"これはdynamodbでいけるわ"が流行語になった2ヶ月間の備忘録
はじめに
私ごとではありますが、現場でdynamodbをメインのデータベースとして採用してから約2ヶ月が経ちました。
たった2ヶ月いう期間で、何度も心身ともに崩壊し、そして粘り強く復活を遂げ、かろうじて奇跡的にレベルアップをしてきました。
今回の記事では、これからdynamodbの導入を検討しているエンジニアの皆様に向けて、わずかながら現場で(汗と血を流しながら)得た知見を共有したいと思います。
主にdynamodbを導入するときに楽できる部分、楽できない、苦労する部分がどんな感じか、この記事でなんとなく伝えられたら嬉しいです。
以下では、4つの項目(採用基準、設計、開発、運用)に分けて、知見を羅列していきますが、私もまだ駆け出しdynamodberの域を出ないので、誤りやアドバイス等ございましたら、是非コメントいただきたいです!
なお、ここで紹介する内容は基本的にはAWSの公式ドキュメントにも記載されている内容を多く含みますので
dynamodbの全てを飲み込みたい方はやはり公式ドキュメントとgithubの旅がおすすめです!(できるだけ関連リンク貼れるようにします)
採用基準
まず今回dynamodbをメインデータベースとして採用した背景には、以下の要因が絡んでおります。
1.パフォーマンスが最優先
プロダクトについて詳しくは言えないですが、パフォーマンスが最優先事項でした。
dynamodbは、たとえ10人のユーザーでも、1億人のユーザーでも、一桁ミリ秒単位での応答を維持できることが魅力的です。当初は部分的に使用しようとしていましたが、急展開でメインテーブルとしました。
2.ローコストな運用がしたい
現状まだ保守運用チームがなく、開発チームが運用も行なっているため、できるだけ運用にコストをかけたくないというのが本音でした。AWSの運用上の優秀性においても、できるだけフルマネージドサービスを使用するというものあり、今回はRDSではなくdynamodbを採用しました。Aurora Serverlessも候補に上がりましたが、後述する理由でdynamodbに決まりました。
可用性の面に関しては、dynamodbのデータは自動的に3つのアベイラビリティゾーン(AZ)にレプリケートされAZでの耐障害性を担保します。さらにGrobal Tableという機能を使用すればリージョン間でもレプリケートされ、99.999% の可用性が実現できます。
バックアップも簡単にできるためローコストの運用としてはかなり魅力的です。
シングルテーブル設計にすれば以下のメリットも
- Iam Roleの管理が1つになる
- カスタマーマネージド暗号化キーは1つのテーブルでローテーションするだけで済む
- 3.マルチテーブル設計に比べてシングルテーブルはトラフィックが滑らかになるため、キャパシティ、コストを管理しやすい(個別株よりもインデックス株の方が価格は安定しやすいみたいなノリです。)
3.そもそも技術的に気になっていた
当初はAurora serverlessとdynamodbの共存を提案していましたが、
そもそもチームメンバーの中で、"現状dynamodbがどのくらいの可能性を持っているか気にならない?"
,"私たちの中で、dynamodbをマスターしている人いなくない?","ならばdynamodb onlyでどこまで行けるかトライしてみない?”といった声が生まれました。最悪dynamodbで無理だと分かったら、皆で速攻軌道修正すれば問題ない、という皆のフッ軽さでこの物語は始まりました。
(元々RDSを採用しようと考えていたので、ER図があったのと、アプリケーション側の実装もrepository層で分けているので、修正の範囲はある程度見込めているという点も楽観的な姿勢に繋がっています。)
こんな感じで、dynamodbの採用が決まりました。
とはいえ、そもそもdynamodbに向いていないことをdynamodb onlyでやるのは苦労するので
まずはクォータの確認であったり、他のブログ記事で紹介されている"できないこと"を確認することが良いと思います。設計、開発の箇所で後述しますが、向いていないことはしっかりあります。
DynamoDBの設計
ここで多くの冒険者は一度は教会送りにされています。RMDSとの設計とは概念が全然異なるため
キャッチアップが必要でした。
ベストプラクティス集を一通り読んだあと以下ような考慮ポイントがあること知りました。
1.シングルテーブルかマルチテーブルのどちらで設計するか
基本的にはシングルテーブルが推奨されています。
主な推奨理由は、パフォーマンスとコストと運用コストの3つです。
パフォーマンス
マルチテーブルにアクセスするよりもシングルテーブルだけのアクセスの方がそりゃレイテンシ低いよねって話です。
コスト
少し話は逸れますが、dynamodbは読み込みリソースと書き込みリソースを
それぞれRCU(Read Capacity Unit),WCU(Write Capacity Unit)という単位で管理します。
読み込み、書き込みコストは、このRCU,WCUをどれだけ消費したかで決定されます。
1RCUで発揮できる性能というのは定められており、
例えば、1RCUは、4KB以下の項目の強力な整合性のある読み込みを行うことができます。
4KBを超えたものは切り上げになるため、5KBの読み込みには、2RCU必要になるわけです。
キャパシティユニットについての詳細は以下のリンクの"キャパシティユニットサイズ"という欄にあります。
話を戻ると、シングルテーブルの場合は、1クエリで複数の項目を取得すれば、RCUを効率的に使用することができます。
例えば、複数の項目を1クエリで4KB取得した場合は、そのまま1RCUになります。
しかしマルチテーブルにすると、それぞれのテーブルに2KBずつ取得したいデータがある場合は、(1クエリで2KBの取得 = 1RCU )で、2クエリ投げることになってしまうので、2RCUが必要になるという感じで非効率です。
そのため、コスト面でもシングルテーブルが推奨されています。
運用コスト
採用基準の箇所でちょろっと記述しましたが1テーブルの方がIamの管理や暗号化キーの管理面でメリットになることが多いです。
これらを鑑みると基本はシングルテーブルが推奨されます。
ただし、RDSからそのままテーブルごとの正規化されたデータを移行するケースである場合や
その他にもチャット履歴や月間集計のデータなど、時間が経つと明らかに更新頻度が低くなっていくようなデータに関してはテーブルでわけてアーカイブまでの仕組みを整理していくのが個人的には良いと思っています。
2.データアクセスパターンの最適化およびPK,SK,LSI,GSIの設計
RDSとdynamodbとでは設計方針はかなり違います。
RDMSでは、テーブルを正規化し、どのようなアクセスパターンに対しても正規化されたテーブルからデータを取得し、返すようなイメージですが、
dynamodbでは、ユーザが頻繁にアクセスするデータアクセスパターンを分析し、項目の保存形式を決定します。
公式documentにある以下のようなモデリング例を見ていただくと感覚がなんとなくわかりますが、
開発者はユーザ目線に立って最適なアクセスパターンを考えなければならないのがRDSとの一番の違いだと思います。
ここを頑張れれば必要なデータを効率よく取得でき、コスト面でも、パフォーマンスでもメリットが大きいです。
個人的にはこのフェーズで何度もdynamodbを投げ出そうとしました。そして逃げようとした瞬間に、ピクシス司令の"この苦しみを自分の親や兄弟、愛する者に味わわせたい者もここから去るがいい!"という言葉が脳裏によぎり、再び立ち向かうことを決意しました。
そして設計段階では多対多の概念をdynamodbに落とし込むのが少し苦労しました。
多対多の設計
以下のdocument記載の多対多のモデリングが参考になります。https://docs.aws.amazon.com/amazondynamodb/latest/developerguide/bp-adjacency-graphs.html
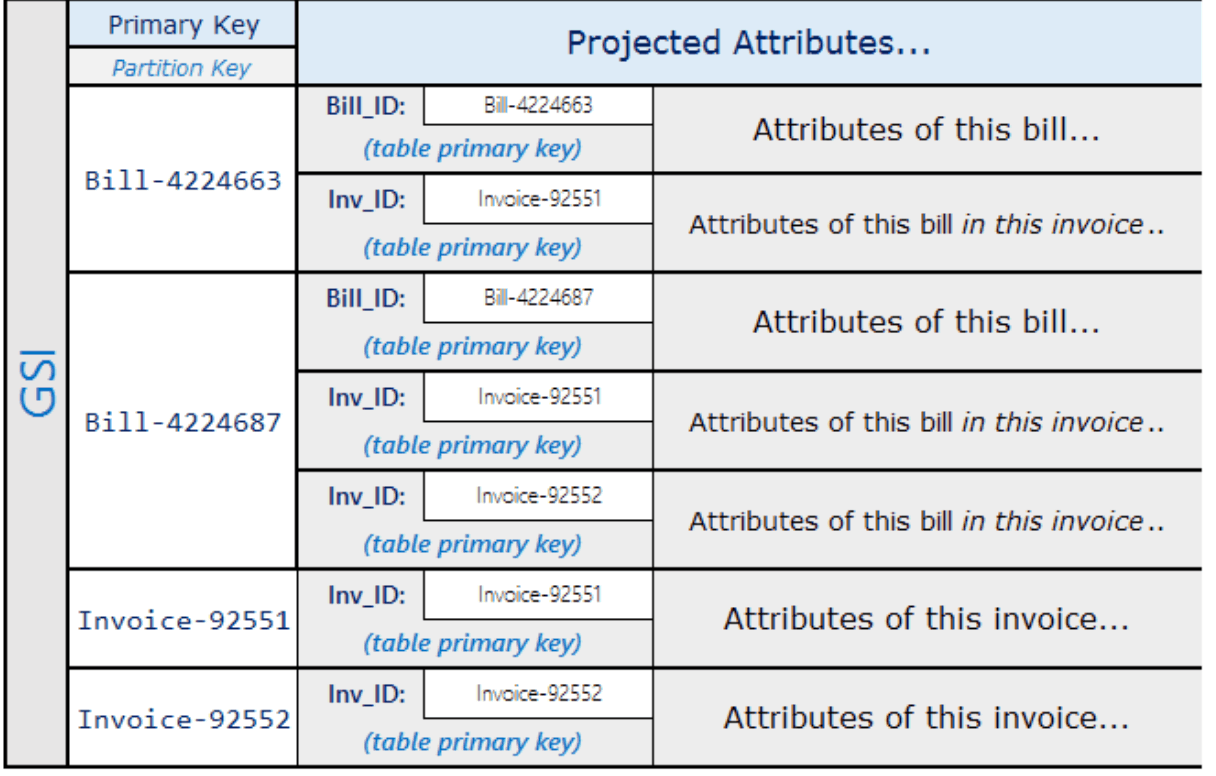
上記のモデリングの時に
例えばBill-4224687に紐づくInvoice一覧を取得したい場合は、2クエリで済みます。
1.PKがBill-4224687かつSKがInvoiceから始まる項目を取得するクエリ
2.dynamodbのBatchGetItemでPK,SKをInvoice-番号にし、一括でデータ取得するクエリ
上記でギリできるのですが、多対多の関係ではGSIを1つ消費するので、多対多がたくさんあるシステムにはあまり向いていないのかなと思います。
また、dynamodbは一覧画面があるシステムにはあまり向いていないのかなと個人的に感じます。
きついシーン
上記の多対多の例をまた用いると、例えばBill一覧画面で、紐づくInvoice情報を出したい要件があった場合
以下のような流れになります。
1.まずBill一覧を取得するためのGSIをはるか、Scan等で頑張った後、
2.取得した各BillIdに対して、紐づくInvoice情報を取得するには、さらなるリクエスト(1つ上のアコーディオンの1と2のリクエスト)を行わなければならず、n+1問題にもなっています。
私のケースでは、open searchを検索機能として導入予定だったため、こちらのケースはopen searchで対応することにしました。
3.クォータの確認
dynamodbには様々なクォータがあります。
例えば1項目(1レコード)の保存サイズのクォータは400KBになります。一応400KBを超える場合は、複数項目に分割するという垂直パーティショニングという抜け道もあります。↓↓↓
さらに、データのresponseサイズは1MBという制約もあるため、地味に煩わしいケースが多くあります。
総じてdynamodbの設計は、RDSとは全然違く、いきなりベストプラクティスな設計は難しく日々鍛錬あ
るのみという茨道でした。
開発
1.O/Rマッパーの選定
開発はNode.js環境であったため、Node.jsで使用できるO/Rマッパーを調べました。
調べるうちに、dynamooseや、TypeDORMなどのO/Rマッパーが候補にあがりましたが、
npm trendsで見てみると、6月ごろからどうやらelectroDBというO/Rマッパーが爆発的人気を得ているようです。
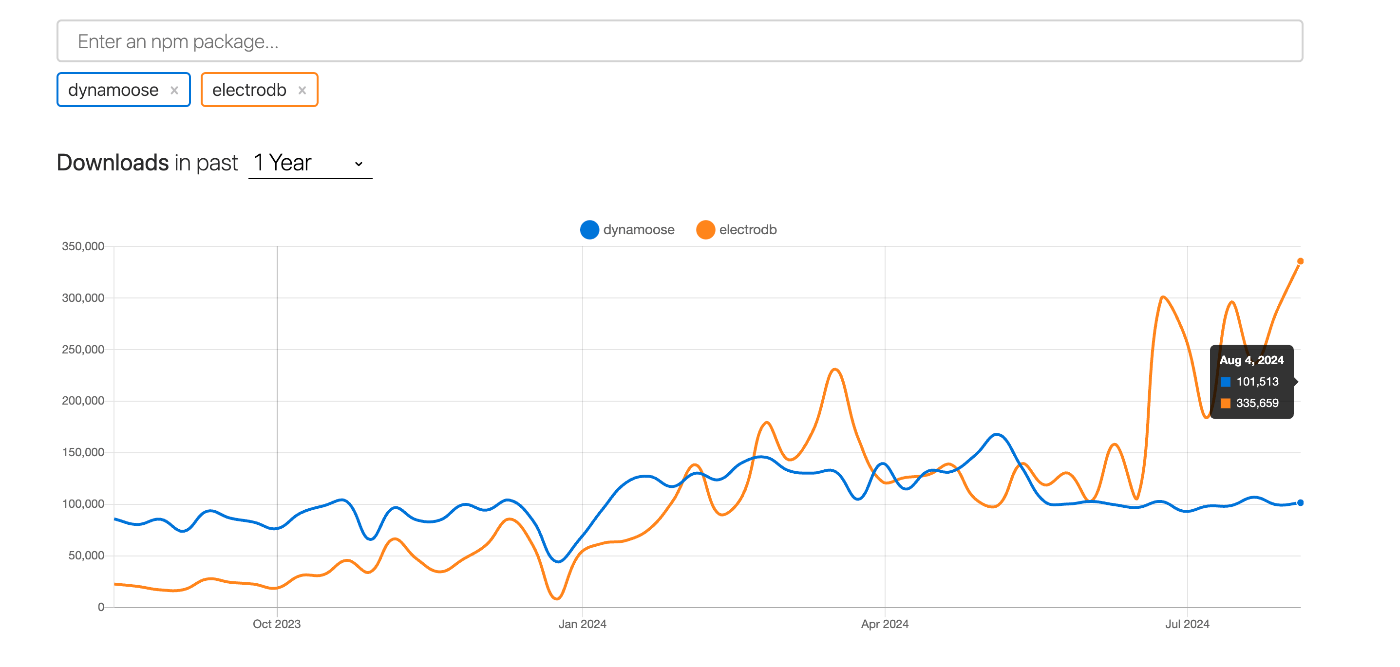
実際に機能を見ていくと、upsertやcountなどdynamooseにはなさそうな高レベルのapiも存在していたため、こちらを使用することに決めました。
O/Rマッパーを採用しようがしまいが、正直dynamodbのapiができることの全てなので、採用せずに自力で書いても良いと思います。今回は、自力で書くコストを削減したかったので頼りました。
2.開発機能でこれは向いていないポイント
-
検索機能系はきついです
dynamodbだけで検索機能は無理です、大文字、小文字の検索すら実装が難しいです。
基本は外部の全文検索サービスを使用するかawsで対応するならopen searchだと思います。
ただopen searchはかなり高価で、簡単に手が出せるものではありません。
そのため、検索機能が必要な場合、プロダクトが小中規模であればRDSを用いてコンパクトに対応するのが良いと思います。 -
レスポンスサイズが1MBを超えるリクエストが多くある
前述しましたが、dynamodbのクォータが1リクエストで1MBなのでそこの制約が鬱陶しい場合は採用しない方が良いです。 -
ページネーションの前送りもきつい
https://zenn.dev/hsaki/articles/aws-dynamodb-non-suited
こちらの記事に書かれている通りです。無限スクロールにして回避することはできます。 -
多対多系の処理がたくさんあるシステム
できなくはないですが、実装が面倒なのと、dynamodbに慣れていないエンジニアだと初期のキャッチアップコストがかなり高くはなってしまうかと思います。
dynamodbの運用
フルマネージドなため、運用の手間は削減できます。ここら辺はdynamodbの強みかと思います。
1.スケーリングについて
オンデマンドモード(勝手にスケールしてくれるやつ)と、プロジョンドキャパシティモード(事前予約するやつ)かで変わります。
オンデマンドモードであれば、公式documentには以下の記載があります。
新しいオンデマンドテーブルでは、1 秒あたり最大 4,000 回の書き込みと 1 秒あたり最大 12,000 回の読み込みを維持できます。オンデマンドキャパシティーモードは、テーブルにおける前のピークトラフィックの最大 2 倍まで瞬時に対応します
30分以内にトラフィックが2倍になる場合は、スロットリングエラーが出るそうなので、あまりないとは思いますが、
想定される場合は、キャパシティモードにするか、DAXでキャッシュ対応するなどしたら良いと思います。
プロビジョンドキャパシティモードのスケーリングについては、auto scalingの仕組みがあります。
cloudwatchから読み取り書き込みに使用率をみて、キャパシティの増加減少を行うことができます。
また、瞬発的なトラフィックの増加であれば"バーストキャパシティ"とアダプティブキャパシティという仕組みにより、できるだけ耐えるように設計されています。
プロダクトの初期フェーズはオンデマンドモードで良いと思いますが、トラフィックがある程度安定してきた時期や
コスト削減したい場合は、プロビジョンドキャパシティモードに切り替えリザーブドキャパシティで契約すると良いと思います。
2.可用性
dynamodbは基本3つAZにデータをレプリケーションし可用性を高めてくれます。
Grobal Tableを利用すれば、リージョン間で99.999%の可用性を保つことができます。
3.バックアップ
ポイントタイムリカバリ機能を有効にすれば、最大35日間前までのバックアップを取ることが可能になります。
これもただ機能を有効にすれば良いだけなので楽ちんです。
また、dynamodb オンデマンドバックアップ機能を使用し、テーブルの完全なバックアップを作成して、規制コンプライアンスの要件を満たすために長期間の保存とアーカイブを行うことも可能です。
- データ分析要件
Amazon Athena DynamoDBコネクタがあり、Athenaと連携してデータ分析が可能。
s3にexportも容易にできるため幅広いサービスと連携可能になります。
今日まで使用してみての感想
まずは、色々発見があって楽しかったです!
運用コスト削減と、パフォーマンスを求めてdynamodbを採用するのは良い選択だと思います。
ただ、現状は全てのプロダクト要件をdynamodbで網羅しようとすると開発面でかなりの工夫と工数と犠牲者が必要になってくるため、メインテーブルではなく、部分的に採用するのが無難なのかなと思います。
具体的には、ワンタイムパスワードやユーザのsession管理など、一時的に使用するデータの置き場にはピッタリで、その他にも多対多のリレーションをあまりはらないようなシステムであれば、その力を十分に発揮できると思います。
また、おそらく多くの現場では、dynamodbの設計、開発に慣れている開発者も少なく、インターネット上の事例もまだ豊富ではないので、チームへの教育体制も必要になってくると考えると、メインで採用する可能性は薄いのかなと思います。
終わり
まだまだプロダクトも初期フェーズなので、さらに開発•運用を進めていく上で引き続きdynamodbの可能性を探っていこうと思います。
これからopen search serverlessの検索機能の導入や、dynamodbを用いたベクター検索機能も実装予定なので、また知見がアップデートされたら、記事を書こうと思います。
最後までお読みいただきありがとうございました!
おまけ:良い記事一覧
Discussion