dbt-osmosisをつかって、メタデータ管理を楽にする
はじめに
dbtでは、各種モデルのメタデータをyamlファイルで管理できます。一方で、依存関係の多いデータモデリングの世界では、すべてのモデルのメタデータを手作業で管理するには限界があります。
例えば、上流のモデルのメタデータが変更された場合(列の定義など)は、そのモデルを継承するモデルのすべてのメタデータを同時に更新する必要があり、かなりの運用コストになるのは想像にかたくないです。
今回は、そんなdbtのyaml管理を楽にしてくれるdbt-osmosisを使用して、どこまで運用コストが削減できるかためしてみます。
事前準備
実行dbtプロジェクトは、チュートリアルであるjaffle_shopレポジトリを使用します。事前準備として、各種モデルをDWH上に作成しおきます。(ローカルでも、BigqueryでもなんでもOKです。)
パッケージは、pipでインストールします。
pip install dbt-osmosis
続いて、プロジェクトファイルにdbt-osmosisの設定を追加します。追加するのは、+dbt-osmosis: "{yaml名}.yml"のみです。モデルごとにyamlファイルを作成する({model}.ymlとする)こともできますし、すでにyamlファイルが存在する場合は名前をあわせます。(今回はschema.yml)
また、フォルダごとに異なった名前でyamlファイルを管理している場合でも柔軟に設定できます。
設定はこれだけです!
models:
jaffle_shop:
+dbt-osmosis: "schema.yml"
materialized: table
staging:
materialized: view
+dbt-osmosis: "schema.yml"
実行
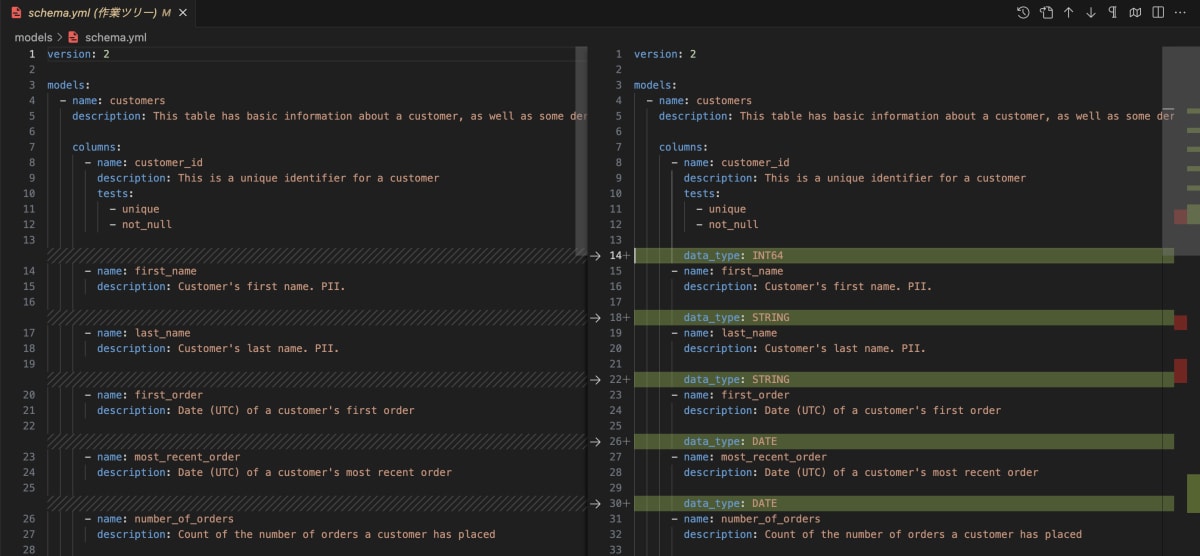
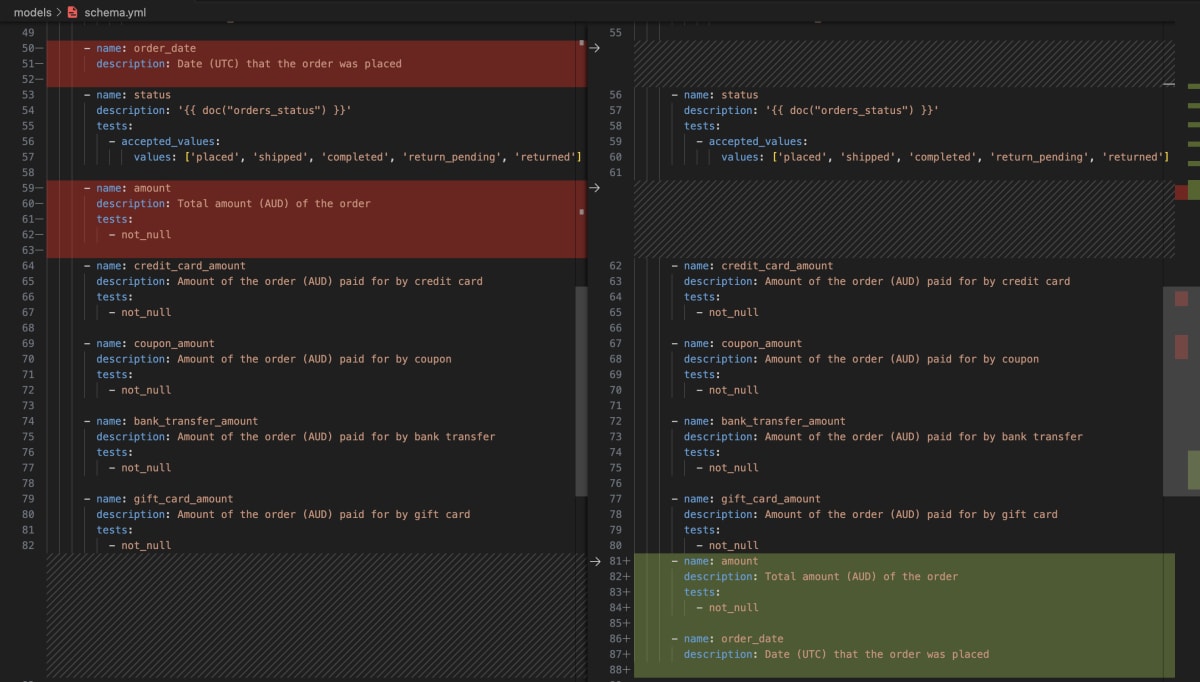
さて、いきなりですが実行して、yamlファイルを確認してみます。(左が実行前、右が実行後です)
dbt-osmosis yaml refactor
実行によって、以下が自動で行われます。
- descriptionの追加
- 列型の追加
- 列の追加
- 列順の並び替え(DWH上のテーブルにあわせる)
実行前後の比較
ここで注意点ですが、yamlファイルには最低限modelのnameを追加する必要があります。試しに、以下のようにschema.ymlから、customersに関する部分を削除して、実行するとKeyError: 'sources'とエラーがでてきます。
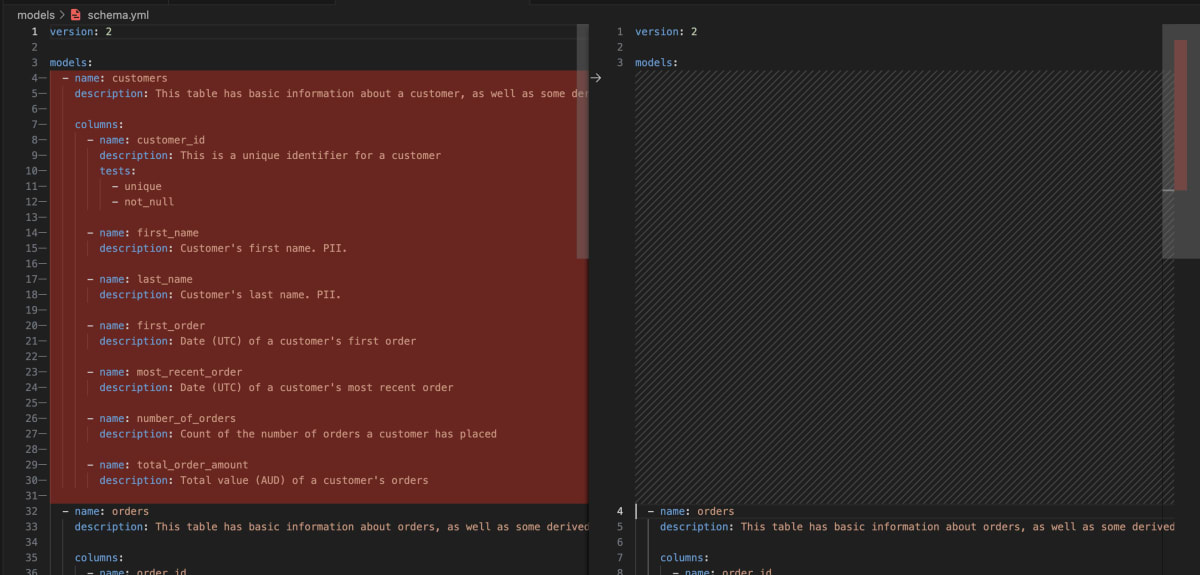
逆にいうと、modelのnameさえ記載があれば、列名の記載などはテーブルから読み込んで勝手に補完してくれるということですね。
descriptionの伝播
これだけでも随分と便利なのですが、dbt-osomosisの個人的な真価は、列のdescription(以下列description)を伝播させられることです。これは、上流のモデルの列descriptionさえ管理しておけば、列を継承しているすべての下流モデルの列descriptionは、勝手に更新されるということです。
jaffle_shopの例では、customersモデルのcustomer_idは、stg_customersモデルのcustomer_idを継承してます。まずは、stg_customersモデルのcustomer_idのdescriptionのみを記載しておき、先ほど同様に実行します。
すると、上流のdescriptionがしっかりと継承されています。(列名が同一の場合のみ)
stg_customersのyamlファイル
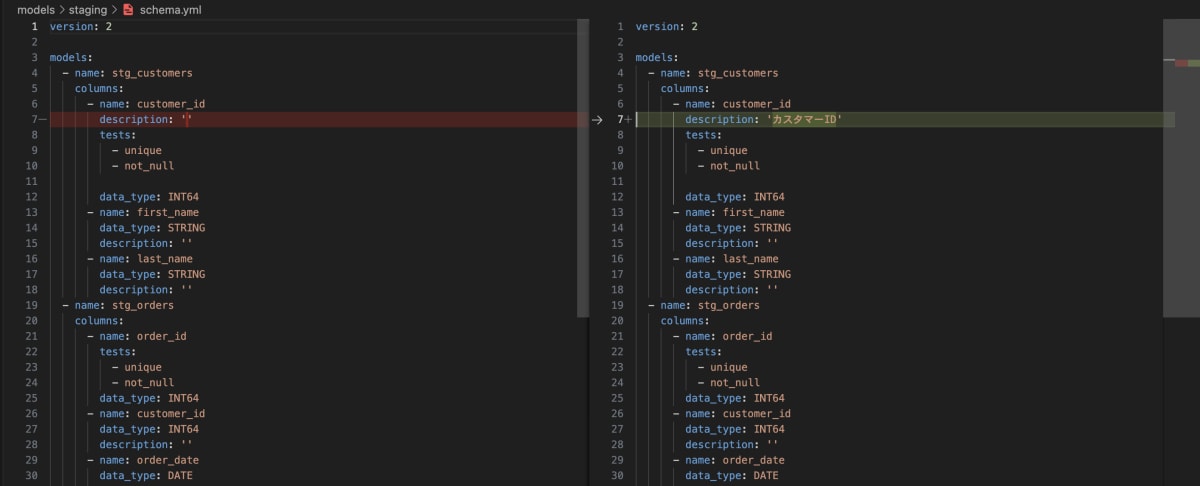
customersのyamlファイル
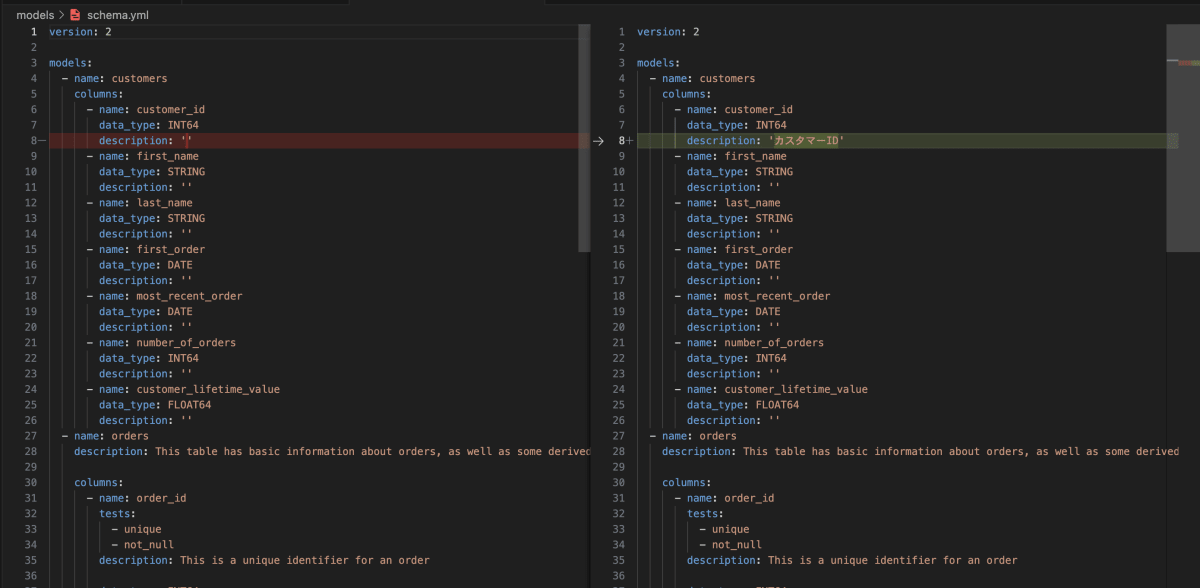
ただし、もう一度stg_customersの列descriptionを更新しても、下流モデルのdescriptionは更新されません。実は、デフォルトで空のdescriptionのみを対象するので、すでに記載がある場合は更新されません。
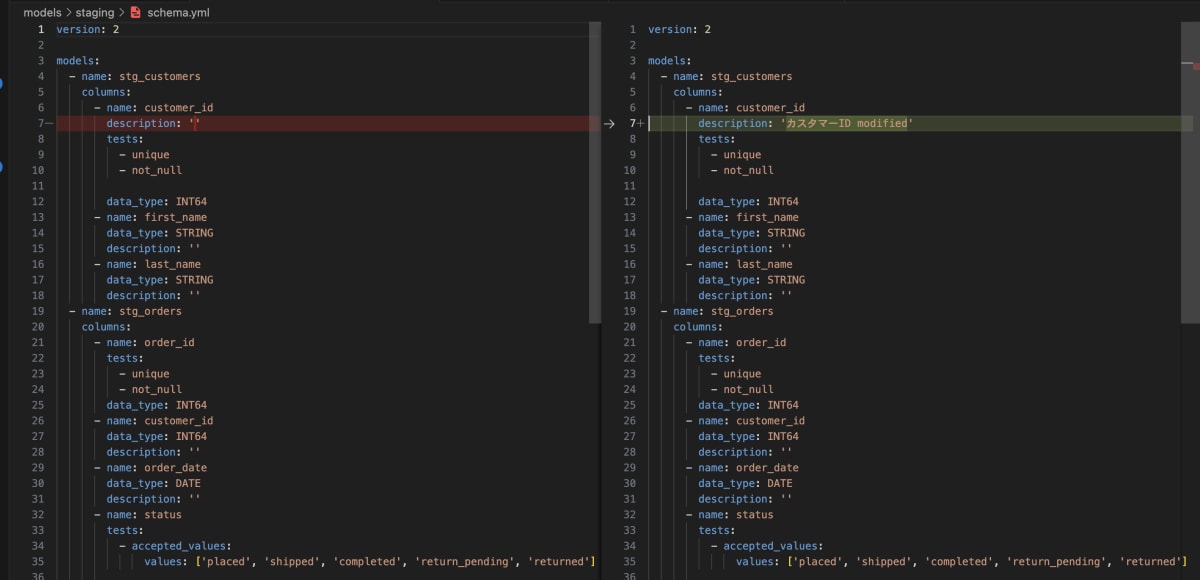
以下のようにすれば継承を強制することもできます。(下流モデルに特記したdescriptionがある場合でも、強制的に上書きさされてしまうので注意です!)
dbt-osmosis yaml refactor --force-inheritance
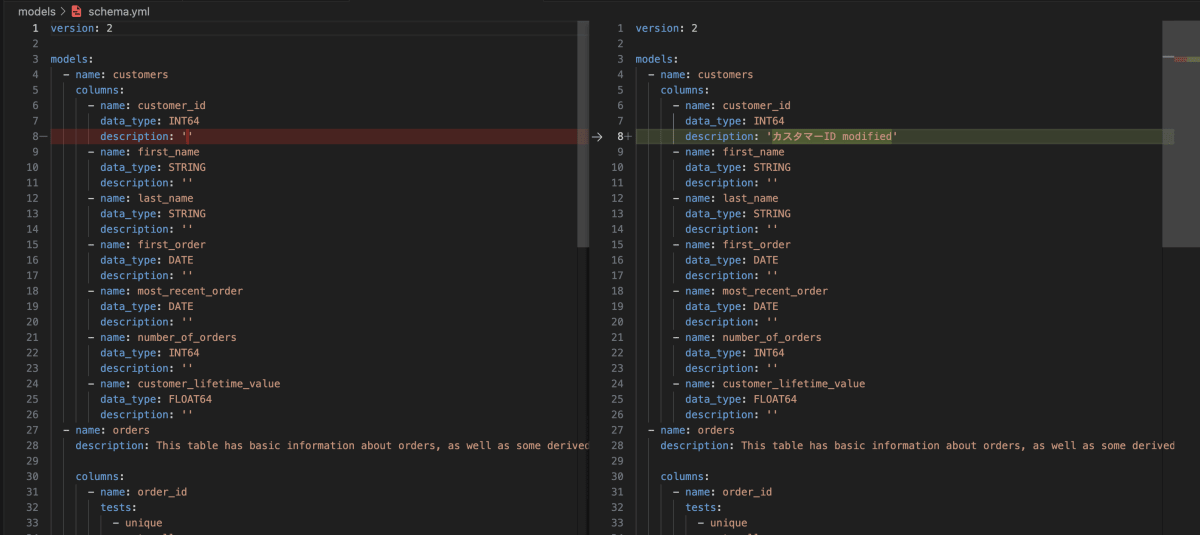
無事に更新されました。
まとめ
どこをマスターとして列descriptionを管理していくのか?下流モデルの特記事項をどう管理するのか?同名異義の列名をどうするか?など考慮すべき点はいくつかありそうですが、dbt-osomosisを使えば、メタデータの運用コストをかなりさげられそうな気がしてきましたね。
メタデータ管理は、運用コストをできるだけ減らして高い品質を担保することが重要なので、積極的に活用していきたいです。
参考
Discussion