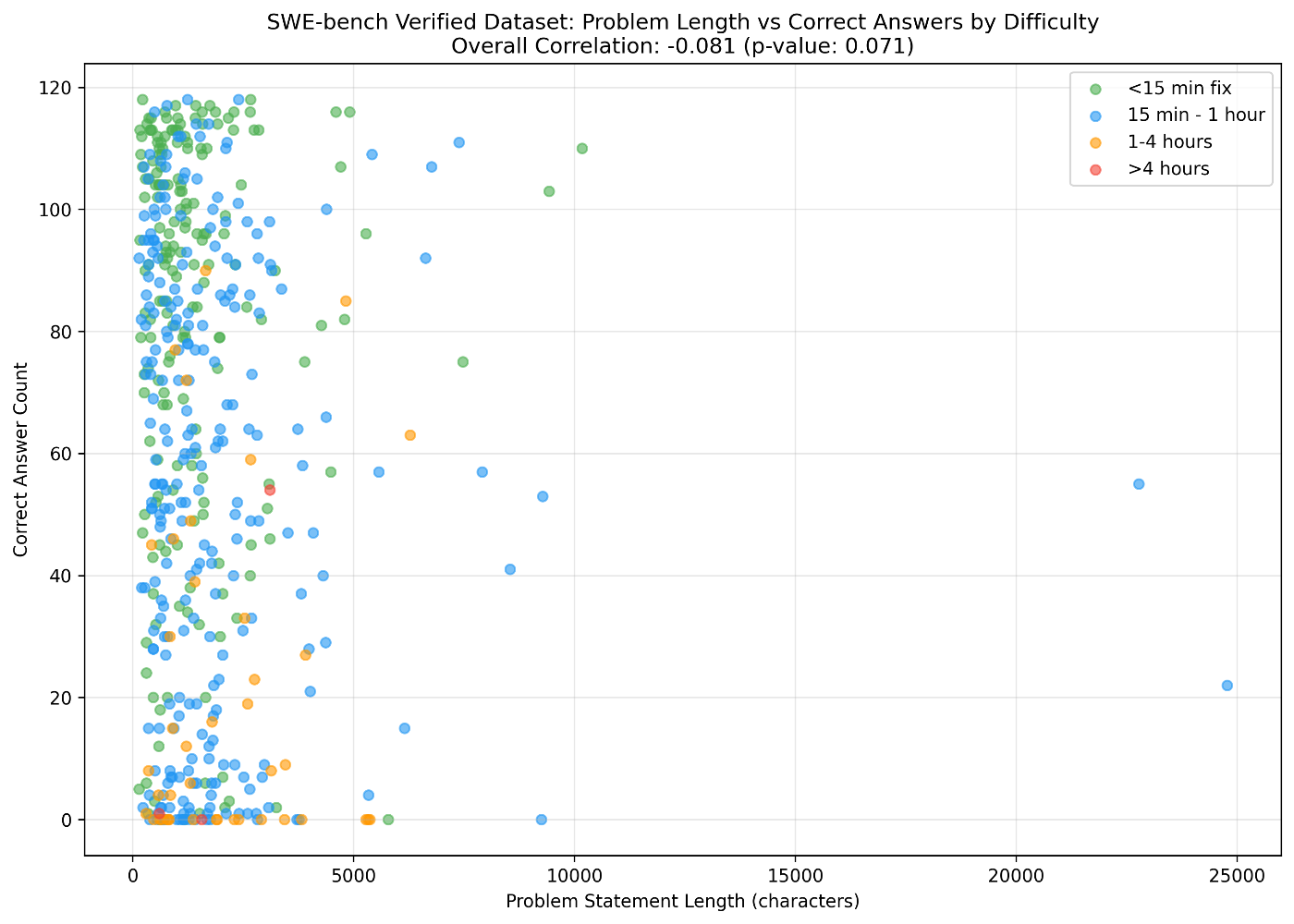
問題文の長さと正答率にはそこまで相関はありませんでした。また全体的には、人間にとって難しいタスクと AI にとって難しいタスクには共通しているものがありそうですが、いくつか例外も見られます。
例外ケースの調査
はっきりした傾向が確認できなかったので、いくつかのタスクについて内容を深掘りします。具体的には、設定された難易度と正答率が対応していないケースについて、それぞれ元の PR などを確認してみます。
人間が解くのは難しいが AI には簡単なケース
この PR は、最高難易度 >4 hours に指定されている中で多くのエージェント(54種類)に解かれている唯一のタスクです。人間が書く場合は、それぞれの確率分布について(おそらく覚えていないので)調べながら書くことになり時間がかかりそうです。一方でコードとしては依存関係が小さい修正の繰り返しであり、有名な確率分布に対する情報も wikipedia 等を学習している AI にとっては解きやすそうに見えます。
これは 1-4 hours 難易度の中で最多の 90 エージェントに解かれたタスクです。 python の import に関するやや細かい知識が必要ですが、 AI は公式ドキュメントをちゃんと学習していると思われます。
次点で 85 エージェントに解かれているのがこのタスクです。「片方はうまくいくけどもう片方はうまくいかない」という問題で、対応する箇所をコンテキストに正しく入れることができればエージェントで対応できそうに見えます。
(ちなみに hints_text には直接的にここを直すべきというものが書かれているのですが、公式ガイドラインによると hints_text は使わずに problem_statement だけで解く必要があるようでした)
人間には簡単だが AI にとっては難しいケース
次に、 <15 min fix 難易度でまだ1回も解かれていない3タスクを確認します。
1つ目は、負の時刻を表す正規表現に関する PR です。個人的な体感ですが、確かに正規表現の修正は(新規追加に比べて)かなり苦手な印象があります。
このタスクは Claude Sonnet 4.5 + mini-SWE-agent でも失敗していて、( -1:-30:00 のような)通常想定されていないルールを通す実装になってしまっていました。自然言語の表現力が正規表現に比べて足りないことに起因しているのかもしれません。
2つ目は matplotlib の cmap name についてのバグで、 issue にはエラーの状況しか書かれていませんでした。想定解も内部の値を修正してしまうというもので、行儀よく書くエージェントだと答えにたどり着けない気がします。
3つ目は sphinx で空タプルの型アノテーションがある場合の対応です。 sphinx 固有のクラスについての修正が必要で、コードの理解を含めると15分ではやや難しそうな気がします。
まとめ
- SWE-bench について
- 結果がかなり整っていて分析が楽(qwen-code で qwen3-coder-480b にプロンプトを投げるだけで十分)
- 公開当時(Claude 2 や GPT-4 の時代)からモデル性能が向上してサチってきている
- 一部の難易度アノテーションは現代の体感には合わないかも?
- エージェントの得意・不得意について
- 検索したら出てくるような情報、(難易度にかかわらず)必要なコンテキストが小さい修正は、AIのほうが得意
- 競プロも AI エージェントに解かれつつあるし「難しそうだから解けない」とはいえなくなってきている
- 逆に、各リポジトリでしか扱わないローカルな記法、公式のベストプラクティスに従わないような書き方には弱い
- どちらかというと「AIが書くように人も書くべき」という場面が多そう
- 検索したら出てくるような情報、(難易度にかかわらず)必要なコンテキストが小さい修正は、AIのほうが得意
Discussion