音声の群遅延なんもわからん
これは日本音響学会 学生・若手フォーラム Advent Calendar 2023 の 11 日目の記事ですが、
群遅延だけに投稿日も遅延してしまいました、すみません......。
群遅延なんもわからん
群遅延
しかしこれを見ても、なぜ周波数について微分するのか?とか、このマイナスなんだよ!とか、直感的に分かりにくいです。
講義や教科書では詳しい説明は省かれることも多く、イマイチよく分かっていない方も多いのではないでしょうか?(私です)
しかしながら、比較的最近の研究 [1-3] でも度々取り扱われる重要な概念なので、知っておいて損はありません。
この記事では、群遅延の意味や興味深い性質について紹介していきます。
群遅延の直感的なイメージ
まず、時間
簡単のため、エネルギーの総和が
と書けます。
エネルギーで重み付けした時刻の平均ということで、
と変形することができます。
ここで出てきた
平均時刻はパワースペクトル
パワースペクトルは周波数領域における信号のエネルギー分布ですから、各周波数のエネルギーで重み付けされた群遅延の和が平均時刻に相当することになります。つまり、信号の各周波数成分は群遅延分だけ遅れていると解釈できます。
音声信号における群遅延
群遅延とパワースペクトル
有声音信号のパワースペクトルには、基本周波数の整数次倍音からなる調波構造が現れることが知られています。では位相、群遅延はどうでしょうか?
以下は上からパワースペクトル、位相、群遅延をプロットしたものです。
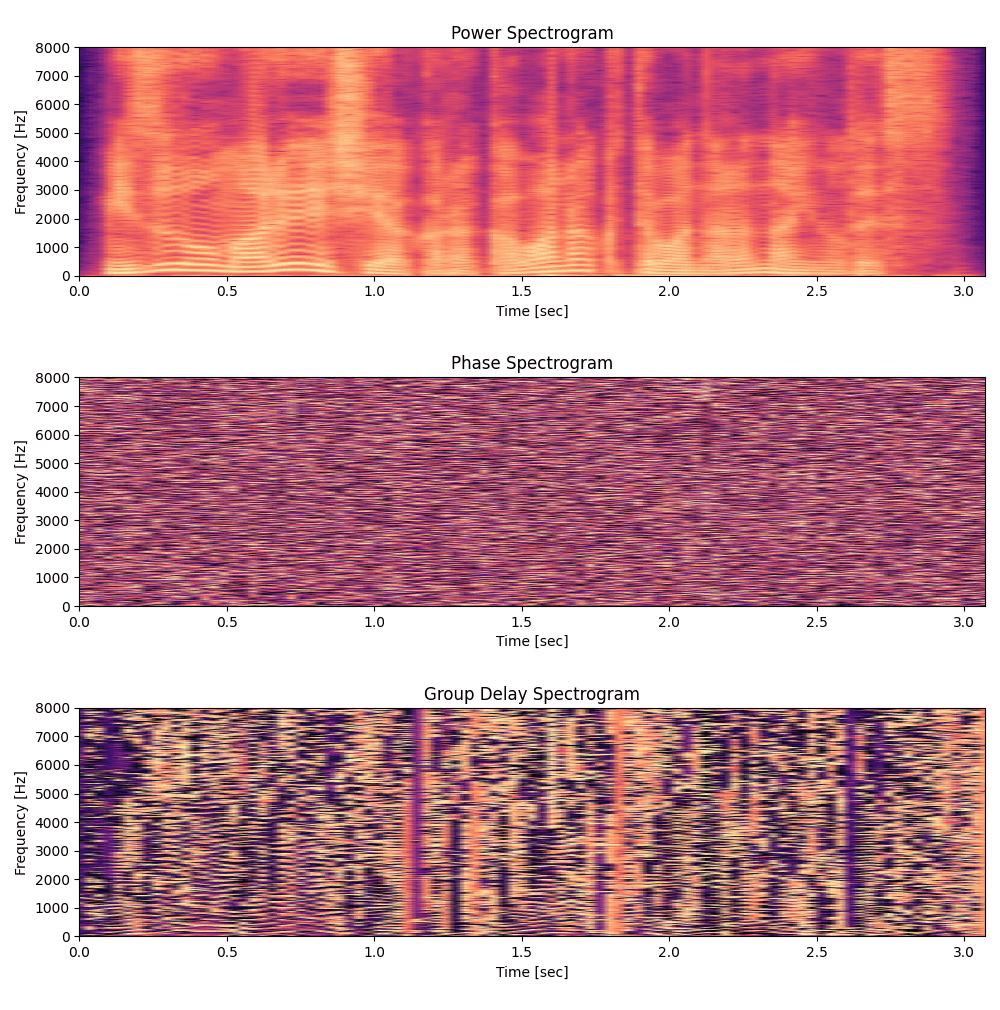
こうして並べてみると位相はランダムに見えるのに、群遅延には調波構造のような急峻なピークが観測されます。群遅延特性は各周波数成分の遅延のみならず、音声の何らかの性質を反映していそうです。
群遅延のピークは調波の谷で現れる
急峻なピークがパワースペクトルの調波に対応した形で現れるのはなぜでしょうか?
ここで、複素スペクトル
群遅延は位相とは異なり時間として求まるので、アンラップの問題を考える必要がありません。
しかし、位相に
これを避ける方法として複素スペクトル
分母にパワースペクトル
このことから、群遅延のピークはパワースペクトルが極小になる周波数成分、つまり調波の谷に現れると期待されます。
群遅延包絡≒先鋭化されたフォルマント
先ほどは調波のような微細構造に着目しましたが、今度はフォルマントのような大局的なピークに注目してみましょう。
まず、スペクトルの共振成分を Linear predictive coding; LPC でモデル化します。
全極型フィルタの
続いて、伝達関数のスペクトルのケプストラムを求めてみます。
まず、対数を取って、
次に、
となり、級数の係数が LPC ケプストラムです。
群遅延は LPC ケプストラムの係数は
合成音声の Buzzy 感との関連
ボコーダや旧来の TTS によって合成された音声はしばしば buzzy と形容されるブザーが鳴ったような音質劣化をともなうことがあります。これは基本周波数が低い音声において顕著です。
なぜこのような劣化が起こるのか完全には解明されてはいないものの、スペクトル包絡の過剰な平滑化や声道フィルタを駆動する音源の位相が原因ではないかと言われています。
位相も関係あるの?と思われるかもしれません。確かに人間の聴覚は基本的に位相の変化に鈍感ですが、150 Hz 以下の位相変化は音色に影響することが知られています [7].
特に、チャネルボコーダの多くは駆動音源に周期インパルス列を利用しています。インパルスはゼロ位相のごく短い急峻な波形変化ですから、基本周期が長くなるとプツプツという音質が際立ちます。その buzzy 感が声道フィルタを畳み込んだ後も残ってしまうのです。
この buzzy 感の根本的な原因の一つとして、インパルスのように波形のエネルギーが時間的に局在していることが考えられそうです。
そこで、波形の持つエネルギーの散らばりとして、波形の平均時刻を中心としたエネルギー分散
この
また平均時刻と同様に、持続時間も位相スペクトル
持続時間は振幅スペクトルと群遅延に依存することが分かります。
したがって、声質を変えずに buzzy 感を低減するには群遅延を制御すればよいことが示唆されます。
おわりに
自身の理解が甘い部分が露呈し、執筆にかなりの時間を費やしてしまいましたがよい勉強になりました。この記事を読んだ皆さんの群遅延に対する理解が 1 マイクロ秒でも進めば幸いです。
もし間違いなどございましたら容赦なく突っ込んでいただけると助かります。
参考文献
[1] Y. Masuyama, et al., “Phase Reconstruction Based On Recurrent Phase Unwrapping With Deep Neural Networks,” in Proc. ICASSP, 2020, pp. 826-–830.
[2] S. Takamichi, et al., “Phase reconstruction from amplitude spectrograms based on directional-statistics deep neural networks,” Signal Processing, vol. 169, p. 107368, 2020.
[3] Y. Ai, et al., “APNet: An All-Frame-Level Neural Vocoder Incorporating Direct Prediction of Amplitude and Phase Spectra,” IEEE/ACM TASLP, vol. 31, pp. 2145-–2157, 2023.
[4] 森勢 将雅, “音声分析合成,” コロナ社, 2018.
[5] L. コーエン, “時間-周波数解析,” 1998.
[6] F. Itakura, et el., “Distance measure for speech recognition based on the smoothed group delay spectrum,” in Proc. ICASSP, IEEE, pp. 1257-–1260, 1987.
[7] R. Plomp, et al., “Effect of phase on the timbre of complex tones,” Journal of ASA., Vol. 46, No. 2B, pp. 409-–421, 1969.
[8] 河原 他, “オールパスフィルタの位相操作による時間構造制御とその知覚への影響について,” 聴覚研究会資料, 1996.
Discussion