Cloud Workflowsで自動リトライ(Exponential Backoff) を実装する(1)



GCPのCloud Workflowsを用いてCloud Functionsをコールする際にFunctions側のスケーリングが間に合わず、429エラーや500エラーが発生することがあります。 English version
エラーの対処方法としてリトライが有効と公式Docで案内されているので、Workflows内で自動リトライ(Exponential Backoff)を実装してみました。
※ なお、Cloud Runもスケーリングに関するエラーコードも同様に 429と500 と同一のため、本記事の内容で対応できると思われますが、Cloud Runについては未検証です。
(検証用)Cloud Functions
上記スケーリング問題を発生しやすくするために以下のようなFunctionを用意しました。
- スケール設定を少なめに設定(min:0,max:1)
- 内部で3秒スリープ
foobar/main.py
import time
import flask
def main(request):
time.sleep(3)
return flask.jsonify({'result': 'ok'})
デプロイコマンド
# functionのデプロイ
$ gcloud functions deploy foobar \
--entry-point main \
--runtime python39 \
--trigger-http \
--region asia-northeast1 \
--timeout 120 \
--memory 128MB \
--min-instances 0 \
--max-instances 1 \
--source ./foobar
# Workflowsに紐づけるサービスアカウントにfunctionの実行権限を付与
$ gcloud functions add-iam-policy-binding foobar \
--region=asia-northeast1 \
--member=serviceAccount:${YOUR-SERVICE-ACCOUNT} \
--role=roles/cloudfunctions.invoker
V1(対策なし) Workflows
比較のため、該当のAPIをコールするだけのシンプルなWorkflowsでスケーリングエラーの問題を再現してみます。
main:
params: [input]
steps:
- callFunc:
call: http.get
args:
url: https://asia-northeast1-xxx.cloudfunctions.net/foobar
auth:
type: OIDC
result: api_result
- returnOutput:
return: ${api_result.body}
デプロイコマンド (シンガポール リージョンを利用)
$ gcloud workflows deploy v1 \
--source=v1.yml \
--location=asia-southeast1 \
--service-account=${YOUR-SERVICE-ACCOUNT}
以下のワークフロー実行コマンドを20回ほど連打。
gcloud workflows run --project=${YOUR-PROJECT} --location=asia-southeast1 v1 --data='{}' &
期待通り429エラーが再現。ワークフローの成功確率は約20分の6程度でした。

ワークフローの実行詳細画面で確認できたエラー情報:
HTTP server responded with error code 429
in step "callFunc", routine "main", line: 5
{
"body": "Rate exceeded.",
"code": 429,
"headers": {
"Alt-Svc": "h3=\":443\"; ma=2592000,h3-29=\":443\"; ma=2592000,h3-Q050=\":443\"; ma=2592000,h3-Q046=\":443\"; ma=2592000,h3-Q043=\":443\"; ma=2592000,quic=\":443\"; ma=2592000; v=\"46,43\"",
"Content-Length": "14",
"Content-Type": "text/html",
"Date": "Wed, 09 Feb 2022 08:17:19 GMT",
"Server": "Google Frontend",
"X-Cloud-Trace-Context": "2a8e4ba95570e4a6585a0b678d7f3b98"
},
"message": "HTTP server responded with error code 429",
"tags": [
"HttpError"
]
}
Cloud Functions側のログ画面でも429エラーを確認できます。
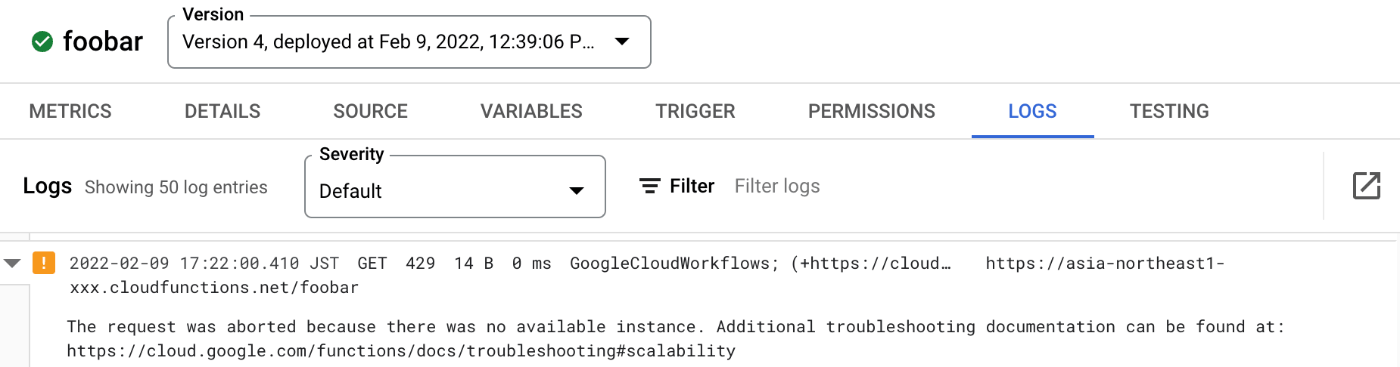
The request was aborted because there was no available instance. Additional troubleshooting documentation can be found at: https://cloud.google.com/functions/docs/troubleshooting#scalability
V2(自動リトライ Exponential Backoff) Workflows
次に本題の自動リトライ(Exponential Backoff)の実装です。
サブワークフロー call_api 内で自動リトライの処理を実装しています。
(リトライ回数を最大5回、初回スリープは10秒に設定)
main:
params: [input]
steps:
- callFunc:
call: call_api
args:
url: https://asia-northeast1-xxx.cloudfunctions.net/foobar
result: api_result
- return_output:
return: ${api_result.body}
# リトライ回数: 5回
# 初回スリープ: 10秒 (2回目 20秒、3回目 40秒、...)
call_api:
params: [url]
steps:
- setup:
assign:
- retry_count: 5
- first_sleep_sec: 10
- sleep_time: ${first_sleep_sec}
- try_many_times:
for:
value: count
range: [1, ${retry_count}]
steps:
- log_before_call:
call: sys.log
args:
text: ${"call_api url=" + url + " (" + string(count) + "/" + string(retry_count) + ")"}
- try_call_block:
try:
steps:
- request_url:
call: http.get
args:
url: ${url}
auth:
type: OIDC
result: api_result
- return_result:
return: ${api_result}
except:
as: e
steps:
- handle_error:
switch:
- condition: ${count >= retry_count}
raise: ${e}
- condition: ${not("HttpError" in e.tags)}
raise: ${e}
- condition: ${(e.code == 429 or e.code == 500)}
next: log_sleep_time
- condition: true
raise: ${e}
- log_sleep_time:
call: sys.log
args:
severity: 'WARNING'
text: ${"got HTTP status " + string(e.code) + ". waiting " + string(sleep_time) + " seconds."}
- wait:
call: sys.sleep
args:
seconds: ${sleep_time}
- update_sleep_time:
assign:
- sleep_time: ${sleep_time * 2}
- next_continue:
next: continue
V1と同様にワークフロー実行コマンドを20回ほど実行。
一番長い実行時間で3分ほどかかるようにはなりましたが、自動リトライによって実行した20回全て処理が成功しています。
ログからも10秒、20秒、40秒、80秒 と 待機した後リトライしている動作が確認できました。

まとめ
Cloud Workflowsでの自動リトライ(Exponential Backoff)の実装を紹介しました。
この自動リトライによりCloud Functionsのスケーリングを待って処理を継続できる効果が確認できました。
プロジェクト単位で同時に実行できるワークフロー数に限りがあるので、大規模なスケールが求められるサービスの場合はFunctions側のスケール設定を調整してスループットの調整も必要になりそうですが、ある程度の規模まではFunctionsのミニマムインスタンス数を減らしてアイドル時間分の料金も抑えられるので、Workflows内にスリープを入れるのはコスト面でも有効な方法だと思いました。(Workflowsの課金体型はステップ数による従量課金で実行時間は含まれないため、Workflowsの実行時間が伸びても追加コストはかかりません。※記事執筆時点 )
Concurrent executions The maximum number of active (started and not yet completed) workflow executions per project => 1,000
参考:
(追記) try/retry文を用いるパターン
Discussion