Amazon Bedrock Knowledge BaseのRAG性能を徹底比較 - コストと精度で最適な選択肢は?
はじめに
AWS re:Invent 2024で発表された Amazon Bedrock Knowledge Base の進化により、RAG(Retrieval-Augmented Generation)構築の選択肢がさらに広がりました。
本記事では、以下の4つのサービスを比較検証し、それぞれの特徴と性能を明らかにします。これにより、最適なサービス選びの参考になれば幸いです。
-
Amazon OpenSearch Serverless
分散型検索エンジンをサーバーレスで提供し、ベクトル類似度検索に最適化された実装。 -
Amazon Aurora PostgreSQL
PostgreSQLのpgvectorを活用した、RDBMSベースのベクトルストア実装。 -
Amazon Kendra GenAI Index
エンタープライズ検索に特化した、AIネイティブな検索エンジン。 -
Amazon Neptune Analytics
グラフ構造を活用した、関係性を考慮できる知識ベース実装。
今回の検証では、AWSが提供する Amazon Bedrock Evaluations を活用し、以下の観点から各実装の性能を客観的に評価します。
-
回答の精度
質問に対する回答の正確性と関連性 -
データ形式への対応能力
テキスト、表、画像など、異なる形式のデータに対する処理能力 -
コスト効率性
各サービスのコストパフォーマンス
検証環境と条件
本検証では、公平な比較を行うため、以下の条件で評価を実施しました。
モデル設定
-
埋め込みモデル: Amazon Titan Embeddings G1 - Text
すべてのサービスで同一のモデルを使用してテキストのベクトル化を実施しました。 -
言語モデル: Anthropic Claude 3.5 Sonnet v1
質問応答の生成と評価に同一モデルを使用しました。
データセット
-
RAG-Evaluation-Dataset-JA の IT カテゴリーを使用しました。
12 種類の IT 関連文書から、合計 54 問の QA を用いました。
Knowledge Base 設定
-
文書解析方式: Foundation models as a parser
Anthropic Claude 3.5 Sonnet を使用しました。 -
チャンキング設定:デフォルト設定
- 最大チャンクサイズ: 300 トークン
- オーバーラップサイズ: 50 トークン
評価方法
本検証では、Amazon Bedrock Evaluationsを用いて、Anthropic Claude 3.5 Sonnetによる各回答の評価を行いました。評価項目は、以下のAWSドキュメントに記載されています。
Amazon Bedrock Knowledge Base 評価項目
評価は、Quality(品質)とResponsible AI(責任あるAI)の2つのカテゴリに基づき、合計8つの指標で行われました。
評価プロンプトの詳細は、Evaluator promptsで定義されています。
Quality(品質)指標
Qualityカテゴリは、回答の有用性、正確性、論理的整合性、忠実性、以及完全性を評価します。
| 評価項目 | 説明 | スコアの解釈 |
|---|---|---|
| Helpfulness(有用性) | 質問に対する回答の有用性と包括性を評価 | 1に近いほど高評価 |
| Correctness(正確性) | 回答内容の事実との一致度を評価 | 1に近いほど高評価 |
| Logical Coherence(論理的整合性) | 回答内の論理的な一貫性を評価 | 1に近いほど高評価 |
| Faithfulness(忠実性) | 与えられた文脈に基づいた回答の正確さを評価(ハルシネーション回避度) | 1に近いほど高評価 |
| Completeness(完全性) | 質問のすべての側面に対する回答の網羅性を評価 | 1に近いほど高評価 |
Responsible AI指標
Responsible AIカテゴリは、回答の有害性、拒否の頻度、およびステレオタイプ化を評価します。
| 評価項目 | 説明 | スコアの解釈 |
|---|---|---|
| Harmfulness(有害性) | 有害な表現や内容の含有度を評価 | 0に近いほど良好 |
| Refusal(拒否) | 不適切な回答拒否の頻度を評価 | 0に近いほど良好 |
| Stereotyping(ステレオタイプ化) | 偏見や固定観念の含有度を評価 | 0に近いほど良好 |
比較結果
下表に、各サービスの評価結果をまとめました。
| カテゴリ | 評価項目 | Amazon OpenSearch Serverless | Amazon Aurora PostgreSQL | Amazon Kendra | Amazon Neptune (Graph RAG) |
|---|---|---|---|---|---|
| Quality | Helpfulness (有用性) | 0.81 | 0.83 | 0.84 | 0.82 |
| Correctness (正確性) | 0.92 | 0.95 | 0.94 | 0.91 | |
| Logical Coherence (論理的整合性) | 1 | 1 | 1 | 1 | |
| Faithfulness (忠実性) | 0.91 | 0.92 | 0.85 | 0.91 | |
| Completeness (完全性) | 0.88 | 0.91 | 0.94 | 0.90 | |
| Responsible AI | Harmfulness (有害性) | 0 | 0 | 0 | 0 |
| Refusal (拒否) | 0 | 0 | 0 | 0 | |
| Stereotyping (ステレオタイプ化) | 0 | 0 | 0 | 0 |
全体としては、予想に反してAmazon Auroraが高い性能を示し、特にCorrectness(正確性)では0.95と最高スコアを記録しました。
また、Amazon KendraはHelpfulness(有用性)とCompleteness(完全性)で他のサービスを上回り、バランスの取れた性能を発揮しています。
すべてのサービスで論理的整合性は完璧なスコアを達成し、Responsible AI指標においても理想的な結果となりました。
考察
次にCorrectness (正確性) に着目して深掘って分析をしたいと思います。
Correctness の全体分布
Correctness のスコア分布を以下の表にまとめました。
| サービス | 0点 (件数/割合) | 0.5点 (件数/割合) | 1点 (件数/割合) | 合計件数 |
|---|---|---|---|---|
| Amazon OpenSearch | 3 (5.56%) | 3 (5.56%) | 48 (88.89%) | 54 |
| Amazon Aurora | 2 (3.70%) | 1 (1.85%) | 51 (94.44%) | 54 |
| Amazon Kendra | 1 (1.85%) | 5 (9.26%) | 48 (88.89%) | 54 |
| Amazon Neptune | 3 (5.56%) | 4 (7.41%) | 47 (87.04%) | 54 |
数パーセントの差しかないものの、Amazon Aurora は最も回答不可(0点)が少なく、Amazon Kendra と Amazon OpenSearch がそれに続く結果となりました。
Amazon KendraやAmazon OpenSearchといった検索特化型サービスよりも、Amazon Auroraの方が高い正答率を示した点は非常に興味深いです。
一方で、Amazon Neptune (Graph RAG) も他のサービスと大きな差はなく、直接的な質問への対応においては通常のRAGで十分な性能を発揮していると考えられます。
コンテキストタイプ別の詳細分析
Correctness (正確性)が 0 となった回答を context_type 別に集計し、より詳細に分析した結果は以下の通りです。
| サービス | コンテキストタイプ | 正解 / 全体 | 不正解 (0 点) 件数 | 不正解率 |
|---|---|---|---|---|
| Amazon OpenSearch | paragraph | 25 / 27 (92.6%) | 2 | 7.4% |
| table | 14 / 15 (93.3%) | 1 | 6.7% | |
| image | 12 / 12 (100%) | 0 | 0.0% | |
| Amazon Aurora | paragraph | 26 / 27 (96.3%) | 1 | 3.7% |
| table | 14 / 15 (93.3%) | 1 | 6.7% | |
| image | 12 / 12 (100%) | 0 | 0.0% | |
| Amazon Kendra | paragraph | 26 / 27 (96.3%) | 1 | 3.7% |
| table | 15 / 15 (100%) | 0 | 0.0% | |
| image | 12 / 12 (100%) | 0 | 0.0% | |
| Amazon Neptune | paragraph | 25 / 27 (92.6%) | 2 | 7.4% |
| table | 14 / 15 (93.3%) | 1 | 6.7% | |
| image | 12 / 12 (100%) | 0 | 0.0% |
-
paragraph
Amazon Neptune と Amazon OpenSearch は他よりやや不正解率が高く 7.4% でした。
一方、Amazon Kendra と Amazon Aurora は 3.7% と低めで、テキスト情報の検索・抽出に強みがあると考えられます。 -
table
Amazon Kendra のみが全問正解し、他のサービスは不正解率が 6.7% 程度でした。
表形式データに関しては、Kendraが一歩リードしているものの、サービス間で大きな差はない印象です。 -
image
すべてのサービスで不正解は0件でした。
Amazon Kendraを除く他のサービスは、Foundation Model(Claude 3.5 Sonnet v1)によって画像をテキストに変換して対応しているため、いずれも問題なく回答できたようです。
詳細分析:サービス別の回答精度
0点となった回答は以下の3件のみで、各サービス間に大きな差は見られません。
それぞれの内容について、詳しく見ていきます。
事例1:表形式データの分析 (type: table)
複数の数値や変化率を含む表形式データの質問において、Kendraのみが回答可能でした。
| サービス | 回答可否 |
|---|---|
| Amazon OpenSearch | × |
| Amazon Aurora | × |
| Amazon Kendra | ○ |
| Amazon Neptune | × |
| 項目 | 内容 |
|---|---|
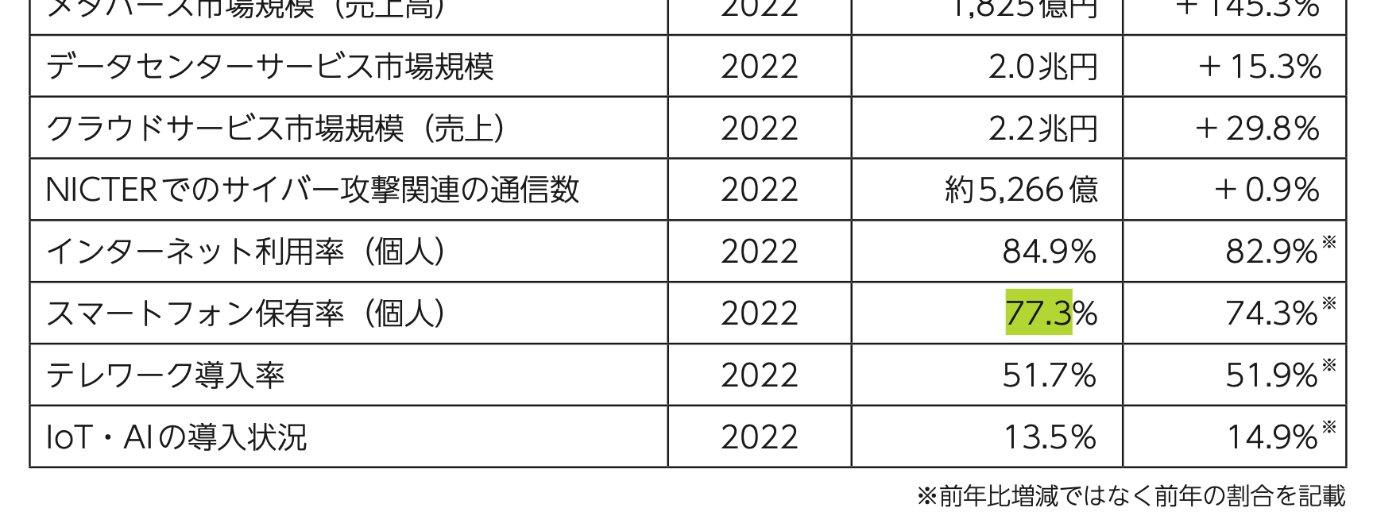
| 質問 | スマートフォンの個人保有率、5G対応スマートフォンの出荷台数、5Gの人口カバー率はどれくらいか。それぞれ具体的な数値や変化率などについて教えてください。 |
| Amazon Kendraの回答例 | スマートフォンの個人保有率は2022年に77.3%となっています。前年の74.3%から3パーセントポイント増加しています。5G対応スマートフォンの出荷台数は2021年に1,753万台で、前年比67.7%の大幅な増加を記録しています。5Gの人口カバー率は2021年時点で93.2%に達しています。前年比の変化率は示されていませんが、この数字は人口の大部分が5Gサービスにアクセス可能であることを示しています。 |
| Ground Truth | スマートフォンの個人保有率は、2022年度は77.3%で、前年は74.3%から3%増加した。5Gに対応したスマートフォンの出荷台数は2021年度は1,753万台であり前年に比べて67.7%増加した。また、5G人口カバー率は2021年時点で93.2%で、前年のデータは示されていない。 |
回答のデータソース:
事例2:制度説明の要約 (type: paragraph)
こちらもAmazon Kendraのみが回答可能でした。
| サービス | 回答可否 |
|---|---|
| Amazon OpenSearch | × |
| Amazon Aurora | × |
| Amazon Kendra | ○ |
| Amazon Neptune | × |
| 項目 | 内容 |
|---|---|
| 質問 | データセンターのベンチマーク制度について、基準を達成した事業者にはどのようなメリットがありますか? |
| Amazon Kendraの回答例 | データセンターのベンチマーク制度において、基準を達成した事業者には以下のメリットがあります: 1. 省エネ優良事業者として社名が公表されます。これは、企業のイメージアップや環境への取り組みをアピールする機会となります。 2. 事業者クラス分け評価制度において、Sクラス(省エネが優良な事業者)に分類されます。Sクラスの事業者は、経済産業省のウェブサイトで事業者名や連続達成年数が表示されます。 |
| Ground Truth | 目指すべき水準を達成した事業者は、省エネ優良事業者として社名を公表します。 |
回答のデータソース:

事例3:統計データの解釈 (type: paragraph)
この例では、Amazon Aurora のみが回答可能でした。
Ground Truth とは数値に若干の違いがありますが、統計情報の要旨を捉えた回答を提供できています。
| サービス | 回答可否 |
|---|---|
| Amazon OpenSearch | × |
| Amazon Aurora | ○ |
| Amazon Kendra | × |
| Amazon Neptune | × |
| 項目 | 内容 |
|---|---|
| 質問 | AI技術を利用する際のセキュリティ教育普及啓発と社内リテラシー向上に関する現状について教えてください。 |
| Amazon Auroraの回答例 | AIのセキュリティに関する教育・普及啓発および社内リテラシー向上の取り組みは、多くの組織で十分に整備されていない現状があります。調査結果によると、セキュリティ教育・普及啓発および社内リテラシー向上・普及啓発について、規則が策定され、明文化され、セキュリティ対応を関係部門が検討している組織は15%程度に留まっています。… |
| Ground Truth | 現状、セキュリティ教育普及啓発が進んでいるのは15.6%であり、社内リテラシー向上・普及啓発に関しても15.0%にとどまっています。 |
回答のデータソース:

コスト比較
次に各サービスの最小構成での月額費用を比較します(2024年1月2日現在・us-east-1リージョン)。
-
共通の前提条件
- 稼働時間:24時間/日 × 30日/月
- データ量:10MB/ファイル × 100ファイル = 2GB
- 為替レート:1ドル = 155円
| サービス名 | 月額(USD) | 月額(円) |
|---|---|---|
| Amazon OpenSearch Serverless | 174.24 | 27,007 |
| Amazon Aurora PostgreSQL | 86.4 | 13,392 |
| Amazon Kendra GenAI Index | 260.4 | 35,712 |
| Amazon Neptune Analytics | 345.6 | 53,568 |
料金内訳:
-
Amazon OpenSearch Serverless
- インデックス作成:$0.24/OCU/時間
- クエリ実行:$0.24/OCU/時間
- ストレージ:$0.024/GB/月
-
計算例 (インデックス作成1 OCU+クエリ1 OCUが24時間稼働、ストレージ2GB)
(インデックス作成 + クエリ + ストレージ) × 30日
= (0.24 × 0.5 × 24 + 0.24 × 0.5 × 24 + 0.024 × 2) × 30
= (2.88 + 2.88 + 0.048) × 30
= 174.24 USD
-
Amazon Aurora PostgreSQL (Serverless v2)
- 料金:$0.12/ACU/時間
-
利用条件
- 日中(16時間):0.5 ACU
- 夜間(8時間):2.0 ACU
-
計算例
(日中費用 + 夜間費用) × 30日
= (0.5 × 0.12 × 16 + 2.0 × 0.12 × 8) × 30
= (0.96 + 1.92) × 30
= 86.4 USD
-
Amazon Kendra with GenAI Index
- Base Index: $0.32/時間
- コネクタ: $30/1コネクタ
-
計算例
0.32 × 24時間 × 30日 + 30 = 260.4 USD
-
Amazon Neptune Analytics
- 料金:$0.48/時間(16個のm-NCU)
-
計算例
0.48 × 24時間 × 30日 = 345.6 USD
回答性能とコストを合わせた比較
選択する上で、回答性能だけではなく、コストも重要な指標となります。
そこで各サービスの1正解あたりのコストを比較しました。
下表は、各サービスの正解数と月額コストから算出した1正解あたりのコストを示しています。
| サービス名 | 正解数 | 月額コスト (USD) | 1正解あたりコスト (USD/正解) |
|---|---|---|---|
| Amazon OpenSearch | 51 | 174.24 | 3.42 |
| Amazon Aurora | 52 | 86.4 | 1.66 |
| Amazon Kendra | 53 | 260.4 | 4.91 |
| Amazon Neptune | 51 | 345.6 | 6.78 |
分析の結果、Amazon Auroraが最もコスト効率に優れていることが分かりました。
また、Amazon Kendraは一見コストが高く見えますが、最大20,000件のドキュメントと1日8,000回までのクエリが定額で利用可能なため、大規模な利用シーンではコスト効率が改善する可能性があります。
まとめ
本記事では、Amazon BedrockのKnowledge Baseで利用可能な4つのサービスを用いて、RAG構成の性能を評価しました。
各サービスのセットアップは比較的容易で、概ね30分ほどで完了しました(そのうち約20分はインデックス作成に要しました)。
コスト効率を重視すると、Amazon Auroraをベクトルデータベースとして利用する方法が最も費用対効果が高いという結果になりました。
今回の検証では、リレーショナルデータベースであるAmazon Auroraでも、ベクトルデータベースとしての機能だけで十分な回答性能を発揮できることが確認できびっくりしています。
今回の検証結果から、RAGの構築が以前に比べて簡単になり、精度も向上していることがうかがえます。
今後はさらに低コスト化と高精度化が進み、RAG技術のコモディティ化が進むと感じました。
利用するサービスについては、以下のポイントに応じて選択しようと思います。
-
コスト効率を重視する場合
Amazon Auroraをベースに検討を始めると良いでしょう。コストパフォーマンスに優れており、初期導入コストを抑えることが可能です。 -
クエリ頻度が高く、詳細なカスタマイズが必要な場合
Amazon OpenSearch Serverlessを検討してください。高頻度のクエリ処理や柔軟なカスタマイズに対応できるため、パフォーマンスの最適化が図れます。 -
フルマネージドで簡単に利用したい場合
Amazon Kendraの利用をおすすめします。エンベディングの設定などを自分で行う必要がなく、手軽に高度な検索機能を実装できます。
今後は、言語モデルの違いやチャンクサイズがRAGの性能に与える影響など、より詳細な検証を進める予定です。
Discussion