「ぴよログ」の育児記録を Grafana で可視化してみた
こんにちは、ソフトウェアエンジニア兼、一児のパパ @konnyaku256 です。
我が家では育児記録に「ぴよログ」というスマホアプリを使っているのですが、そのデータが 3 か月分ほど溜まってきて分析の機運が高まったので、Grafana でデータ分析用のダッシュボード「piyolog-analytics」を作ってみました。
これまでなんとなく記録していたデータも、集計してグラフにすることで、成長の傾向を数値化・可視化できて、育児に対するモチベーションが向上しました。
この記事では、そんな piyolog-analytics をどのように実装・構築したのか紹介したいと思います。
ソースコードは GitHub で公開しています。
気に入ったら Star いただけると嬉しいです。
piyolog-analytics の技術スタック
-
Grafana Cloud
- Grafana による分析ダッシュボード
-
PlanetScale
- Grafana のデータソース(MySQL)
-
Google Drive
- ぴよログからエクスポートしたデータの一時的な格納先
-
Python
- ぴよログからエクスポートしたデータの加工・DB への登録スクリプト
-
GitHub Actions
- 上記 Python スクリプトの定期実行
分析の流れ
piyolog-analytics では次の流れに沿って「ぴよログ」の育児記録を分析します。
- 毎日 12:00 までに「ぴよログ」アプリから前日のデータをエクスポートする
エクスポートしたデータは Google Drive にテキストファイルとして保存する
※この操作は自動化できないため、毎日手動で実行する必要がある - Google Drive 上の前日のデータをエクスポートしたテキストファイルからデータを加工して PlanetScale(MySQL)に登録する Python スクリプトを実行する
※このスクリプトは GitHub Actions で毎日 12:00 に実行する - Grafana から PlanetScale(MySQL)に接続してデータを分析する
1.「ぴよログ」の育児記録を加工・DB に登録する Python スクリプトの作成
「ぴよログ」の育児記録をパース・加工する部分
この処理は先駆者の方々の例を参考に実装しました。
「ぴよログ」のエクスポートデータの形式は「1 日分のエクスポート(テキスト)」と「1 か月分のエクスポート(テキスト)」の 2 種類が存在するため、どちらの形式でもパースできるように、DATA_TYPE で処理を分岐させています。
「1 日分のエクスポート(テキスト)」の例
【ぴよログ】2023/2/1(水)
ぴよ子 (0歳3か月1日)
00:05 起きる (2時間25分)
00:05 ミルク 110ml
00:35 寝る
03:15 起きる (2時間40分)
03:15 ミルク 120ml
03:40 おしっこ
04:00 寝る
...略...
「1 か月分のエクスポート(テキスト)」の例
【ぴよログ】2023年1月
----------
2023/1/1(日)
ぴよ子 (0歳2か月1日)
00:05 起きる (1時間5分)
00:10 おしっこ
00:10 うんち (多め/かため)
00:30 母乳 左5分
...略...
----------
2023/1/2(月)
ぴよ子 (0歳2か月2日)
04:05 起きる (4時間15分)
04:10 母乳 左5分 ▶ 右2分
...略...
後述する pandas の to_sql 関数でテーブルに INSERT する場合、 DataFrame と テーブルのカラム名は一致している必要があるため、CN_* 系の定数で指定するカラム名を定義しています。
DB に登録する部分
pandas の to_sql 関数 と SQLAlchemy を使って、pandas の DataFrame から テーブルに INSERT するようにしました。
今回採用した PlanetScale では「SSL で接続することが必須」のため connect_args の ssl_ca キーで自己署名証明書のファイルパスを指定しています。
2. PlanetScale で MySQL の構築
PlanetScale とはサーバーレスなフルマージド MySQL を提供しているクラウドサービスです。
スケーラブルな MySQL をお手軽に手に入れることができます。
piyolog-analytics における PlanetScale は、1 で作成した Python スクリプトによって加工された育児記録の INSERT を受け付けます。
PlanetScale で新しいデータベースの作成が完了したら、Web Console から次のような SQL を実行して、データ格納用のテーブルを作成します。
3. Grafana で分析ダッシュボードの作成
Grafana とは Grafana Labs 社が開発したデータ可視化ツールです。
時系列データの可視化に優れており、様々な種類のデータソースと接続して、GUI でダッシュボードを構築できる点が魅力的です。
piyolog-analytics では Grafana 公式のクラウドサービスである Grafana Cloud を使って、次のようなダッシュボードを作成しました。
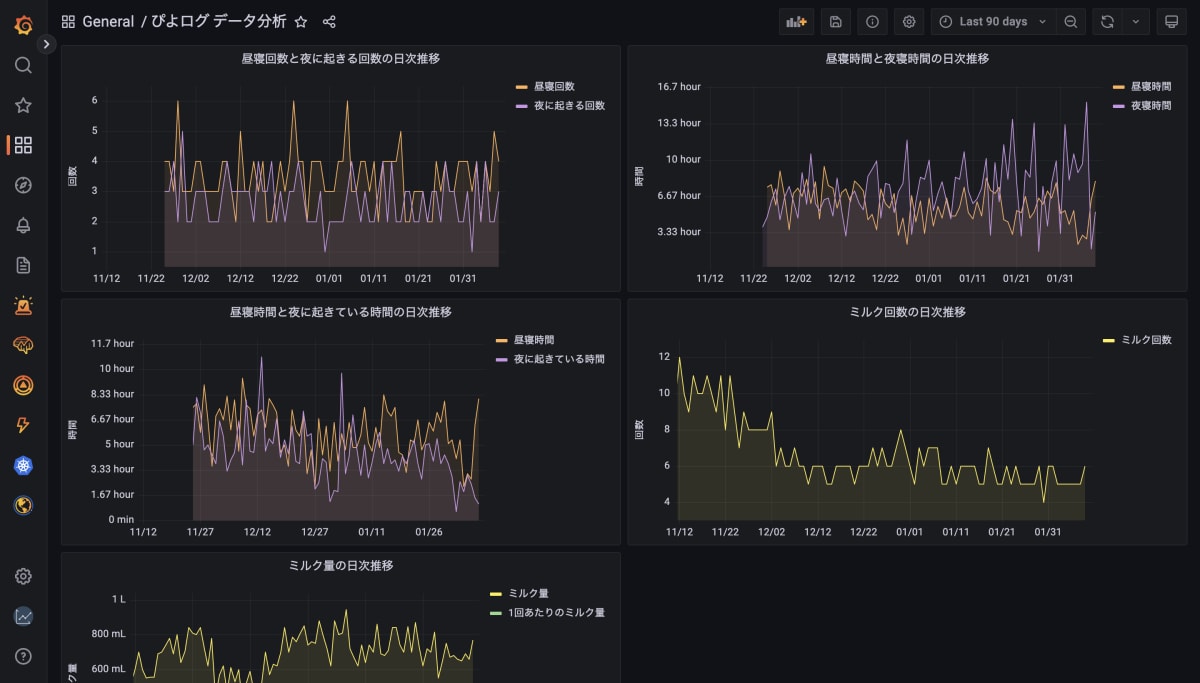
Grafana Cloud には無料プランがあり、個人で使う場合に重宝します。
データソースとして、MySQL を選択し、2 で構築した MySQL と接続しました。
1 の「DB に登録する部分」でも述べたように、PlanetScale では「SSL で接続することが必須」のため、MySQL Connection の TLS Client Auth をオンにして、自己署名証明書ファイルの内容を設定しました。
ダッシュボードの設定は JSON model と呼ばれる次のような json ファイルで管理できます。
4. GitHub Actions で Python スクリプトの定期実行
最後に、GitHub Actions で Python スクリプトを定期実行するように設定しました。
on > schedule > cron で毎日 12:00(JST)に実行するようにしています。
この Actions では「ぴよログ」からエクスポートしたテキストファイルが Google Drive にアップロードされていることを前提としており、Google Drive API のラッパーコマンドである skicka を使用して、指定したテキストファイルを Actions のランナーにダウンロードしています。
例えば、Google Drive 上の piyolog-analytics/daily/20230201.txt を Actions 上の ${{ github.workspace }}/data/daily/ 下にダウンロードします。
skicka の利用開始に必要な初期設定は satackey/action-google-drive@v1 の Get ready を参考に行いました。
おわりに
いかがでしたか?
このように、piyolog-analytics は Grafana と MySQL(PlanetScale)、Python、GitHub Actions などの技術を活用して開発しました。
この手のデータは加工して可視化するだけなら、Jupyter Notebook などを使うだけでも良いですが、グラフを編集するためにコードを書いたり、分析のたびにデータを用意してスクリプトを実行したりする手間が発生してしまいます。
そこで、piyolog-analytics では Grafana を使うことで、グラフの編集を GUI だけで実現し、GitHub Actions を使うことでデータ加工などを行うスクリプトを定期的に実行するようにしました。
「ぴよログ」の育児記録を可視化してみたい方の参考になれば幸いです。
Discussion