【論文解説】Segment Any Anomaly∶プロンプトを使った学習要らずの異常検知
はじめに
本記事ではタイトル通り、プロンプトを使った異常検知モデルである"Segment Any Anomaly"について簡単な解説を行っていきます。コードの詳細な解説等は行わないのでご了承ください。
以下、モデルのアーキテクチャ図が何度か登場しますが"Segment Any Anomaly"から引用しています。
また、論文について誤った解釈をしている場合や内容が不明瞭な場合はコメントで修正して頂けると幸いです。
0. 論文情報
"Segment Any Anomaly without Training via Hybrid Prompt Regularization"
arxiv URL:https://arxiv.org/abs/2305.10724
Github URL:https://github.com/caoyunkang/Segment-Any-Anomaly
1. TL;DR
- VAND 2023 ChallengeというZero-shot, Few-shot異常検知の精度を競うコンペで準優勝
- 異常画像だけでなく正常画像さえも必要としない、学習必要なしのZero-shotモデル
-
プロンプトを使って異常の種類を指定
2. 概説
Segment Any Anomalyには、
- 必要最低限の実装であるSAA (バニラモデル)
- SAAの問題点を解決したバージョンであるSAA+
があるため、それぞれ解説していきます。
2.1. SAA(バニラモデル)

SAAアーキテクチャ
SAAの構造は上の画像の通り、2つのモデルを数珠繋ぎに並べたものになっています。
2つのモデルは大規模データセットで学習済みのもので、「基盤モデル:Foundation Model」とも呼ばれることもあるようです。
基盤モデル:Foundation Modelとは
基盤モデルとは「教師なし学習」で大量の生データを使ってトレーニングされたニューラルネットワークのこと。適応させることで幅広いタスクに利用可能。
例としては、Transformerモデル、大規模言語モデル(LLM)などがこれにあたります。
基盤モデルイメージ図
※文章・画像はNVIDIAのブログを引用しています。
- Anomaly Region Generator:
プロンプトで指定された異常を「大雑把な領域」として検出するためのモデル。
SAAではGrounding DINOという物体検出モデルをこれに利用しています。Grounding DINOは入力に「画像」と「検出したい物体のプロンプト」を受け取り、出力として画像内の検出された物体位置をBounding Box形式で返し、物体は複数個検出可能です。
- Anomaly Region Refiner
Anomaly Region Generatorの出力である「大雑把な領域」をより細かく「個々の異常部位に適した形状」にセグメンテーションするためのモデル。
SAAではSegment Anything Model:SAMというセグメンテーションモデルをこれに利用しています。SAMは入力に様々な種類のプロンプトを受け付けることができる(text, points, bounding box)ため、今回はAnomaly Region Refinerの出力のBounding Boxを入力とすることで、Bounding Box内のセグメンテーションを自動で行い、異常部位に適した形状にセグメンテーションさせることを可能としているようです。
SAAではアーキテクチャ図にもある通り、Anomaly Region Generatorに入力として与えるプロンプトには"anomaly", "defects"などの抽象度が高い単語を与え、異常を検出していきます。
しかしながら、何の工夫もしていないSAAでは以下のような問題が生じてしまいます。
- 事前学習の大規模データセットと検証に用いるデータセットとのDomain Gap
- 形容詞のみのプロンプト("anomaly"等)は事前学習のデータセットには殆どない
- "anomaly", "defects"はオブジェクトによって大きさや形状が大きく異なる
これらの問題に対処したのが発展ver.であるSAA+です。
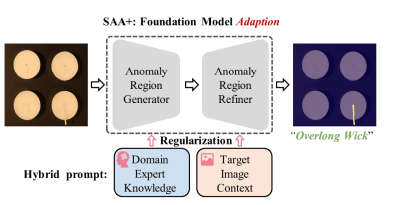
2.2. SAA+
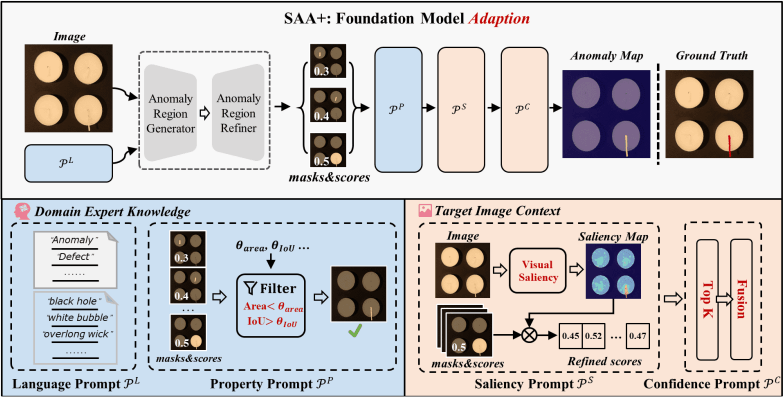
SAA+アーキテクチャ
SAA+はSAAで生じた問題に対処したモデルとなっています。その対処方法をまとめると…
- 任意のピクセルに対しての近傍のピクセルとの違いを数値化、それを使って異常値を補正
- 事前学習のデータセット内にある単語のみで詳細かつ名詞的に異常を表現したプロンプトを作成
- 対象異常オブジェクトに占める異常部位の割合やIoU等を用いて閾値処理を導入
これらを踏まえた上でSAA+の解説をしていきます。
まず、上に示した簡素化されたSAA+のアーキテクチャ図を見ると、SAAをDomain Expert KnowledgeとTarget Image ContextからなるHybrid promptを使って正則化を行っているモデルだということが分かります。続いてSAA+の詳細なアーキテクチャを見ると、
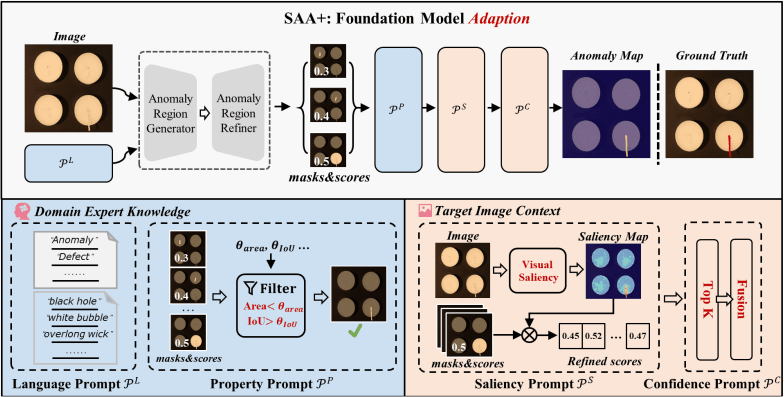
Domain Expert Knowledge, Target Image Contextがどのようなものなのかを伺うことができます。
余談
詳細なアーキテクチャ図を見るとProperty Prompt
ソースは以下(6/28現在)
173行目bbox_suppressionによりProperty Prompt
2.2.1. Domain Expert Knowledge
Domain Expert KnowledgeはLanguage Prompt
- Language Prompt
\mathscr{P}^L
Anomaly Region Generatorに入力するプロンプト。
"anomaly", "defects"などの汎用的な表現はClass-agnostic prompts\mathscr{T}_a \mathscr{T}_s
- Property Prompt
\mathscr{P}^P
閾値処理を行うためのフィルタを定義する。
Anomaly Region Generatorからの出力の内、明らかに異常部位から外れている候補を除外するためのフィルタを定義。異常部位との重なり具合\theta_{IoU} \theta_{area}
2.2.2. Target Image Context
Target Image ContextはSaliency Prompt
- Saliency Prompt
\mathscr{P}^S
SAAで問題として挙げられていたDomain Gapに対処するためのモノ。
検知対象の画像から導出したSaliency MapをAnomaly Region Refinerからの出力に掛け合わせることでDomain Gapを補正することができます。
Saliency Mapとは
<背景>
人がオブジェクトの異常を感知する際には文脈的な異常を除き、周囲との違いに目を向けることが多いです。
周囲との違いを近傍との類似度と解釈しそれを利用することで、検知対象の画像の異常部位の情報を多く持った新たな特徴量を作成!
<導出過程>
- ImageNetで学習済みの分類モデル(WideResNet50等)からパッチごとの特徴量を抽出
参考:公式リポジトリのSAA/model.py, 103, 104, 107, 113, 114行目 - 抽出した特徴量を指定の大きさに補間してconcat
- 2で求めた特徴量マップを平坦化し、特徴量ベクトルとする
- 「プログラム上では」
\frac{1}{2} \times (1-vector.T@vector)
で類似度を算出(vectorは特徴量ベクトル、@は行列積) - 4で算出された特徴量ベクトルを特徴量マップへ戻す
- 5で求めた特徴量マップを元の画像サイズへ補間
公式リポジトリの参考先:
- Confidence Prompt
\mathscr{P}^C
Saliency Prompt\mathscr{P}^S
SAA+工夫点まとめ
- 事前学習のデータセットに使われていた単語で異常を詳細に表現し、プロンプトとして利用 (
\mathscr{P}^L - 異常部位の面積による閾値処理を施すことで明らかに外れた候補を除去 (
\mathscr{P}^P - Saliency Mapを使って検知対象の画像の情報を補間してやることでDomain Gapを解消 (
\mathscr{P}^S - 異常部位の最大個数を設定することで無駄な検知をしない (
\mathscr{P}^C
3. 実験結果
論文ではVisA, MVTec-AD, KSDD2, MTC等の異常検知用データセットに対する検知結果が次のように示されています。

SAA, SAA+ 検知結果
また、公式リポジトリでデフォルトの設定のままMVTecADに対して検知した結果は次の通りです。
| image ROC | pixel ROC | image F1 | pixel F1 | |
|---|---|---|---|---|
| carpet | 94.78 | 70.42 | 94.19 | 56.64 |
| grid | 80.45 | 63.96 | 84.44 | 18.08 |
| leather | 98.13 | 84.91 | 97.85 | 72.67 |
| tile | 96.32 | 81.7 | 94.41 | 64.95 |
| wood | 98.85 | 81.83 | 98.31 | 67.16 |
| bottle | 79.21 | 68.97 | 88.72 | 39.26 |
| cable | - | - | - | - |
| capsule | 51.62 | 61.87 | 90.46 | 17.67 |
| hazelnut | 84.18 | 85.47 | 86.11 | 44.65 |
| metal nut | 29.18 | 59.89 | 89.42 | 36.2 |
| pill | - | - | - | - |
| screw | 40.85 | 67.6 | 85.92 | 20.7 |
| toothbrush | 27.22 | 64.47 | 83.33 | 8.4 |
| transistor | 31.04 | 64.83 | 57.14 | 19.57 |
| zipper | 37.05 | 78.83 | 88.15 | 21.48 |
モノによってはかなり良い結果ではありますが、一部に関してはかなり検知が低いように見えます。
ここでimage ROCが低い部類に入るであろう、zipperのセグメンテーション画像を見てみると…
本来は

のように検知して欲しいところ、

このように検知してほしい「ほつれ」ではなくジッパー部分を異常として検知してしまっています。(因みにzipperに関してはどんな以上画像に対してもジッパー部分のみセグメンテーションした画像が出力されます)
上の実行結果はデフォルトの設定だったので、対象オブジェクトに対する異常部位の閾値

検知してほしい「ほつれ」をうまく検知してくれています。(余計な部分もセグメンテーションしてしまってはいますが…)
4. まとめ・所感
今回はプロンプトを使った異常検知であり、学習不要なモデルである"Segment Any Anomaly"について紹介しました。
ハイパーパラメータの調整なしでは一部で誤検知を起こしてしまうものの、調整さえすればある程度改善されます。
Full-shotのPatchcoreと比べてしまうと多少見劣りしてしまう精度ではありますが、個人的にはWinClip等と合わせてZero-shot+プロンプト異常検知の黎明期だなと感じるモデルでした。
4. おわりに
かなり拙い文章であったとは思いますが、ここまで読んでくださりありがとうございます。
はじめにも書いたとは思いますが、論文の解釈違い等がありましたらコメントにて修正してくださると幸いです。
気が向けば、VAND 2023 Challenge 優勝モデルのAPRIL-GANやGrounding DINOの記事も書きたいと思います。
Discussion