Few Shot でLLM を最適化する

こんにちは👋
大規模言語モデルへの基本的で強力なテクニックのひとつであるFew-Shot 推論について紹介していこうと思います!
Few-Shot 推論とは
Few-Shot 推論とはいくつかの例をコンテキスト内に追加することで、大規模言語モデル(LLM)が生成する返答を誘導し特定のタスクに最適化することができる、プロンプトエンジニアリングのテクニックのひとつです。
"Few-Shot"とカッコいい横文字で呼ばれていますが、適切な和訳はFew(数回の)Shot(試み)になります。
最初の画像ではFew-Shot を使うことでZero-Shot と変わり、「色と食べ物の種類」「最後にわん🐶」という特定のタスクに最適化されていることが分かります。
『Language Models are Few-Shot Learners』[1]という論文によるとモデルが大規模であればあるほど、活用することが効果的であることが分かります。ちなみに、この論文ではGPT-3のコンテキストウィンドウ(LLM に入力するプロンプト)に合わせて10個から100個のShotを与えることがFew-Shot 推論の定義とされています。
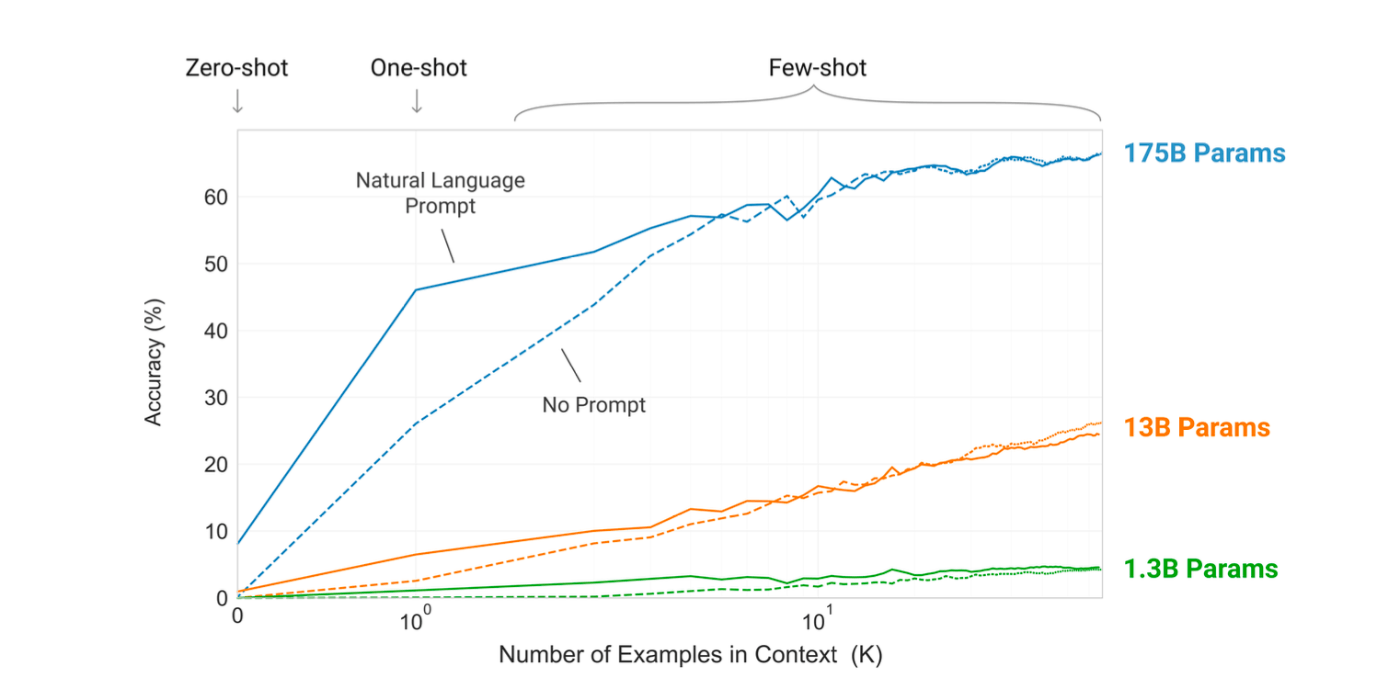
from "Language Models are Few-Shot Learners"
ファインチューニングとの違い
AI モデルを最適化すると言うとファインチューニングを思い浮かべる方もいるのではないでしょうか。実はファインチューニングの方が多くのベンチマークテストで高い性能を発揮します。
しかし、多くの条件とトレードオフする必要があります。
具体的には、
- ファインチューニングを行うには数千から数十万のラベル付き学習データが必要になる。
- 多くの費用が必要になる。フルマネージドなOpenAI API のようなサービスを使う場合は通常のリクエストよりも高額に設定されている場合が多いです。また、カスタムAI モデルを使う場合でも、ファインチューニングはタスクに合わせてニューラルネットの重みを再計算することなので多くのGPU リソースが必要になります。
- 分布外汎化や教師データのスプリアスな特徴を利用してしまう可能性がFew-Shot 推論よりも高くになります。
OpenAI も最適化を行いたい場合は、Few-Shot 推論を検討してからファインチューニングを検討することを推奨しています。

from "https://platform.openai.com/docs/guides/optimizing-llm-accuracy/llm-optimization-context"
まとめ
Few-Shot 推論を使って最適化する方法と、利活用する際の進め方について学ぶことができました。
この記事でLLM の最適化の手助けになれば嬉しく思います。
ご覧いただきありがとうございました!
Discussion