日本語の感情分類器を作ってみた
基盤モデルLINE DistilBERTをファインチューニングし、日本語のテキストの感情分類器を構築しました。技術的詳細も簡単に紹介しながら構築記録を共有します。この記事のコードはGitHub でも公開しています。[1]
Hugging Face Space に完成した感情分類器をデプロイしました。
ぜひ、ここからお試しください🤗
基盤モデル
BERT
BERT とは2018年にGoogle が発表したTransfomer アーキテクチャに基づいた言語表現モデルです。[2]それまでのモデルと異なる特徴は、2つの事前学習ステップにあります。
-
双方向のMasked LM
穴が空いているワードの前後の前か後ろの単方向でなく双方向の情報を使い、穴埋め問題を解かせることで、文脈の中においてのワードの理解をより正確にします。 -
Next Sentence Prediction
次にくる文章として正しいかの問題を解かせることで、文脈の中においての文の理解をより正確にします。
これらの特徴的なステップはTransfomer アーキテクチャにおけるエンコーダ機構のみを利用します。そのためBERT はエンコーダのみモデルと呼ばれ、文脈理解が得意なモデルとされています。対してGPT はデコーダのみモデルと呼ばれ、構造上はBERT の方がテキストの分析は得意とされています。
DistilBERT
DistilBERT とは2019年にHugging Face が発表した蒸留モデルで、「知識の蒸留」というテクニックを使いBERT よりも40%パラメータを減らしつつ、97%のパフォーマンスを保持できるモデルです。[3]
LINE DistilBERT
LINE DistilBERT とは2023年にLINE が発表した蒸留モデルです。[4]2024年9月現在、日本語DistilBERT の中でトップのスコアを取得しています。
今回はこの基盤モデルを使用します。
データセット
感情分類タスクに最適化するため基盤モデルをファインチューニングにする必要があります。
WRIME Ver2
日本の研究チームが2022年に構築したデータセットで、日本語の文について詳細な感情のラベルが入っており2024年9月現在最大です。
合計35000件の60人の過去のSNS 投稿に対して、心理学者ロバート・プルチックが提唱した基本の8感情(喜び、悲しみ、期待、驚き、怒り、恐れ、嫌悪、信頼)とその強度を4段階で投稿者自身のラベル付けがされています。さらに、3人の客観的アノテーターによる同様にラベル付けがされています。[5]
データセットの前処理
ここまでで今回利用する基盤モデル、データセットの詳細について紹介しました。
ここからは実際に訓練に使用したJupyter Notebook を基にコードを紹介していきます。[6]
依存関係のインポート
import pandas as pd
from transformers import AutoTokenizer, AutoModelForSequenceClassification, Trainer, TrainingArguments
from datasets import Dataset
import numpy as np
定数宣言
EMOTIONS = [
"Joy",
"Sadness",
"Anticipation",
"Surprise",
"Anger",
"Fear",
"Disgust",
"Trust",
]
PRETRAINED_MODEL_NAME = "line-corporation/line-distilbert-base-japanese"
データセットのロード
Pandas データフレームにロードします
df = pd.read_table("./dataset/wrime-ver2.tsv")
訓練とテストのデータに分割する
カラム"Train/Dev/Test"というカラムを利用します
train_df = df[df["Train/Dev/Test"] == "train"].copy()
test_df = df[df["Train/Dev/Test"] == "test"].copy()
感情カラムを統合する
投稿者の評価、3の客観評価の平均からなる合計16カラムを統合します、
主観と客観を用意されている1 : 3 の割合で統合したいので、客観評価に対して3を掛けます
def merge_emotions(splited_df):
merged_df = splited_df.copy()
emotions = EMOTIONS
READER_NUM = 3
for e in emotions:
merged_df[f"Merged_{e}"] = (
merged_df[f"Writer_{e}"] + merged_df[f"Avg. Readers_{e}"] * READER_NUM
)
merged_df["Merged_emotion_list"] = merged_df[
[f"Merged_{e}" for e in emotions]
].values.tolist()
return merged_df
train_merged_df = merge_emotions(train_df)
test_merged_df = merge_emotions(test_df)
トークナイザーのロードと保存
tokenizer = AutoTokenizer.from_pretrained(
PRETRAINED_MODEL_NAME,
clean_up_tokenization_spaces=False,
)
tokenizer.save_pretrained("./output/tokenizer")
トークナイズと正規化
Dataset にロードし、効率的にファインチューニングできるようにトークナイズとL1正規化を行います
def format_dataset(batch, _tokenizer):
formatted_batch = _tokenizer(
batch["Sentence"],
padding="max_length",
truncation=True,
max_length=512,
)
formatted_batch["labels"] = [x / (np.sum(x) + 1e-8) for x in batch["Merged_emotion_list"]]
return formatted_batch
target_columns = ["Sentence", "Merged_emotion_list"]
train_dataset = Dataset.from_pandas(train_merged_df[target_columns])
test_dataset = Dataset.from_pandas(test_merged_df[target_columns])
preprocessed_data = {
"train": train_dataset.map(
lambda batch: format_dataset(batch, tokenizer),
batched=True,
cache_file_name=None,
),
"test": test_dataset.map(
lambda batch: format_dataset(batch, tokenizer),
batched=True,
cache_file_name=None,
),
}
ファインチューニング
前処理済みのデータセットを使って基盤モデルを訓練していきます
基盤モデルのロード
model = AutoModelForSequenceClassification.from_pretrained(
PRETRAINED_MODEL_NAME,
num_labels=len(EMOTIONS),
)
訓練の設定
training_args = TrainingArguments(
output_dir="./output/result",
eval_strategy="epoch",
save_strategy="epoch",
per_device_train_batch_size=16,
per_device_eval_batch_size=16,
num_train_epochs=3,
weight_decay=0.01,
logging_dir="./logs",
logging_steps=10,
load_best_model_at_end=True,
)
trainer = Trainer(
model=model,
args=training_args,
train_dataset=preprocessed_data["train"],
eval_dataset=preprocessed_data["test"],
)
訓練開始とモデルの保存
trainer.train()
model.save_pretrained("./output/model")
訓練
ファインチューニングは多くのGPU リソースが必要です。そこでGoogle Colab Pro 上でNvidia A100 を使用して訓練し、約18分で完了しました。
評価
機械的な評価
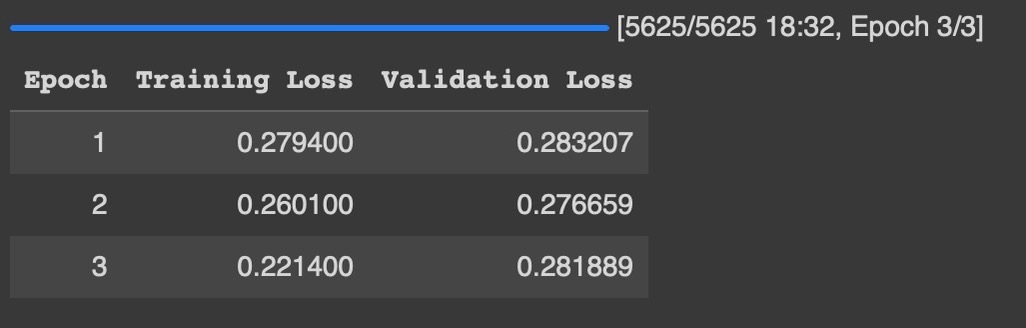
訓練損失と検証損失がどちらも低くく収まっており、過学習が進む前に収束できたのかなと思います。
主観的な評価
私が適当な文章を入れて簡易的に評価をしました。予測は高い確率が出そうなトップ3を書き出しました。
「ハンバーガーは美味しいけど、ついつい食べすぎてしまう」
- 予測
Fear → Joy → Anger - 結果
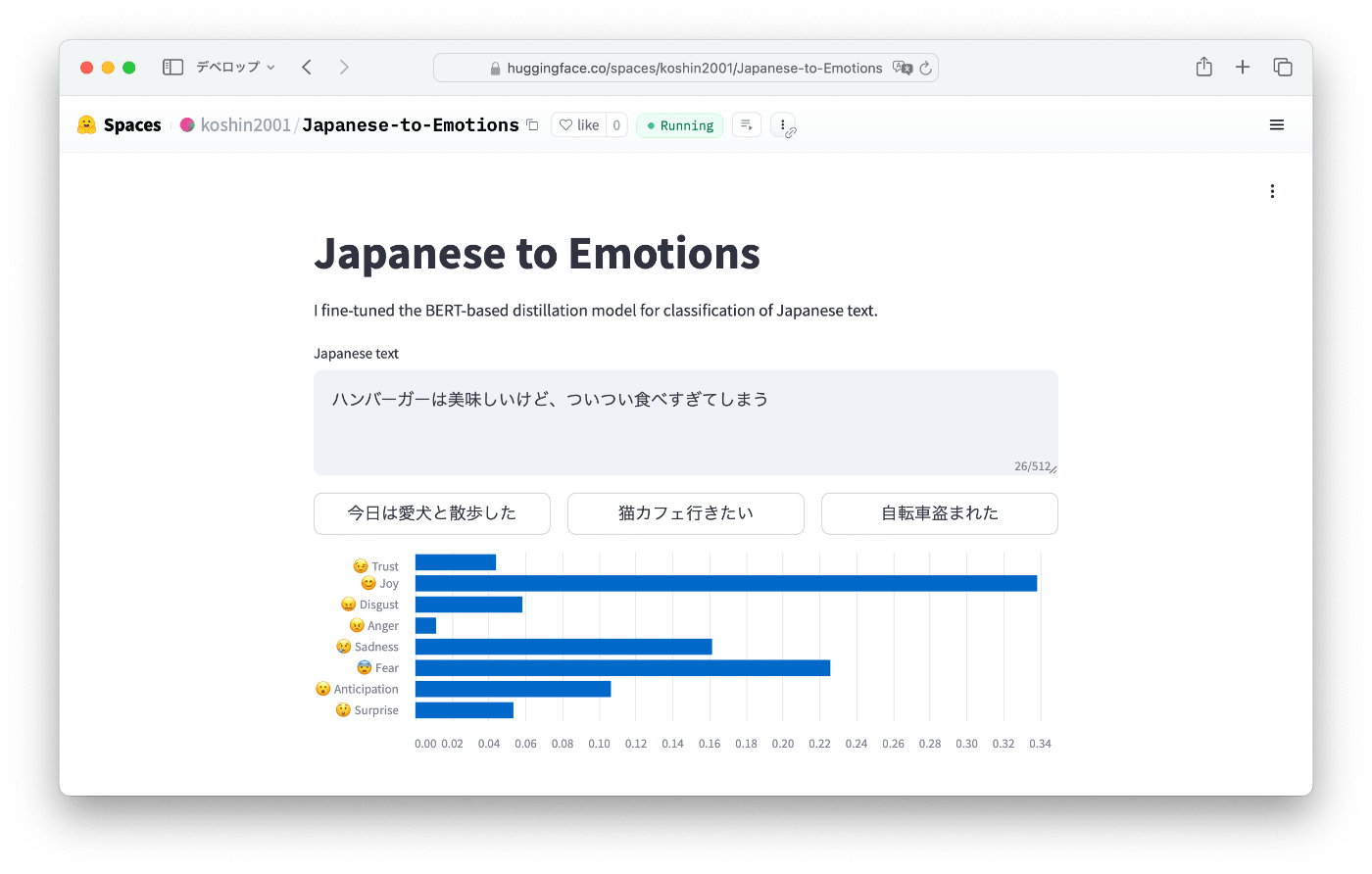
- 評価
主題は「食べすぎてしまう」ことから自分への恐怖だと予測しましたが、「美味しい」に引っ張られている?
「ライオンに食べられそうになった」
- 予測
Fear → Sadness → Anger - 結果
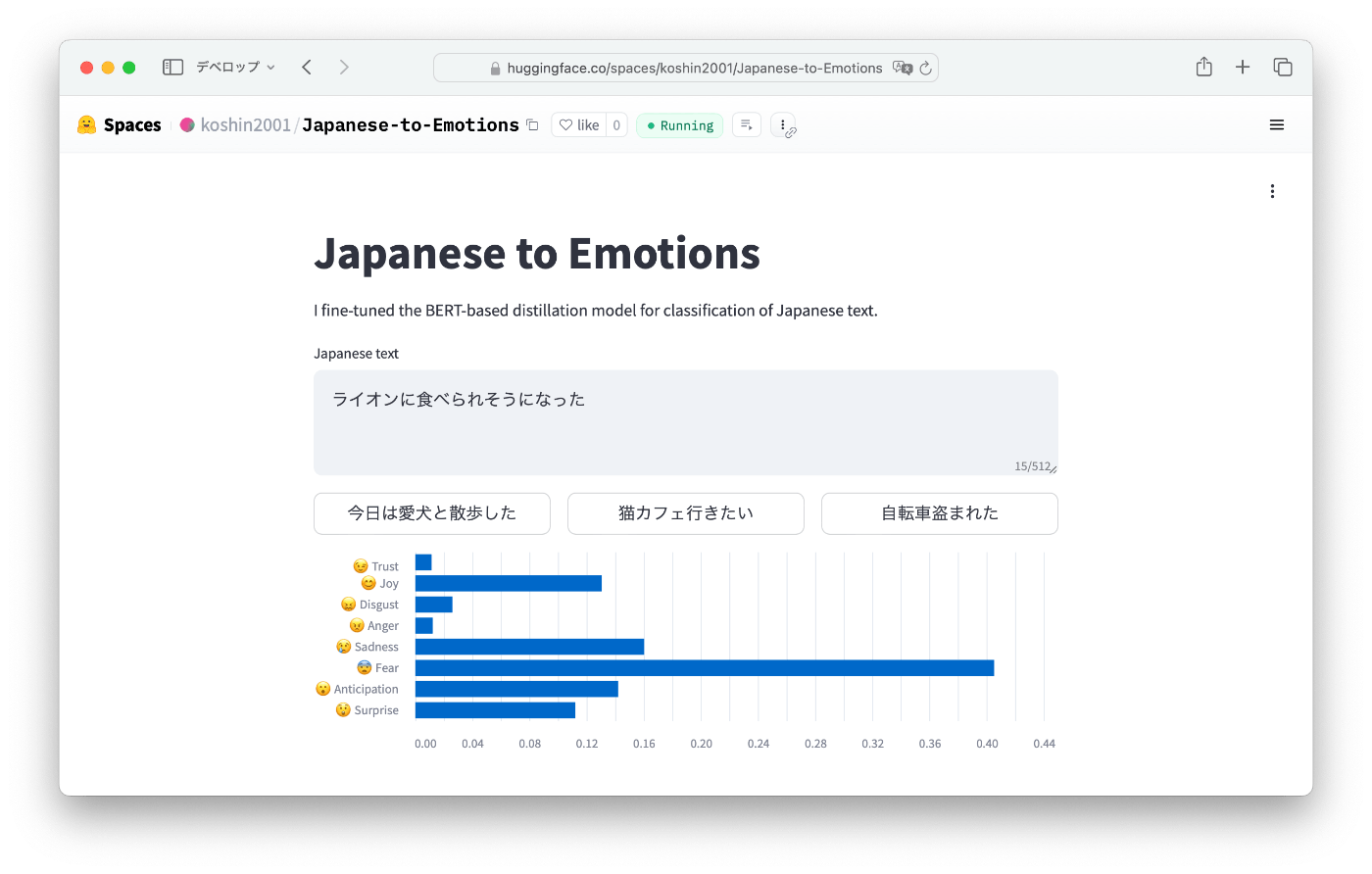
- 評価
Fear とSadness を予測できましたが、Anticipation が3番目に来るのはライオンに食べられるのを期待していることになってる。
構築後の感想としては完璧ではないものの、おおよその感情分類はできているのかなと思いました。
冒頭のリンクのHugging Face Space でご自身で試せるので、ぜひお試してください。
まとめ
BERT モデルの技術的詳細、それをファインチューニングする方法について学ぶことができました。
私自身、AI エンジニアリングへの挑戦となりました。この記事で多くの人の手助けになれば嬉しく思います。
また、構築する際に参考にさせて頂いた先行記事[7]、研究論文、基盤モデル、データセットの公開についてこの場で感謝申し上げます。
ご覧いただきありがとうございました👋
-
https://research.google/pubs/bert-pre-training-of-deep-bidirectional-transformers-for-language-understanding/ ↩︎
-
https://engineering.linecorp.com/ja/blog/line-distilbert-high-performance-fast-lightweight-japanese-language-model ↩︎
-
https://github.com/koshin01/emotion_classification/tree/main/train ↩︎
Discussion